Java集合框架整理
声明:此系列文章整理自陈树义;
集合系列开篇:为什么要学集合?
集合可以说是学习 Java 中最重要的一块知识点了,无论做任何业务系统,集合总是最为基础的那块 API。我第一次接触集合,是在我大三的时候,那时候去面试,面试官问我:你了解过集合吗?可惜那时候没什么项目经验,所以基本没有了解过,因此也错失了机会。
到了现在,我已经工作了5年了,也做过了大大小小十几个项目。这些项目中有简单的 SSH 项目,也有分布式高并发的复杂项目。无论在哪个项目中,关于集合的时候是必不可少的。但我现在慢慢回顾过去做的项目,我发现自己使用到的集合还是比较少,基本上只有:ArrayList、HashSet、HashMap 这几个。
但当我开始深入去了解 JDK 集合的整个体系时,我发现之前的我了解得确实非常浅显。例如关于 List 的实现有 ArrayList、LinkedList、Vector、Stack 这四种实现,但我们很多时候只是直接使用 ArrayList,而不是根据场景去选择。
1.学习集合源码,能够让我们使用得更加准确。
当我们深入学习了源码之后,我们就能够了解其特性,从而能够根据我们的使用场景去做出更好的选择,从而让我们的代码运行效率更高。
我们举一个最简单的例子 —— ArrayList 和 LinkedList。它们两者底层采用了完全不同的实现方式,ArrayList 使用数组实现,而 LinkedList 则使用链表实现。这使得 ArrayList 的读取效率高,而 LinkedList 的读取效率低。但因为 LinkedList 采用链表实现,所以其增加和删除比较方便,而 ArrayList 则比较麻烦。所以 ArrayList 比较适合用于读场合较多的情况,而 LinkedList 比较适合用于增加、删除较多的场景。
我们来看另外一个例子 —— HashMap 和 TreeMap。乍看之下,他们都是 Map 集合的实现,但是它们内部有着截然不同的实现。HashMap 是 Map 接口的哈希实现,其内部使用了链表和红黑树实现。而 TreeMap 是 Map 接口的有序实现,其内部使用了红黑树实现。所以 HashMap 一般用来存储 key、value 的实现,而 TreeMap 常用存储需要排序的元素。
除了我们举的这两个例子之外,还有许多这样的例子,比如:HashMap 与 LinkedHashMap 的区别,HashMap 与 WeakHashMap 的区别,LinkedList 与 ArrayDeque 的区别。
2.学习集合源码,让我们学习经典的设计方式。
在集合的整个架构设计中,其类继承体系非常简单,但是却很经典。例如:Collection 接口设计了集合通用的操作,每个集合类型都有对应的接口(List、Set、Map),每个集合类型都有对应的抽象实现(AbstractList、AbstractSet、AbstractMap)等。
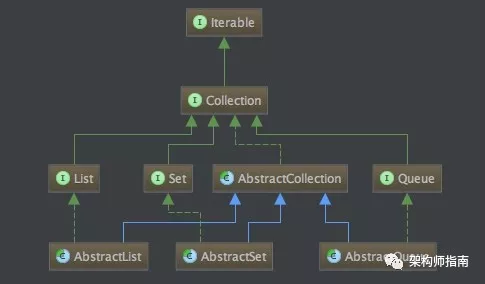
当我们阅读这些源码的时候,这种设计方式都会潜移默化地影响我们。当我们之后自己设计一个框架的时候,我们就会不知不觉地用上去。所有的创新都是从模仿开始的,所以阅读优秀的集合源码很重要。
3.帮助通过面试,获得更高的薪酬。
现在关于集合的原理是 Java 工程师面试的家常菜,几乎每一个企业的面试都会问到。如果你连这块东西都没搞清楚,那么你就不需要聊其他了,直接被干掉。而如果你能将整个 Java 集合体系清晰地说出去,并且举一反三地对比,那么你就比其他人优秀了。
4.学习经典的数据结构。
还记得大学在学习数据结构的时候,我们都是从理论上去记忆。但是当我看完集合源码之后,我忽然发现——JDK集合源码简直就是数据结构的最佳实践呀!
数据结构中最为基础的几个结构为:顺序表、单链表、双向链表、队列、栈、二叉堆、红黑树、哈希表。这些所有的实现都能在 JDK 集合的实现中找到。例如:ArrayList 就是顺序表的实现,LinkedList 就是双向链表的实现,Stack 就是栈的实现,HashMap 就是哈希表的实现,TreeMap 就是红黑树的实现,PriorityQueue 就是二叉堆的实现。
5.所有技术的基础
集合源码可以说是 JDK 所有源码中最为简单的一块了,而且也是其他所有源码的基础。例如线程池的源码中也大量使用了阻塞队列,如果你连集合源码都搞不懂,那么线程池的源码你也肯定看不懂的。而如果线程池源码看不懂,那么你 netty 的源码也看不懂的。netty 源码看不懂,那么 dubbo 的源码也是看不懂的。
看明白了么?这些技术都是一换扣着一换的。如果你想要后续学习更加快速,那么你就必须把最基础的东西学明白了。如果连最基础的东西都没学明白,就直接去学其他更复杂的东西,最后只会越来越难,最终逃脱不了放弃的命运。
读到了这里,我相信你也对集合的重要性有了不一样的认识。那么接下来一段时间,就让我和你一起来深入学学集合源码吧。如果觉得读了有用,那么请给我一个赞吧。你们的赞是我继续写下去的动力!
集合系列(一):集合框架概述
Java 集合是 Java API 用得最频繁的一类,了解其及继承结构,掌握其实现原理非常有必要。总的来说,Java 容器可以划分为 4 个部分:
-
List 集合
-
Set 集合
-
Queue 集合
-
Map 集合
除了上面 4 种集合之外,还有一个专门的工具类:
-
工具类(Iterator 迭代器、Enumeration 枚举类、Arrays 和 Collections)
在开始聊具体的集合体系之前,我想先介绍一下 Collection 框架的基本类结构。因为无论是 List 集合、Set 集合还是 Map 集合都以这个为基础。
-
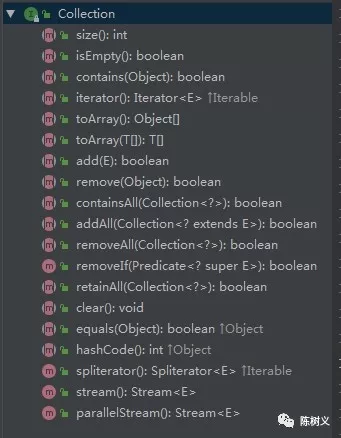
首先,最顶层的是 Collection 接口。
可以看到 Collection 接口定义了最最基本的集合操作,例如:判断集合大小、判断集合是否为空等。List、Set、Queue 都继承了该接口。
-
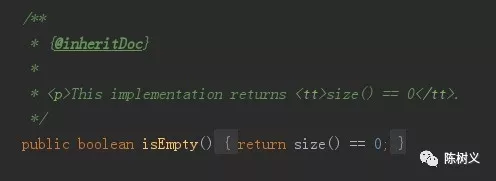
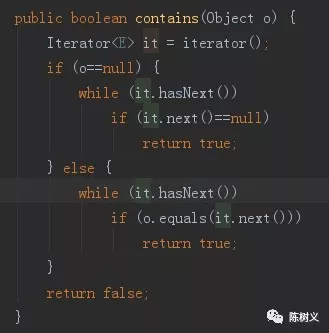
接着,AbstractCollection 也继承了 Collection 接口。
从这个类名可以看出,其是一个抽象类。AbstractCollection 对 Collection 接口中一些通用的方法做了实现。例如:判断是否为空的方法、判断是否包含某个元素的方法等。
通过继承 AbstractCollection 接口,可以少写许多不必要的代码,这是代码抽象设计最常用的思想。AbstractCollection 是最为基础的类,其他所有集合的实现都继承了这个抽象类。
List 集合
List 集合存储的是有序的数据集合,其数据结构特点是:读取快,修改慢,适合于读取多、写入修改少的场景。List 集合的类继承结构如下:
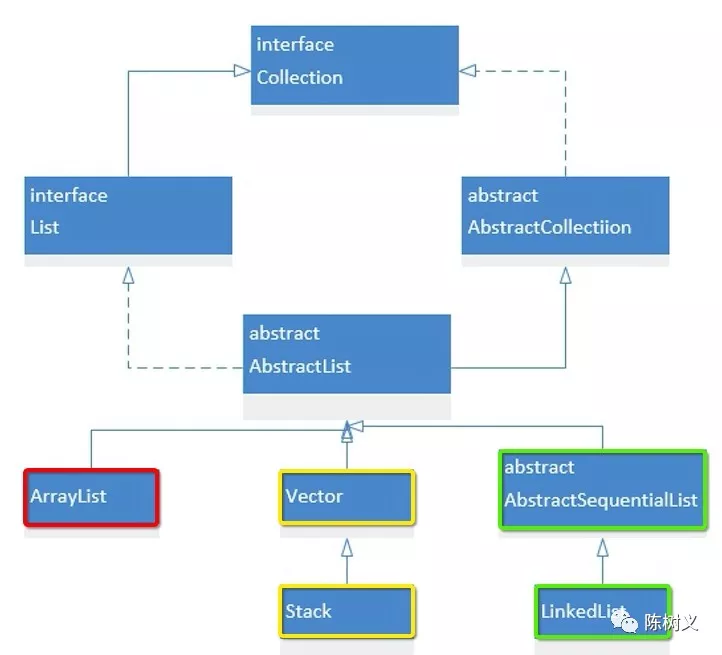
我们可以看到除了 Collection 和 AbstractCollection 之外,我们还有 List 接口和 AbstractList 抽象类。其中 List 接口是 List 集合的最上层抽象,其继承了 Collection 接口,表示其实一个集合。而 AbstractList 则是 List 集合的抽象实现,实现了许多公用的操作。
整个 List 集合的实现可以分为红、黄、绿三大块。其中红色部分是 List 集合的列表实现,绿色部分是 List 结合的链表实现,而 黄色部分则是 List 集合列表实现的线程安全版本。
列表实现
ArrayList 类是很常用的 List 实现,其底层是用数组实现的。其读取元素的时间复杂度是 O(1),修改写入元素的时间复杂度是 O(N)。我们将会在下面的章节中详细介绍,这里不做深入。
列表安全实现
Vector 类也是很常用的 List 实现,其数据结构与 ArrayList 非常类似。但其与 ArrayList 的一个最大的不同是:Vector 是线程安全的,而 ArrayList 则不是线程安全的。
Stack 类则是在 Vector 的基础上,又实现了一个双向队列。所以其除了是线程安全的之外,其还是一个先进后出的 List 实现。
最后我们总结一下,List 集合最为关键的几个实现类是:
-
ArrayList:列表集合经典实现。
-
Vector:列表集合经典实现,线程安全,与 ArrayList 对应。
-
Stack:栈结构的经典实现,先进后出的数据结构。继承了 Vector,线程安全。
-
LinkedList:链表结构的经典实现。
链表实现
LinkedList 是一个经典的链表实现。LinkedList 继承了 AbstractSequentialList 抽象类。AbstractSequentialList 抽象类从字面上理解是抽象连续列表。这里的重点是 sequential 这个词,表示其数据结构是连续的(链表)。从其源码注释也可以看出这个意思。
This class provides a skeletal implementation of the List interface to minimize the effort required to implement this interface backed by a "sequential access" data store (such as a linked list). (意译)如果你想要实现一个连续存储(链表)的 List,那么这个抽象类可以让你减少不少工作量。
其实从命名就可以看出,AbstractSequentialList 其实是连续列表(链表)的一个抽象实现。AbstractSequentialList 抽象类做了许多工作,使得后续的链表实现更加简单。从 AbstractSequentialList 的注释可以看到,如果要实现一个链表,那么只需要实现 listIterator 方法和 size 方法就可以了。
![]()
Set 集合
Set 集合中存储的元素是不重复的,但是其存储顺序是无序的。下面是 Set 集合的类继承结构图:
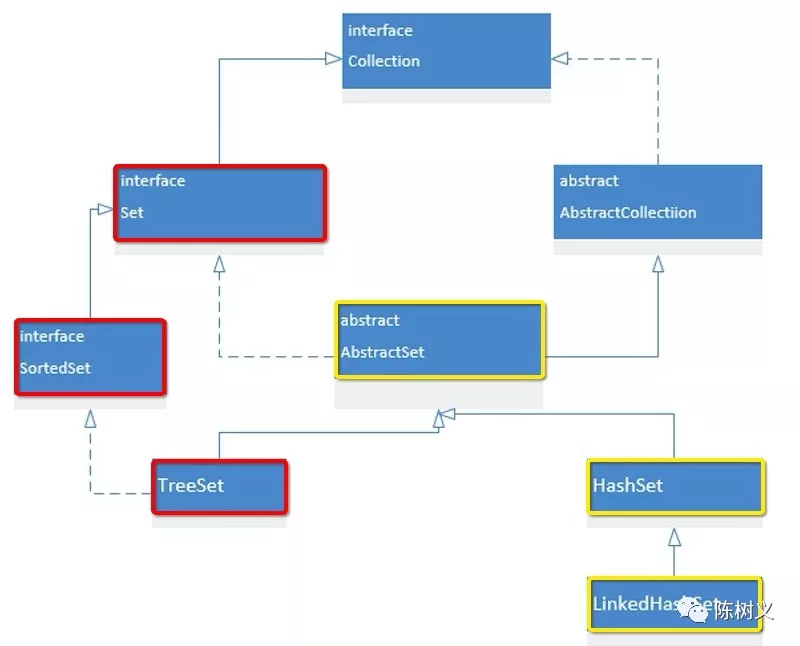
与 List 集合类似,都是一个 Set 接口继承了 Collection 接口。一个 AbstractSet 抽象类实现了 Set 接口、继承了 AbstractCollection 抽象类。这部分完全和 List 相同。
Set 集合的实现可以分为两大块,一块是 Set 集合的有序实现(红色部分),另一块是 Set 集合的哈希实现(黄色部分)。
有序实现(TreeSet)
-
SortedSet 接口继承了 Set 接口,TreeSet 实现了 SortedSet。
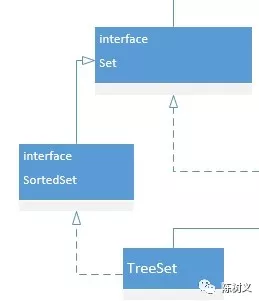
我们知道 Set 集合中的元素是无序的,而 SortedSet 接口则是定义了有序 Set 集合的接口。而 TreeSet 则是 SortedSet 的具体实现。
哈希实现(HashSet、LinkedHashSet)
HashSet 是 Set 接口的经典哈希实现。但 Set 集合中的元素是无序的,为了维护 Set 集合的插入顺序,人们创造出了 LinkedHashSet。LinkedHashSet 是在 HashSet 的基础上用链表维护元素的插入顺序。
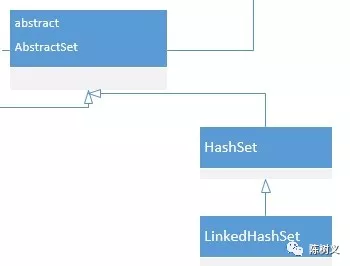
到这里我们总结一下 Set 集合的所有实现:
-
TreeSet:Set 集合的有序实现。
-
HashSet:Set 集合的哈希实现。
-
LinkedHashSet:Set 集合的哈希实现,维护了元素插入顺序。
Queue 集合
队列是一个特殊的线性表,其数据结构特点是先进先出。Queue 类结构体系如下图所示:
![]()
首先,Queue 接口继承了 Collection 接口。Queue 接口在拥有基本集合操作的基础上,定义了队列这种数据结构的基本操作。可以看到 offer、poll 等方法都是队列独有的操作。
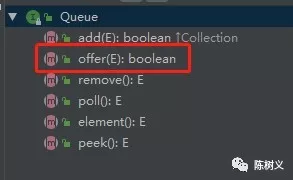
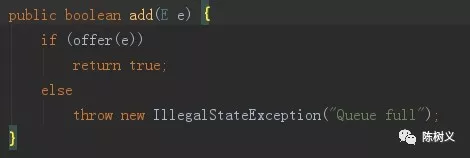
接着,AbstractQueue 是对 Queue 接口的抽象实现。针对队列这种数据结构,其添加、删除元素的动作都不一样。在 AbstractQueue 抽象类里将队列的基本操作都实现了一遍。例如 AbstractQueue 中的 add 方法就和 AbstractList 中的 add 方法有着不同的实现。
如上图所示,Queue 的类结构整体可以分为黄色、红色两个部分。红色部分是 Queue 接口的有序实现,有 PriorityQueue 这个实现类。黄色部分是 Deque(双向队列)的实现,有 LinkedList 和 ArrayDeque 两个实现类。
有序实现
PriorityQueue 是 AbstractQueue 抽象类的具体实现。
PriorityQueue 表示优先级队列,其按照队列元素的大小进行重新排序。当调用 peek() 或 pool() 方法取出队列中头部的元素时,并不是取出最先进入队列的元素,而是取出队列的最小元素。
双向实现
-
首先,我们会看到 Deque 接口。
Deque(double ended queue)是双向队列的意思,它能在头部或尾部进行元素操作。
-
最后,我们看到 LinkedList 和 ArrayDeque 都是 Deque 接口的具体实现。
LinkedList 我们之前说过了,是一个链表,但它还是一个双向队列。因此 LinkedList 具有 List 和 Queue 的双重特性。ArrayDeque 是一个双向循环队列,其底层是用数组实现。更多内容,我们将在队列章节讲解。
最后我们总结 Queue 体系的几个常见实现类:
-
PriorityQueue:优先级队列
-
LinkedList:双向队列实现
-
ArrayDeque:双向循环队列实现
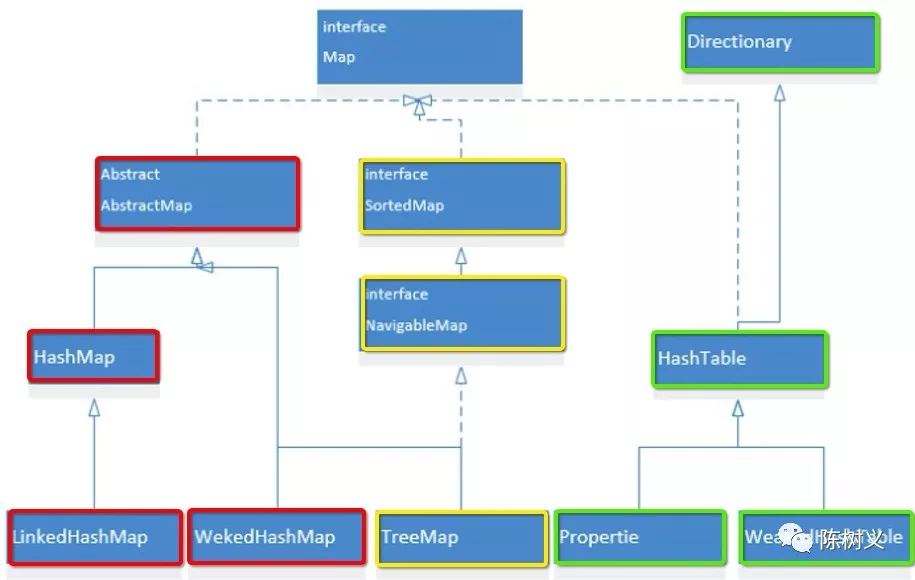
Map 集合
Map 集合与 List、Set、Queue 有较大不同,其实类似于 key/value 的数据结构。
-
首先,Map 接口是最顶层的接口。
与 List、Set、Queue 类似,Map 接口定义的是哈希表数据结构的操作。例如我们常用的 put、get、keySet 等。
-
接着,有 AbstractMap 抽象类。
和 List 等类似,AbstractMap 是 Map 接口的抽象实现。如上图所示,Map 集合的整个类结构可以分为红、黄、绿三块。
哈希实现
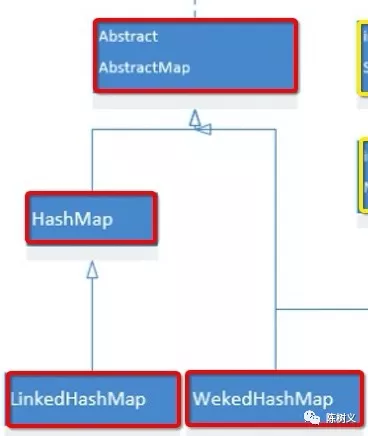
红色部分可以看成是 Map 的哈希实现。
-
AbstractMap 有具体的实现类 HashMap。
HashMap 是 AbstractMap 基于哈希算法的具体实现。
-
接着,LinkedHashMap 和 WeakedHashMap 继承了 HashMap。
LinkedHashMap 是 HashMap 的进一步实现,其用链表保存了插入 HashMap 中的元素顺序。WeakedHashMap 是 HashMap 的进一步实现,与 HashMap不同的是:WeakedHashMap 中的引用是弱引用,如果太久没用,则会被自动回收。
有序实现
黄色部分可以看成是 Map 集合的有序实现。
-
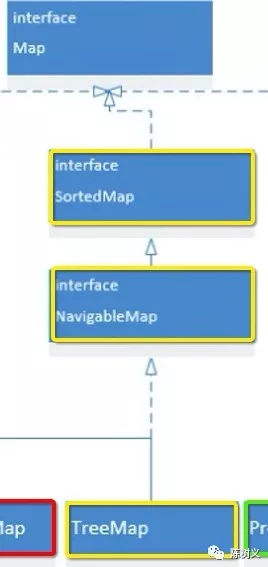
首先,SortedMap 接口继承了 Map 接口。
与 Set 一样,Map 中的元素是没有顺序的,SortedMap 就是有序 Map 的接口定义。
-
接着,NavigableMap 继承了 SortedMap 接口。
NavigableMap 接口定义了一些查找逻辑,方便后续实现。
-
最后,TreeMap 则是 NavigableMap 接口的具体实现。
其实 TreeMap 是基于红黑树的 Map 实现。
看到了这里,Map 整个类结构看完了一半。而另外一半则是以 Dictionary 为主的实现(绿色部分)。但实际上 Dictionary 是老旧的 Map 实现,现在已经废弃了。我们从源码的注释中可以看到相关的提示。
NOTE: This class is obsolete(废弃的). New implementations should implement the Map interface, rather than extending this class. 这个类已经被废弃,新的实现应该实现 Map 接口,而不是扩展这个类。
所以针对于 Dictionary 的实现,我们并不打算深入讲解。
到这里我们总结一下 Map 集合的所有实现类:
-
HashMap:Map 集合的经典哈希实现。
-
LinkedHashMap:在 HashMap 的基础上,增加了对插入元素的链表维护。
-
WeakedHashMap:在 HashMap 的基础上,使强引用变为弱引用。
-
TreeMap:Map 集合的有序实现。
工具类
集合的工具类有:Iterator 迭代器、ListIterator 迭代器、Enumeration 枚举类、Arrays 和 Collections 类。
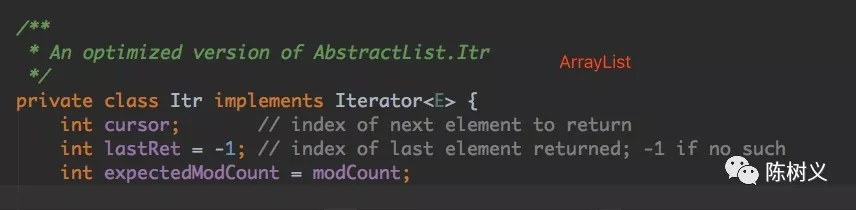
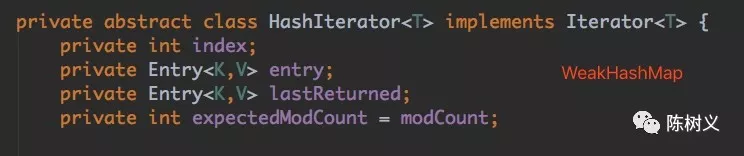
Iterator 迭代器
Iterator 迭代器是一个用来遍历并选择序列中的对象。Java 的 Iterator 只能单向移动。可以看到在 ArrayList、WeakHashMap 等集合类都实现了该接口,从而实现不同类型集合的遍历。
ListIterator 迭代器
ListIterator 继承了 Iterator 接口,所以其有更强大的功能,即它能够实现双向移动。但从其名字也可以看出,其只能适用于 List 集合的遍历。
Enumeration 枚举类
它是 JDK 1.0引入的接口。作用和Iterator一样,也是遍历集合。但是Enumeration的功能要比Iterator少。Enumeration只能在Hashtable, Vector, Stack中使用。这种传统接口已被迭代器取代,虽然 Enumeration 还未被遗弃,但在代码中已经被很少使用了。
官方也在文档中推荐使用 Iterator 接口来替代 Enumeration 接口。

Arrays
Java.util.Arrays类能方便地操作数组,它提供的所有方法都是静态的。
Collections
java.util.Collections 是一个包含各种有关集合操作的静态多态方法的工具类,服务于 Java 的 Collection 框架。
总结
我们花费了大量的篇幅讲解了 List 集合、Set 集合、Map 集合、Queue 集合以及 Iterator 等工具类。我们对这集合的类结构进行了详细的解析,从而更加了解他们之间的关系。
有时候我们会想,了解这么多有啥用呢。我有个朋友只用了常见的 ArrayList、HashMap 就可以了啊。对于这个问题,我想分享几个收获。
第一,让你更加熟悉类之间的差异。 如果我们只会用一两个类,那么我们就不知道在什么时候用什么类。例如:什么时候用 HashMap,什么时候用 Hashtable?Iterator 接口有什么作用?JDK源码的命名有什么特点?
第二,方便对源码进行扩展。 当我们深入研究了集合的实现之后,我们知道了原来 List 接口就是 List 这种数据类型的定义,而 AbstractList 是 List 的抽象实现。那么如果我们要实现一个自定义的 List 结构,那么我们就可以直接继承 AbstractList 类,从而达到快速实现的目的。但如果你没有深入研究呢?你或许只能从头写起,这样得浪费多大的精力啊。你学会了这种方式,那么对于你扩展 Spring 源码也是有很好的帮助的。
在接下来的文章里,我们将深入介绍每一个集合的具体实现。
集合系列 List(二):ArrayList
ArrayList 是 List 集合的列表经典实现,其底层采用定长数组实现,可以根据集合大小进行自动扩容。
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
原理
为了深入理解 ArrayList 的原理,我们将从类成员变量、构造方法、核心方法两个方面逐一介绍。
类成员变量
// 默认初始化大小
private static final int DEFAULT_CAPACITY = 10;
// 空列表数据。初始化时如果没有指定大小,则将此值赋予elementData
private static final Object[] EMPTY_ELEMENTDATA = {};
// 默认空列表数据。如果没有指定大小,那么将此值赋予elementData
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 列表数据
transient Object[] elementData;
// 列表大小
private int size;
构造方法
ArrayList 一共有 3 个构造方法:
// 空构造方法
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 指定大小
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 指定初始集合
public ArrayList(Collection c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
从第一个构造方法可以看到,如果没有指定大小,那么就将 elementData 赋值为 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。而从第二个构造方法可以看到,如果指定了大小为 0,那么就将 elementData 赋值为 EMPTY_ELEMENTDATA。
核心方法
在 ArrayList 中最为核心的是获取、插入、删除、扩容这几个方法。
获取
获取的源码非常简单,只需对 index 做有效性校验。如果参数合法,那么直接返回对应数组下标的数据。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
插入
插入一共有两种实现方式,第一种是直接插入列表尾部,另一种是插入某个位置。
// 直接插入尾部
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 插入某个位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
如果是直接插入尾部的话,那么只需调用 ensureCapacityInternal 方法做容量检测。如果空间足够,那么就插入,空间不够就扩容后插入。
![]()
如果是插入的是某个位置,那么就需要将 index 之后的所有元素后移一位,之后再将元素插入至 index 处。
![]()
删除
ArrayList 的删除方法有两个,分别是:
-
删除某个位置的元素:remove(int index)
-
删除某个具体的元素:remove(Object o)
我们先来看第一个删除方法:删除某个位置的元素。
// 删除某个位置的元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
上述代码的逻辑大致是这样的:首先做参数范围检查,接着将 index 位置后的所有元素都往前挪一位,最后减少列表大小。
我们继续看第二个删除方法:删除某个特定的元素。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
上述代码的逻辑大致是:首先,遍历列表的所有元素,找到需要删除的元素索引,最后调用 fastRemove 方法删除该元素。我们继续看看 fastRemove 方法的实现。
/*
* 用私有的方法 fastRemove 方法跳过边界检查,不返回删除值。
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
这里会有一个疑问,那就是为什么不直接复用 remove(int index) 方法,而要新写一个方法呢?答案在 fastRemove 方法的注释中已经写了,就是为了跳过边界检查,提高效率。
扩容
扩容是 ArrayList 的核心方法,当插入的时候容量不足,便会触发扩容。我们可以看到在插入的两个方法中都调用了扩容方法——ensureCapacityInternal。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
ensureCapacityInternal 方法直接调用 ensureExplicitCapacity 实现。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
ensureExplicitCapacity 方法首先判断容量是否足够,如果不够就调用 grow 方法扩容。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
grow 方法的大致逻辑为:将原有列表容量扩大为原来的 1.5 倍。如果还是不够,那么直接扩大为最小容量(minCapacity)。
总结
经过上面的分析,我们可以知道 ArrayList 有如下特点:
-
底层基于数组实现,读取速度快,修改速度慢(读取时间复杂度O(1),修改时间复杂度O(N))。
-
非线程安全。
-
ArrayList 每次默认扩容为原来的 1.5 倍。
集合系列 List(三):Vector
Vector 的底层实现以及结构与 ArrayList 完全相同,只是在某一些细节上会有所不同。这些细节主要有:
-
线程安全
-
扩容大小
线程安全
我们知道 ArrayList 是线程不安全的,只能在单线程环境下使用。而 Vector 则是线程安全的,那么其实怎么实现的呢?
其实 Vector 的实现很简单,就是在每一个可能发生线程安全的方法加上 synchronized 关键字。这样就使得任何时候只有一个线程能够进行读写,这样就保证了线程安全。
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
扩容大小
与 ArrayList 类似,Vector 在插入元素时也会检查容量并扩容。在 Vector 中这个方法是:ensureCapacityHelper。
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
其实上述扩容的思路与 ArrayList 是相同,唯一的区别是 Vector 的扩容大小。
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
从上面的代码可以看到:如果 capacityIncrement 大于 0,那么就按照 capacityIncrement 去扩容,否则扩大为原来的 2倍。而 ArrayList 则是扩大为原来的 1.5 倍。
总结
Vector 与 ArrayList 在实现方式上是完全一致的,但是它们在某些方法有些许不同:
-
第一,Vector 是线程安全的,而 ArrayList 是线程不安全的。Vector 直接使用 synchronize 关键字实现同步。
-
第二,Vector 默认扩容为原来的 2 被,而 ArrayList 默认扩容为原来的 1.5 倍
集合系列 List(四):LinkedList
LinkedList 是链表的经典实现,其底层采用链表节点的方式实现。
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
从类继承结构图可以看到,LinkedList 不仅实现了 List 接口,还实现了 Deque 双向队列接口。
原理
为了深入理解 LinkedList 的原理,我们将从类成员变量、构造方法、核心方法两个方面逐一介绍。
类成员变量
// 链表大小
transient int size = 0;
// 首节点
transient Node first;
// 尾节点
transient Node last;
// Node节点
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
其采用了链表节点的方式实现,并且每个节点都有前驱和后继节点。
构造方法
LinkedList 总共有 2 个构造方法:
public LinkedList() {
}
public LinkedList(Collection c) {
this();
addAll(c);
}
构造方法比较简单,这里不深入介绍。
核心方法
在 LinkedList 中最为核心的是查找、插入、删除、扩容这几个方法。
查找
LinkedList 底层基于链表结构,无法向 ArrayList 那样随机访问指定位置的元素。LinkedList 查找过程要稍麻烦一些,需要从链表头结点(或尾节点)向后查找,时间复杂度为 O(N)。相关源码如下:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node node(int index) {
/*
* 如果获取的元素小于容量的一般,则从头结点开始查找,否则从尾节点开始查找。
*/
if (index < (size >> 1)) {
Node x = first;
// 循环向后查找,直至 i == index
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
上面的代码比较简单,主要是通过遍历的方式定位目标位置的节点。获取到节点后,取出节点存储的值返回即可。这里面有个小优化,即通过比较 index 与节点数量 size/2 的大小,决定从头结点还是尾节点进行查找。
插入
LinkedList 除了实现了 List 接口相关方法,还实现了 Deque 接口的很多方法,例如:addFirst、addLast、offerFirst、offerLast 等。但这些方法的实现思路大致都是一样的,所以我只讲 add 方法的实现。
add 方法有两个方法,一个是直接插入队尾,一个是插入指定位置。
我们先来看第一个add方法:直接插入队列。
public boolean add(E e) {
linkLast(e);
return true;
}
可以看到其直接调用了 linkLast 方法,其实它就是 Deque 接口的一个方法。
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
上述代码进行了节点的创建以及引用的变化,最后增加链表的大小。
我们继续看第二个add方法:插入指定位置。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
如果我们插入的位置还是链表尾部,那么还是会调用 linkLast 方法。否则调用 node 方法取出插入位置的节点,否则调用 linkBefore 方法插入。
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
上述代码进行了节点的创建以及引用的变化,最后增加链表的大小。
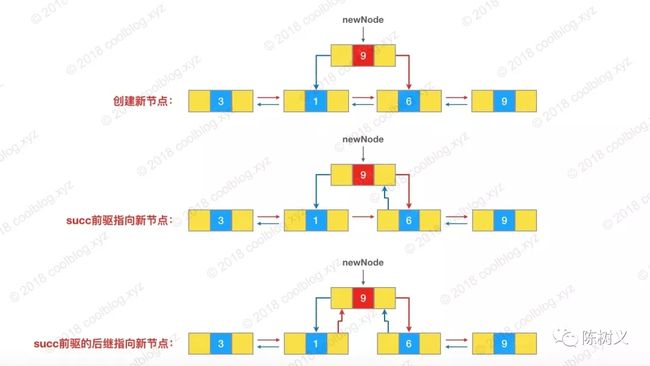
删除
删除节点有两个方法,第一个是移除特定的元素,第二个是移除某个位置的元素。
我们先看第一个删除方法:移除特定的元素。
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
上述代码的大致思路为:遍历找到删除的节点,之后调用 unlink() 方法解除引用。我们继续看看 unlink() 方法的代码。
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
unlink() 代码里就是做了一系列的引用修改操作。下面的步骤图非常详细地解释了整个删除过程。
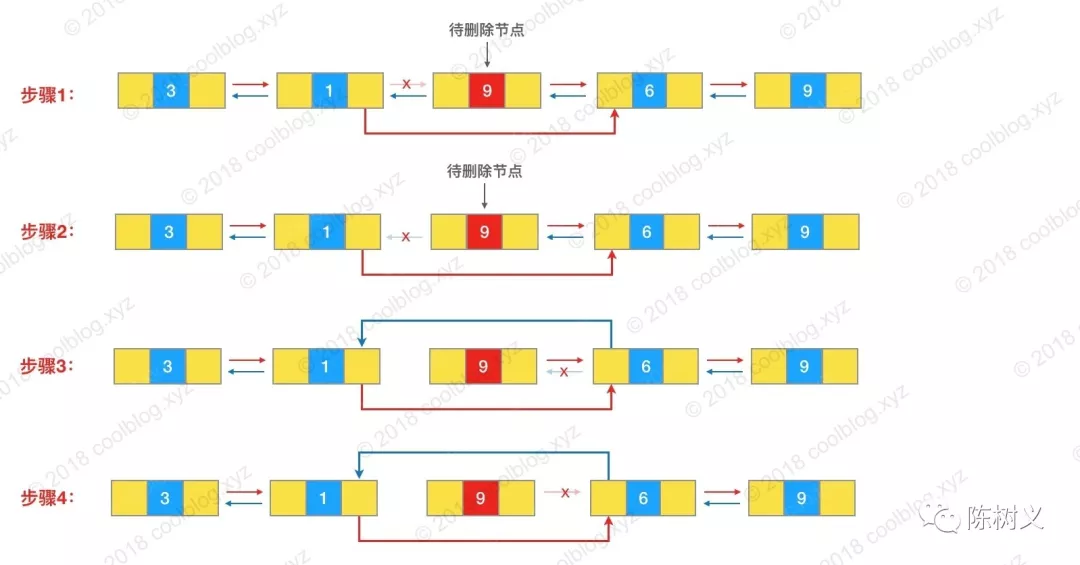
本文部分图片来源于田小波的博客
总结
经过上面的分析,我们可以知道 LinkedList 有如下特点:
-
底层基于链表实现,修改速度快,读取速度慢(读取时间复杂度O(N),修改时间复杂度O(N),因为要查找元素,所以修改也是O(N))。
-
非线程安全。
-
与 ArrayList 不同,LinkedList 没有容量限制,所以也没有扩容机制。
集合系列 List(五):Stack
Stack 是先进后出的栈结构,其并不直接实现具体的逻辑,而是通过继承 Vector 类,调用 Vector 类的方法实现。
public
class Stack extends Vector
核心方法
Stack 类代码非常简单,其有 3 个核心方法:push、pop、peek。
push
public E push(E item) {
addElement(item);
return item;
}
可以看到 push 方法直接调用 Vector 的 addElement 方法将元素插入数组尾部。
pop
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
pop 方法调用 Vector 的 removeElementAt 方法,删除了一个元素。要注意的是,其删除的是数组最后一个元素,而不是第一个元素。
peek
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
peek 方法直接返回列表最后一个元素。
总结
Stack 方法代码真的是非常简单,其利用 Vector 实现了一个线程安全的栈结构。总的来说,其有以下特点:
-
底层采用 Vector 实现,因此其也是采用数组实现,也是线程安全的。
-
先进后出的栈结构
集合系列 Set(六):HashSet
HashSet 是 Set 集合的哈希实现,其继承了 AbstractSet 抽象类,并实现了 Set 接口。
public class HashSet
extends AbstractSet
implements Set, Cloneable, java.io.Serializable
原理
为了深入理解 HashSet 的原理,我们将从类成员变量、构造方法、核心方法两个方面逐一介绍。
类成员变量
// HashSet内部使用HashMap存储
private transient HashMap map;
// 存储在value上的值
private static final Object PRESENT = new Object();
从类成员变量我们可以知道,HashSet 内部使用 HashMap 存储,而 PRESENT 则是存储在所有 key 上的 value。因此对于 HashSet 来说,其所有 key 的 value 都相同。
构造方法
HashSet 一共有 5 个构造方法。
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
可以看到构造方法传入的参数其实就是用于初始化 HashMap 对象,主要有:initialCapacity(初始大小)、loadFactor(扩容因子)。这几个构造参数内容并不复杂,这里就不细讲了。
这里有一个关键的细节,即第 5 个方法使用 LinkedHashMap 实现的,而不是用 HashMap 实现的。而我们后面要讲到的 LinkedHashSet 其实就是使用 LinkedHashMap 实现的,其保存了插入元素的顺序。
核心方法
对于 HashSet 来说,其核心的方法有:add、remove。
我们先看 add 方法。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可以看到 add 方法直接调用了 HashMap 对象的 put 方法。如果 Set 集合插入成功,那么就返回 true,否则返回 false。
接着我们看看 remove 方法。
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
可以看到 remove 方法直接调用了 HashMap 对象的 remove 方法。如果删除成功,就返回 true,否则返回 false。
总结
HashSet 的源码也是非常简单了,其直接借用了 HashMap 的实现。所以如果你弄懂了 HashMap,那么 HashSet 自然不在话下了。
集合系列 Set(七):LinkedHashSet
LinkedHashSet 继承了 HashSet,在此基础上维护了元素的插入顺序。
public class LinkedHashSet
extends HashSet
implements Set, Cloneable, java.io.Serializable
原理
LinkedHashSet 的源码非常简单,只有简单的 4 个构造方法。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
但我们不是说 HashSet 还维护了元素的插入顺序么?那这部分代码写在哪里呢?
这里我们要注意一个细节,即 LinkedHashSet 调用的都是 HashSet 的三个参数构造方法,即 HashSet 的这个方法。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
从上面的代码我们知道,LinkedHashSet 虽然继承的是 HashSet,但是其却使用 LinkedHashMap 做为实现类。而 LinkedHashMap 则本身维护了元素的插入顺序,这在我们接下来解析 LinkedHashMap 源码的时候会讲到。
总结
LinkedHashSet 是在 HashSet 的基础上,维护了元素的插入顺序。虽然 LinkedHashSet 使用了 HashSet 的实现,但其却调用了 LinkedHashMap 作为最终实现,从而实现了对插入元素顺序的维护。
集合系列 Set(八):TreeSet
TreeSet 是 Set 集合的红黑树实现,但其内部并没有具体的逻辑,而是直接使用 TreeMap 对象实现。我们先来看看 TreeSet 的定义。
public class TreeSet extends AbstractSet
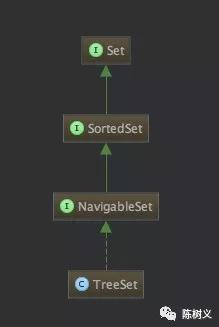
implements NavigableSet, Cloneable, java.io.Serializable
可以看到 TreeSet 实现了 NavigableSet 接口,而 NavigableSet 接口又继承了 接口。SortedSet 接口又继承了 Set 接口。
public interface NavigableSet extends SortedSet
public interface SortedSet extends Set
TreeSet 的类继承关系如下图所示。
原理
我们还是通过类成员变量、构造方法、核心方法来解析 TreeSet 的实现。
类成员变量
// 具体的实现类
private transient NavigableMap m;
// Map的value
private static final Object PRESENT = new Object();
构造方法
TreeSet 一共有 5 个构造方法,如下所示:
// 默认采用TreeMap实现
public TreeSet() {
this(new TreeMap());
}
// 指定实现类型
TreeSet(NavigableMap m) {
this.m = m;
}
// 指定TreeMap的比较器
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
}
// 指定初始集合
public TreeSet(Collection c) {
this();
addAll(c);
}
// 指定比较器以及初始集合
public TreeSet(SortedSet s) {
this(s.comparator());
addAll(s);
}
可以看到,如果我们没有指定传入的 Map 类型,TreeSet 将自动采用 TreeMap 来实现。而如果你传入了 NavigableMap 类型的对象,那么就按照你传入的对象类型来实现。
核心方法
TreeSet 的核心方法实现直接采用了 TreeMap 的实现,无论是 add 还是 remove 方法。
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
总结
TreeSet 的实现与 HashSet 类似,都是直接采用了 TreeMap 的方法实现。所以如果理解了 TreeMap,那么 TreeSet 就很简单了。同样的,我们将在 TreeMap 中深入讲解其实现。
集合系列 Queue(九):PriorityQueue
PriorityQueue 是一个优先级队列,其底层原理采用二叉堆实现。我们先来看看它的类声明:
public class PriorityQueue extends AbstractQueue
implements java.io.Serializable
PriorityQueue 继承了 AbstractQueue 抽象类,具有队列的基本特性。
二叉堆
由于 PriorityQueue 底层采用二叉堆来实现,所以我们有必要先介绍下二叉堆。
二叉堆从结构上来看其实就是一个完全二叉树或者近似完全二叉树。二叉堆的每个左子树和右子树都是一个二叉堆。当父节点总是大于或等于一个子节点的键值时称其为「最大堆」,当父节点总是小于或等于任何一个子节点的键值时称其为「最小堆」。
最小堆 最大堆
1 11
/ \ / \
2 3 9 10
/ \ / \ / \ / \
4 5 6 7 5 6 7 8
/ \ / \ / \ / \
8 9 10 11 1 2 3 4
在二叉堆上常见的操作有:插入、删除,我们下面将详细介绍这两种操作。
插入
在二叉堆上插入节点的思路为:在数组的末尾插入新节点,然后不断上浮与父节点比较,直到找到合适的位置,使当前子树符合二叉堆的性质。二叉堆的插入操作最坏情况下需要从叶子上移到根节点,所以其时间复杂度为 O(logN)。
例如我们有下面这个最小堆,当我们插入一个值为 6 的节点,其调整过程如下:
最小堆
1
/ \
5 7
/ \ / \
8 10 48 55
/ \ / \
11 9 15
-
在数组末尾插入新节点 6。
最小堆
1
/ \
5 7
/ \ / \
8 10 48 55
/ \ / \
11 9 15 6
-
做上浮操作不断与父节点比较,直到其大于等于父节点。首先,6 < 10,所以交换位置。
最小堆
1
/ \
5 7
/ \ / \
8 → 6 48 55
/ \ / \
11 9 15 10
-
继续与父节点比较,6 > 5 符合二叉树的性质,结束。
删除
二叉堆删除节点的思路为:
-
首先,如果删除的是末尾节点,那么直接删除即可,不需要调整。
-
接着,将删除节点与末尾节点交换数据,之后删除末尾节点,接着对删除节点不断做下沉操作。
-
最后,继续对删除节点做上浮操作。
例如我们有下面这个最小堆,当我们删除一个值为 7 的节点,其调整过程如下:
1
/ \
5 7
/ \ / \
8 10 48 55
/ \ / \ / \
11 9 15 16 50 52
-
首先,将删除节点与末尾节点交换数据,并删除末尾节点。
1
/ \
5 52
/ \ / \
8 10 48 55
/ \ / \ / \
11 9 15 16 50
-
接着,对删除节点(52)不断做下沉操作。首先比较 52 与 48 和 55 的大小,将 52 与 48 交换。接着比较 52 与 50 的大小,将 52 与 50 交换。结果为:
1
/ \
5 48
/ \ / \
8 10 50 55
/ \ / \ / \
11 9 15 16 52
-
最后,对删除节点(15)不断做上浮操作,结果为:
1
/ \
5 15
/ \ / \
8 10 48 55
/ \ / \
11 9
这里有一个细节,为什么做下沉操作之后,还需要做一次上浮操作呢?这是因为我们无法确定末尾节点的值与删除节点的父节点的大小关系。
在上面的例子中,我们删除的节点是 7,删除节点的父节点为1,末尾节点是 52。因为末尾节点和删除节点在同一个子树上,所以我们能够确定删除节点的父节点一定小于末尾节点,即 1 一定小于 52。所以我们不需要做上浮操作。
但是如果末尾节点与删除节点并不是在一颗子树上呢?此时我们无法判断末尾节点与删除节点父节点之间的大小关系,此时可能出现下面这种情况:
1
/ \
5 230
/ \ / \
8 10 240 255
/ \ / \ / \ / \
11 9 15 16 241 242 256 260
/ \
27 33
此时如果我们删除 255 节点,那么删除节点的父节点为 230,末尾节点为 33。此时末尾节点就小于删除节点的父节点,需要做上浮操作。
原理
了解完二叉树的插入、删除原理,我们再来看看 PriorityQueue 的源码就很简单了。
类成员变量
// 队列数据
transient Object[] queue;
// 大小
private int size = 0;
// 比较器
private final Comparator comparator;
从类成员变量我们可以知道 PriorityQueue 底层采用数组存储数据,comparator 的实现决定了其实一个最大堆还是最小堆。默认情况下 PriorityQueue 是个最小堆。
构造方法
PriorityQueue 一共有 7 个构造方法。
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity,
Comparator comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
// 传入集合初始值
public PriorityQueue(Collection c) {
if (c instanceof SortedSet) {
SortedSet ss = (SortedSet) c;
this.comparator = (Comparator) ss.comparator();
initElementsFromCollection(ss);
}
else if (c instanceof PriorityQueue) {
PriorityQueue pq = (PriorityQueue) c;
this.comparator = (Comparator) pq.comparator();
initFromPriorityQueue(pq);
}
else {
this.comparator = null;
initFromCollection(c);
}
}
// 传入PriorityQueue初始值
public PriorityQueue(PriorityQueue c) {
this.comparator = (Comparator) c.comparator();
initFromPriorityQueue(c);
}
// 传入SortedSet初始值
public PriorityQueue(SortedSet c) {
this.comparator = (Comparator) c.comparator();
initElementsFromCollection(c);
}
PriorityQueue 的构造方法比较多,但其功能都类似。如果传入的是普通集合,那么会将其数据复制,最后调用 heapify 方法进行二叉堆的初始化操作。但如果传入的数据是 SortedSet 或 PriorityQueue 这些已经有序的数据,那么就直接按照顺序复制数据即可。
核心方法
对于 PriorityQueue 来说,其核心方法有:获取、插入、删除、扩容。
获取
PriorityQueue 没有查询方法,取而代之的是获取数据的 peek 方法。
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
如果队列为空,那么返回 null 值,否则返回队列的第一个元素(即最大或最小值)。
插入
PriorityQueue 的数据插入过程,其实就是往二叉堆插入数据的过程。
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
// 1.容量不够,进行扩容
if (i >= queue.length)
grow(i + 1);
size = i + 1;
// 2.如果队列为空那么直接插入第一个节点
// 否则插入末尾节点后进行上浮操作
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
// 3.采用默认的比较器
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable key = (Comparable) x;
while (k > 0) {
// 4.将插入节点与父节点比较
// 如果插入节点大于等于父节点,那么说明符合最小堆性质
// 否则交换插入节点与父节点的值,一直到堆顶
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
插入的代码最终的逻辑是在 siftUpComparable 方法中,而该方法其实就是我们上面所说二叉堆插入逻辑的实现。
删除
PriorityQueue 的数据删除过程,其实就是将数据从二叉堆中删除的过程。
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
// 1.删除的是末尾节点,那么直接删除即可
if (s == i) // removed last element
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
// 2.对删除节点做下沉操作
siftDown(i, moved);
if (queue[i] == moved) {
// 3.queue[i] == moved 表示删除节点根本没下沉
// 意思是其就是该子树最小的节点
// 这种情况下就需要进行上浮操作
// 因为可能出现删除节点父节点大于删除节点的情况
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownComparable(int k, E x) {
Comparable key = (Comparable)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
PriorityQueue 的删除操作需要注意的点是其下沉之后,还需要根据条件做一次上浮操作。关于为什么要做上浮操作,上面讲解二叉堆的时候已经提到了。
offer
因为 PriorityQueue 是队列,所以有 offer 操作。
对于 offer 操作来说,其实就是相当于往数组未插入数据,其逻辑细节我们在插入 add 方法中已经说到。
poll
因为 PriorityQueue 是队列,同样会有 poll 操作。而 poll 操作其实就是弹出队列头结点,相当于删除头结点。
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
// 弹出头结点
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
// 做下沉操作
if (s != 0)
siftDown(0, x);
return result;
}
之前我们说过删除节点的逻辑,即拿末尾节点值替代删除节点,然后做下沉操作。但是这里因为删除节点是根节点了,所以不需要做上浮操作。
扩容
当往队列插入数据时,如果队列容量不够则会进行扩容操作。
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
PriorityQueue 的扩容非常简单。如果原来的容量小于 64,那么扩容为原来的两倍,否则扩容为原来的 1.5 倍。
总结
PriorityQueue 的实现是建立在二叉堆之上的,所以弄懂二叉堆就相当于弄懂了 PriorityQueue。PriorityQueue 默认情况下是最小堆,我们可以改变传入的比较器,使其成为最大堆。
集合系列 Queue(十):LinkedList
我们之前在说到 List 集合的时候已经说过 LinkedList 了。但 LinkedList 不仅仅是一个 List 集合实现,其还是一个双向队列实现。
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
LinkedList 不仅实现了 List 接口,还实现了 Deque 接口。所以这一节我们来聊聊 LinkedList 的双向队列特性。
原理
为了深入理解 LinkedList 的原理,我们将从类成员变量、构造方法、核心方法两个方面逐一介绍。
类成员变量
// 链表大小
transient int size = 0;
// 首节点
transient Node first;
// 尾节点
transient Node last;
// Node节点
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
可以看到 LinkedList 采用了链表节点的方式实现,并且每个节点都有前驱和后继节点。
构造方法
LinkedList 总共有 2 个构造方法:
public LinkedList() {
}
public LinkedList(Collection c) {
this();
addAll(c);
}
构造方法比较简单,这里不深入介绍。
核心方法
LinkedList 中与双向队列相关的几个方法为:offerFirst、offerLast、pollFirst、pollLast。
offerFirst
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public void addFirst(E e) {
linkFirst(e);
}
// 将e节点作为头结点插入
private void linkFirst(E e) {
final Node f = first;
final Node newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
offerLast
public boolean offerLast(E e) {
addLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
// 将e节点作为末尾节点插入
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
pollFirst
public E pollFirst() {
final Node f = first;
return (f == null) ? null : unlinkFirst(f);
}
// 删除头结点
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;
final Node next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
pollLast
public E pollLast() {
final Node l = last;
return (l == null) ? null : unlinkLast(l);
}
// 删除尾节点
private E unlinkLast(Node l) {
// assert l == last && l != null;
final E element = l.item;
final Node prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
可以看出无论是插入还是删除,poll 和 offer 操作都相对简单,重点在于引用的修改和维护。
总结
LinkedList 不仅是一个简单的 List 实现,其也是一个双向队列实现。
集合系列 Queue(十一):ArrayDeque
从名字我们可以看出,其实一个双向队列实现,而且底层采用数组实现。
public class ArrayDeque extends AbstractCollection
implements Deque, Cloneable, Serializable
从定义可以看出,其实现了 Deque 接口。
原理
为了深入理解 ArrayDeque 的原理,我们将从类成员变量、构造方法、核心方法两个方面逐一介绍。
类成员变量
// 数据数组
transient Object[] elements;
// 头结点
transient int head;
// 尾节点
transient int tail;
从类成员变量我们就可以知道,其底层确实使用数组存储。
构造方法
ArrayDeque 一共有 3 个构造方法:
public ArrayDeque() {
elements = new Object[16];
}
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
public ArrayDeque(Collection c) {
allocateElements(c.size());
addAll(c);
}
从第一个构造方法可以看到,其构造方法直接指定了 ArrayDeque 的初始大小为 16。
核心方法
对于双向队列来说,其关键的方法是:offer、poll、offerFirst、offerLast、pollFirst、pollLast。但其实这些方法的内容都类似,所以我们只分析 offer 和 poll 方法。
offer
public boolean offer(E e) {
return offerLast(e);
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
// 当 tail 和 head 相遇时,表示队列已满,需要扩容
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
这里比较难懂的地方是这个判断:
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
因为 ArrayDeque 初始容量是 16,而每次扩容都是扩为原来的两倍,所以 ArrayDeque 的容量总是 2 的幂次方。所以上面的判断其实在队列未满时,相当于将 tail 进行加一操作。
if ( (tail = (tail + 1)) == head)
doubleCapacity();
而做这样一个与操作的目的就是在 tail 到达数组末尾时可以自动切换为 0。我们可以假设此数组大小为 16,而此时 tail 指向了 15,即末尾节点。那么此时执行 offer 操作,我们在计算 (tail + 1) & (elements.length - 1) 就会如下图所示:
10000 // tail + 1 = 15 + 1 = 16
01111 // element.length - 1 = 16 -1 =15
00000 // 结果为0
计算出的结果为 0,也就是说 tail 指针指向了 0 这个位置。
poll
public E poll() {
return pollFirst();
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
// 等价于 head = h + 1
// 当处于队列末尾时,会切到队列头
head = (h + 1) & (elements.length - 1);
return result;
}
poll 方法也与 offer 方法类似,在最终对 head 节点加一时也用了同样的方法。
总结
看完 ArrayDeque 类的实现,我们不由得会想起 LinkedList 的实现,因为它们两个都是双向队列的实现,但是一个采用数组实现,一个采用链表实现。那么它们有什么异同呢?
通过查询一些资料发现,其实它们两个在功能和效率上并没有太大不同。如果你需要用到双向队列,那么 ArrayDeque 相对于 LinkedList 要更好。因为 ArrayDeque 相对于 LinkedList 直接采用数组存储,而 LinkedList 则需要采用节点存储。所以 LinkedList 相对于 ArrayDeque 需要消耗更多内存。
本身数组与链表的差异在于查询和修改的差异,但是对于队列来说,其都是在头和尾进行操作。所以数组与链表的差异在队列身上没有任何体现。而查阅 ArrayDeque 和 LinkedList 的发布时间,我们会发现 ArrayDeque 发布于 JDK 1.6,而 LinkedList 发布于 JDK 1.2。所以从这一点来看,我们有理由相信 ArrayDeque 其实是 LinkedList 的优化版本。