理解主成分分析 (PCA)
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。
导言
主成分分析法 (PCA) 是一种常用的数据分析手段。对于一组不同维度 之间可能存在线性相关关系的数据,PCA能够把这组数据通过正交变换变 成各个维度之间线性无关的数据。经过 PCA 处理的数据中的各个样本之间的关系往往更直观,所以它是一种非常常用的数据分析和预处理工具。PCA 处理之后的数据各个维度之间是线性无关的,通过剔除方差较小的那些维 度上的数据我们可以达到数据降维的目的。在本文中,我们将介绍 PCA的原理、应用以及缺陷。
为什么要有 PCA
如果数据之中的某些维度之间存在较强的线性相关关系,那么样本在这 两个维度上提供的信息有就会一定的重复,所以我们希望数据各个维度之间是不相关的 (也就是正交的)。此外,出于降低处理数据的计算量或去除噪 声等目的,我们也希望能够将数据集中一些不那么重要 (方差小) 的维度剔除掉。例如在下图中,数据在 x 轴和 y 轴两个维度上存在着明显的相关性, 当我们知道数据的 x 值时也能大致确定 y 值的分布。但是如果我们不是探 究数据的 x 坐标和 y 坐标之间的关系,那么数据的 x 值和 y 值提供的信息 就有较大的重复。在绿色箭头标注的方向上数据的方差较大,而在蓝色箭头方向上数据的方差较小。这时候我们可以考虑利用蓝色和绿色的箭头表示的单位向量来作为新的基底,在新的坐标系中原来不同维度间线性相关的数据变成了线性不相关的。由于在蓝色箭头方向上数据的方差较小,在需要 降低数据维度的时候我们可以将这一维度上的数据丢弃并且不会损失较多的信息。如果把丢弃这一维度之后的数据重新变化回原来的坐标系,得到的数据与原来的数据之间的误差不大。这被称为重建误差最小化。PCA 就是进行这种从原坐标系到新的坐标系的变换的。
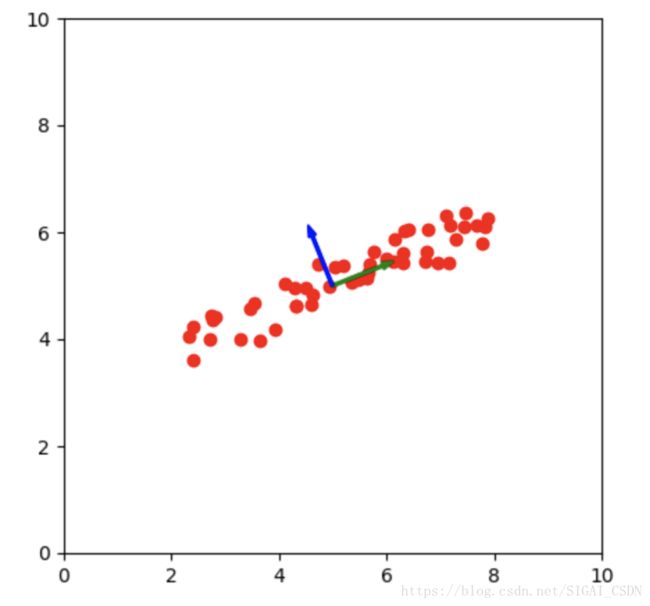
图 1: 示意图
如何计算PCA
数据经过 PCA 变换之后的各个维度被称为主成分,各个维度之间是线 性无关的。为了使变换后的数据各个维度提供的信息量从大到小排列,变换后的数据的各个维度的方差也应该是从大到小排列的。数据经过 PCA 变换 之后方差最大的那个维度被称为第一主成分。
我们先来考虑如何计算第一主成分。假设每一条原始数据是一个 m 维 行向量,数据集中有 n 条数据。这样原始数据就可以看作一个 n 行 m 列的 矩阵。我们将其称为 X,用![]() 代表数据集中的第 i 条数据(也就是 X 的第 i 和行向量)。这里为了方便起见,我们认为原始数据的各个维度的均值都是 0。当原始数据的一些维度的均值不为 0 时我们首先让这一维上的数据分别减去这一维的均值,这样各个维度的均值就都变成了 0。为了使 X 变化 到另一个坐标系,我们需要让 X 乘以一个 m × m 的正交变换矩阵 W。W 视为由列向量
代表数据集中的第 i 条数据(也就是 X 的第 i 和行向量)。这里为了方便起见,我们认为原始数据的各个维度的均值都是 0。当原始数据的一些维度的均值不为 0 时我们首先让这一维上的数据分别减去这一维的均值,这样各个维度的均值就都变成了 0。为了使 X 变化 到另一个坐标系,我们需要让 X 乘以一个 m × m 的正交变换矩阵 W。W 视为由列向量![]() 组成。我们让X和W进行矩阵相乘之后就可以原始数据变换到新的坐标系中。
组成。我们让X和W进行矩阵相乘之后就可以原始数据变换到新的坐标系中。
T = XW
为了使变换不改变数据的大小,我们让 W 中的每个列向量 wi 的长度都为 1,也就是![]() 。T 中的各个列向量为
。T 中的各个列向量为![]() 。为了使第一主 成分 (t1) 的方差最大,
。为了使第一主 成分 (t1) 的方差最大,
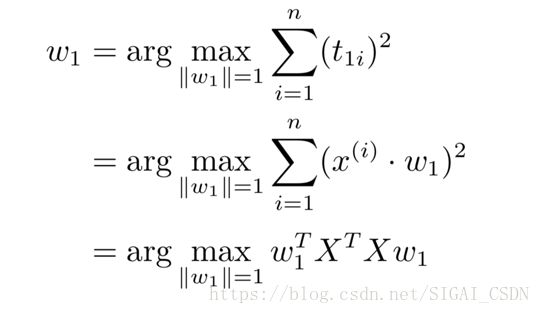
上述最优化问题中 w1 的长度被限制为 1,为了求解 w1,我们将其变成如下的形式:
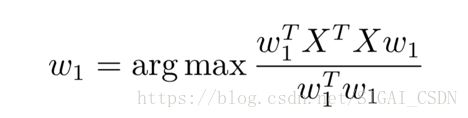
因为当 C 是一个不为零的常数时,
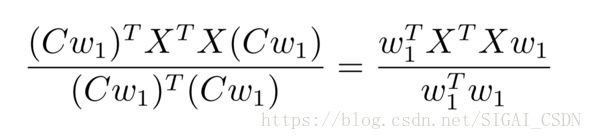
这时候求解出的是 w1 的方向。我们只要在这个方向上长度取长度为 1的向量就得到了结果。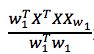 是一个非常常见的瑞利熵,其更一般的形式是
是一个非常常见的瑞利熵,其更一般的形式是
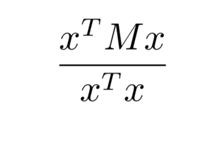
这里的 M 是一个厄米特矩阵 (Hermitian Matrix),在本文中我们可以将其 认为是一个实对称矩阵;x 是一个长度不为零的列向量。求解瑞利熵的最值 需要对实对称矩阵的对角化有一定的了解。这里的![]() 很显然是一个实 对称矩阵。对一个实对称矩阵进行特征值分解,我们可以得到:
很显然是一个实 对称矩阵。对一个实对称矩阵进行特征值分解,我们可以得到:

这里的 D 是一个对角矩阵,对角线上的元素是特征值;P =< p1, p2, ..., pn >, 每个 pi 都是一个长度为 1 的特征向量,不同的特征向量之间正交。我们将 特征值分解的结果带回瑞利熵中可以得到
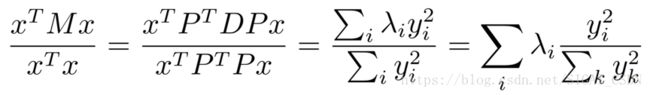
这里的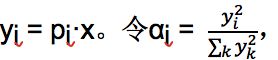 这时有
这时有![]() 。这样
。这样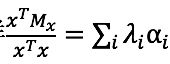 就构成了一个一维凸包。根据凸包的性质我们可以知 道,当最大的 λi 对应的 αi = 1 时整个式子有最大值。所以当 x 的为最大的 特征值对应的特征向量时瑞利熵有最大值,这个最大值就是最大的特征值。 根据这个结论我们就可以知道 w1 就是 XT X 的最大的特征值对应的特征向 量,第一主成分 t1 = Xw1。这样我们就得到了计算第一主成分的方法。接 下来我们继续考虑如何计算其他的主成分。因为 W 是一个正交矩阵,所以
就构成了一个一维凸包。根据凸包的性质我们可以知 道,当最大的 λi 对应的 αi = 1 时整个式子有最大值。所以当 x 的为最大的 特征值对应的特征向量时瑞利熵有最大值,这个最大值就是最大的特征值。 根据这个结论我们就可以知道 w1 就是 XT X 的最大的特征值对应的特征向 量,第一主成分 t1 = Xw1。这样我们就得到了计算第一主成分的方法。接 下来我们继续考虑如何计算其他的主成分。因为 W 是一个正交矩阵,所以
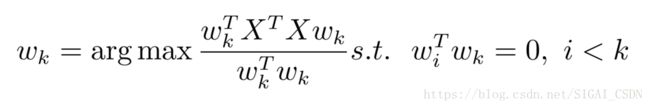
因为 wk 和 w1, w2, ..wk−1 正交,
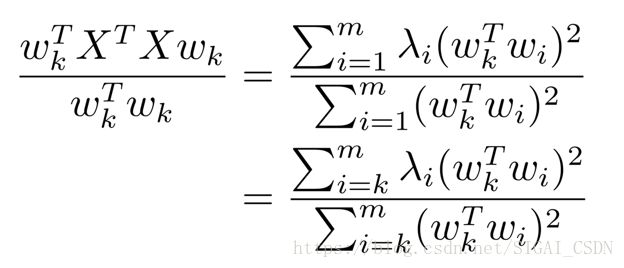
为了使第 k 个主成分在与前 k - 1 个主成分线性无关的条件下的方差最大, 那么 wk 应该是第 k 大的特征值对应的特征向量。经过这些分析我们就能发 现变换矩阵 W 中的每个列向量就是![]() 的各个特征向量按照特征值的大小从左到右排列得到的。
的各个特征向量按照特征值的大小从左到右排列得到的。
接下来我们对如何计算 PCA 做一个总结:
1、把每一条数据当一个行向量,让数据集中的各个行向量堆叠成一个矩阵。
2、将数据集的每一个维度上的数据减去这个维度的均值,使数据集每个维度的均值都变成 0,得到矩阵 X。
3、计算方阵![]() 的特征值和特征向量,将特征向量按照特征值由大到 小的顺序从左到右组合成一个变化矩阵 W。为了降低数据维度,我们 可以将特征值较小的特征向量丢弃
的特征值和特征向量,将特征向量按照特征值由大到 小的顺序从左到右组合成一个变化矩阵 W。为了降低数据维度,我们 可以将特征值较小的特征向量丢弃
4、计算 T = XW,这里的 T 就是经过 PCA 之后的数据矩阵。
除了这种方法之外,我们还可以使用奇异值分解的方法来对数据进行 PCA处理,这里不再详细介绍。
PCA 的应用
首先我们来看一下 PCA 在数据降维方面的应用。我们在 MNIST 数据 集上进行了测试。我们对 MNIST 的测试集中的每一幅 28×28 的图片的变成 一个 784 维的行向量,然后把各幅图片拼接成的行向量堆叠一个 784×10000 的数据矩阵。对这个数据矩阵进行 PCA 处理。处理得到的特征值的分布如 下图。通过图片我们可以看出前面一小部分的特征值比较大,后面的特征值
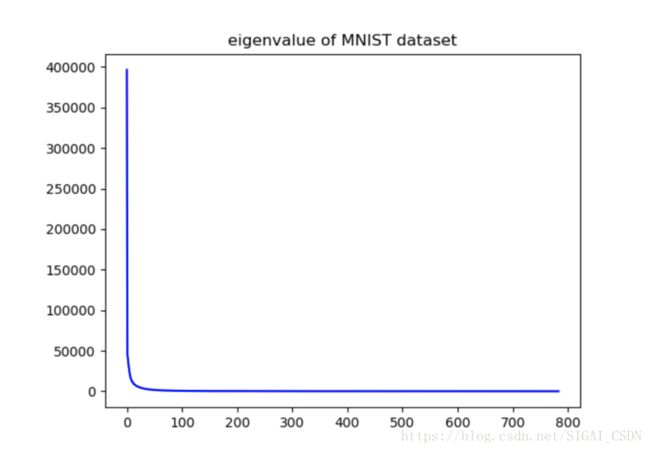
图 2: MNIST 数据集特征值的分布
都比较接近于零。接下来我们取前 200,300 个主成分对数据进行重建。我 们发现使用前 200 个主成分重建的图像已经能够大致分辨出每个数字,使 用前 300 个主成分重建的图像已经比较清晰。根据实验我们可以发现 PCA 能够在丢失较少的信息的情况下对数据进行降维。
PCA 在自然语言处理方面也有比较多的应用,其中之一就是用来计算 词向量。word2vec 是 Google 在 2013 年提出了一个自然语言处理工具包,
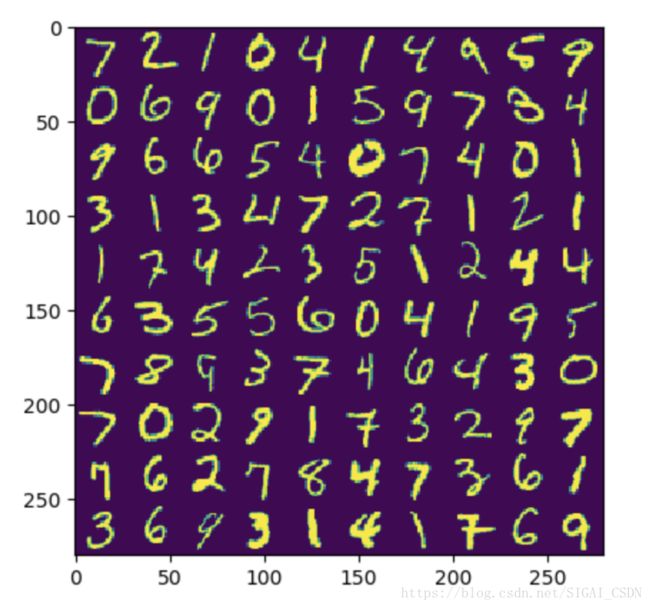
图 3: 原始图像
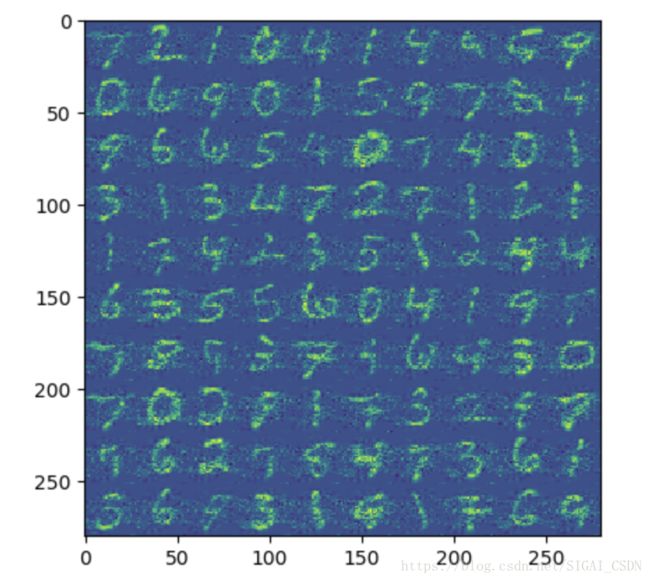
图 4: 使用前 200 个主成分重建的图像
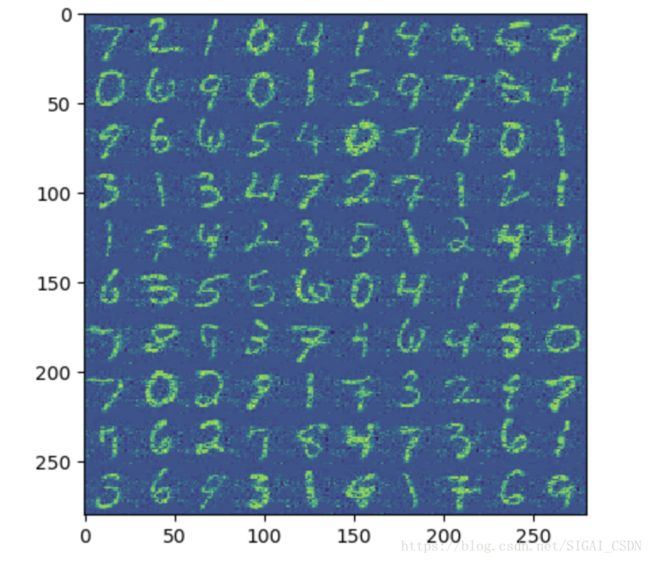
图 5: 使用前 300 个主成分重建的图像
其思想是用一个向量来表示单词,意思和词性相近的单词对应的向量之间 的距离比较小,反之则单词之间的距离比较大。word2vec 原本是使用神经网络计算出来的,本文中的 PCA 也可以被用于计算词向量。具体的做法为: 构建一个单词共生矩阵,然后对这个矩阵进行 PCA 降维,将降维得到的数 据作为词向量。使用这种方法构造出的词向量在单独使用时效果虽然不如 使用神经网络计算出的词向量,但是将神经网络构造出来的词向量和使用 PCA 降维得到的词向量相加之后得到的词向量在表示词语意思时的效果要 好于单独使用神经网络计算出来的词向量。
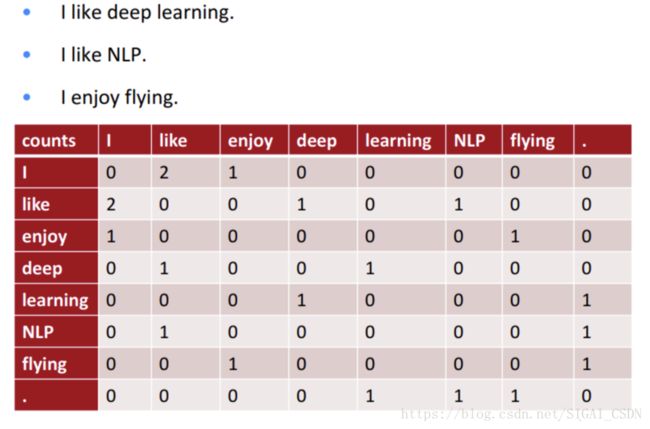
图 6: 一个共生矩阵的例子,
图片来自于斯坦福大学公开课 cs224n 课件
PCA 的缺陷
虽然 PCA 是一种强大的数据分析工具,但是它也存在一定的缺陷。一 方面,PCA 只能对数据进行线性变换,这对于一些线性不可分的数据是不利的。为了解决 PCA 只能进行线性变换的问题,Schölkopf, Bernhard 在 1998 年提出了 Kernel PCA。Kernel PCA 在计算 M =![]() 的时候不是直接进行相乘,而是使
的时候不是直接进行相乘,而是使![]() 。这里的K(xi,xj)是一个与支持向量机中类似的核函数。这样就能够对数据进行非线性变换。另一方面,PCA 的结果容易受到每一维数据的大小的影响,如果我们对每一维数据乘以一个不同的权重因子之后再进行 PCA降维,得到的结果可能与直接进行PCA降维得到的结果相差比较大。对于这个问题,Leznik 等人在论文Estimating Invariant Principal Components Using Diagonal Regression 中给出了一种解决方案。除此之外,PCA 要求数每一维的均值都是0,在将原始数据的每一维的均值都变成0时可能会丢失掉一些信息。虽然PCA有这些缺陷,但是如果合理的利用,PCA 仍然不失为一种优秀的数据分析和降维的手段。
。这里的K(xi,xj)是一个与支持向量机中类似的核函数。这样就能够对数据进行非线性变换。另一方面,PCA 的结果容易受到每一维数据的大小的影响,如果我们对每一维数据乘以一个不同的权重因子之后再进行 PCA降维,得到的结果可能与直接进行PCA降维得到的结果相差比较大。对于这个问题,Leznik 等人在论文Estimating Invariant Principal Components Using Diagonal Regression 中给出了一种解决方案。除此之外,PCA 要求数每一维的均值都是0,在将原始数据的每一维的均值都变成0时可能会丢失掉一些信息。虽然PCA有这些缺陷,但是如果合理的利用,PCA 仍然不失为一种优秀的数据分析和降维的手段。
参考文献
- Pearson, K. (1901). ”On Lines and Planes of Closest Fit to Systems of Points in Space”.http://stat.smmu.edu.cn/history/pearson1901.pdf. Philosophical Magazine. 2 (11):559–572.
- Principal component analysis(主成分分析). https://en.wikipedia.org/wiki/Principal_component
- Rayleigh quotient(瑞利熵). https://en.wikipedia.org/wiki/Rayleigh_quotient.Wikipedia.
- Hermitian matrix(厄米特矩阵). https://en.wikipedia.org/wiki/Hermitian_matrix.Wikipedia.
- Yann LeCun. [MNIST 数据集] (http://yann.lecun.com/exdb/mnist/).
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Je rey Dean.(2013)”Distributed Representations of Words and Phrases and their Compositionality”.https://arxiv.org/pdf/1310.45 arxiv.org.
- Schölkopf, Bernhard (1998). ”Nonlinear Component Analysis as a Kernel Eigenvalue Problem”. Neural Computation. 10: 1299–1319. doi:10.1162/089976698300017467.
- Leznik, M; Tofallis, C. 2005 [uhra.herts.ac.uk/bitstream/handle/2299/715/S56.pdf Estimating Invariant Principal Components Using Diagonal Regres-
sion.]
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。
推荐阅读
[1] 机器学习-波澜壮阔40年 SIGAI 2018.4.13.
[2] 学好机器学习需要哪些数学知识?SIGAI 2018.4.17.
[3] 人脸识别算法演化史 SIGAI 2018.4.20.
[4] 基于深度学习的目标检测算法综述 SIGAI 2018.4.24.
[5] 卷积神经网络为什么能够称霸计算机视觉领域? SIGAI 2018.4.26.
[6] 用一张图理解SVM的脉络 SIGAI 2018.4.28.
[7] 人脸检测算法综述 SIGAI 2018.5.3.
[8] 理解神经网络的激活函数 SIGAI 2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 SIGAI 2018.5.8.
[10] 理解梯度下降法 SIGAI 2018.5.11
[11] 循环神经网络综述—语音识别与自然语言处理的利器 SIGAI 2018.5.15
[12] 理解凸优化 SIGAI 2018.5.18
[13]【实验】理解SVM的核函数和参数 SIGAI 2018.5.22
[14]【SIGAI综述】 行人检测算法 SIGAI 2018.5.25
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上) SIGAI 2018.5.29
[16] 理解牛顿法 SIGAI 2018.5.31
[17] 【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题 SIGAI 2018.6.1
[18] 大话Adaboost算法 SIGAI 2018.6.1
[19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法 SIGAI 2018.6.4
