反向传播算法推导-卷积神经网络
本文及其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造,自2019年1月出版以来已重印3次。
- 书的购买链接
- 书的勘误,优化,源代码资源
导言–
在SIGAI之前的公众号文章“反向传播算法推导-全连接神经网络”中,我们推导了全连接神经网络的反向传播算法。其核心是定义误差项,以及确定误差项的递推公式,再根据误差项得到对权重矩阵、偏置向量的梯度。最后用梯度下降法更新。卷积神经网络由于引入了卷积层和池化层,因此情况有所不同。在今天这篇文章中,我们将详细为大家推导卷积神经网络的反向传播算法。对于卷积层,我们将按两条路线进行推导,分别是标准的卷积运算实现,以及将卷积转化成矩阵乘法的实现。在文章的最后一节,我们将介绍具体的工程实现,即卷积神经网络的卷积层,池化层,激活函数层,损失层怎样完成反向传播功能。
回顾
首先回顾一下全连接神经网络反向传播算法的误差项递推计算公式。根据第l层的误差项计算第l-1层的误差项的递推公式为:
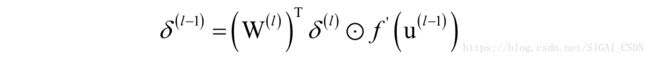
其中W为权重矩阵,u为临时变量,f为激活函数。根据误差项计算权重梯度的公式为:
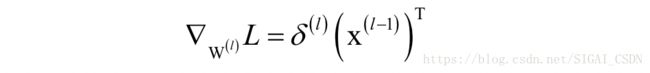
其中x为本层的输入向量。这几组公式具有普遍意义,对于卷积神经网络的全连接层依然适用。如果你对这些公式的推导还不清楚,请先去阅读我们之前的文章“反向传播算法推导-全连接神经网络”。
卷积层
首先推导卷积层的反向传播计算公式。正向传播时,卷积层实现的映射为:
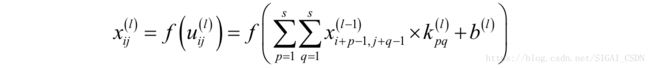
我们用前面的这个例子来进行计算:
卷积输出图像的任意一个元素都与卷积核矩阵的任意一个元素都有关,因为输出图像的每一个像素值都共用了一个卷积核模板。反向传播时需要计算损失函数对卷积核以及偏置项的偏导数,和全连接网络不同的是,卷积核要作用于同一个图像的多个不同位置。
上面的描述有些抽象,下面我们用一个具体的例子来说明。假设卷积核矩阵为:
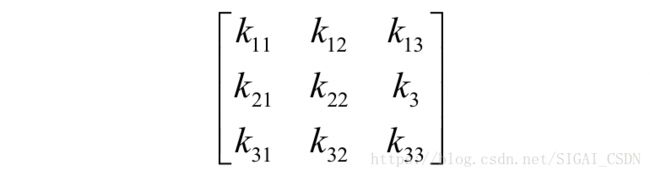
输入图像是:

卷积之后产生的输出图像是U,注意这里只进行了卷积、加偏置项操作,没有使用激活函数:
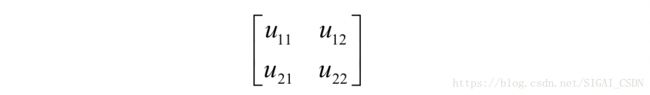
正向传播时的卷积操作为:
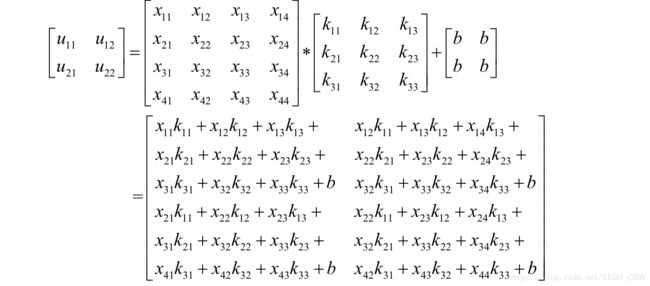
反向传播时需要计算损失函数对卷积核以及偏置项的偏导数,和全连接网络不同的是,卷积核要反复作用于同一个图像的多个不同位置。根据链式法则,损失函数对第l层的卷积核的偏导数为:
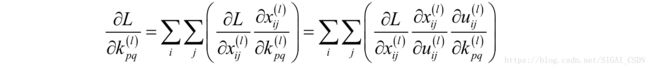
在这里i和j是卷积输出图像的行和列下标,这是因为输出图像的每一个元素都与卷积核的元素 k_{pq} 相关。首先我们看上式最右边求和项的第二个乘积项:
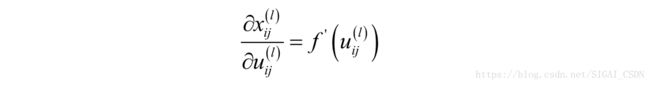
这是激活函数对输入值的导数,激活函数作用于每一个元素,产生同尺寸的输出图像,和全连接网络相同。第三个乘积项为:
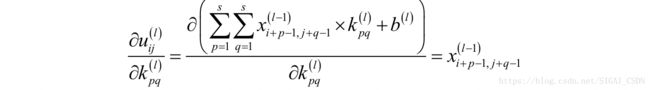
假设 已经求出,我们根据它就可以算出 的值:
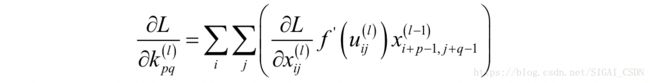
偏置项的偏导数更简单:
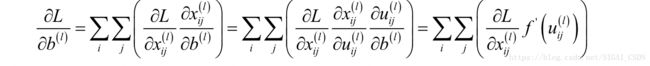
这和全连接层的计算方式类似。同样的定义误差项为:
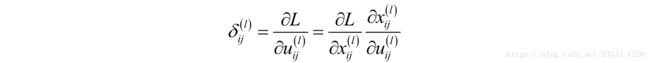
这是损失函数对临时变量的偏导数。和全连接型不同的是这是一个矩阵:

尺寸和卷积输出图像相同,而全连接层的误差向量和该层的神经元个数相等。这样有:
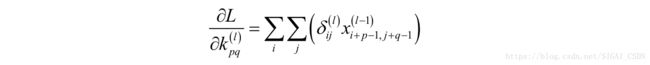
这也是一个卷积操作, 充当卷积核, 则充当输入图像。
卷积输出图像对应的误差项矩阵 为:
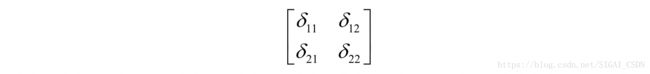
下面计算损失函数对卷积核各个元素的偏导数,根据链式法则有:
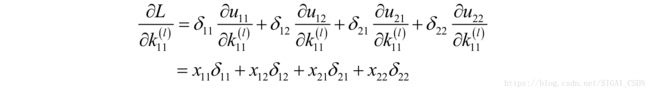
这是因为产生输出 时卷积核元素 在输入图像中对应的元素是 。产生输出 时卷积核元素 在输入图像中对应的元素是 。其他的依次类推。同样的有:
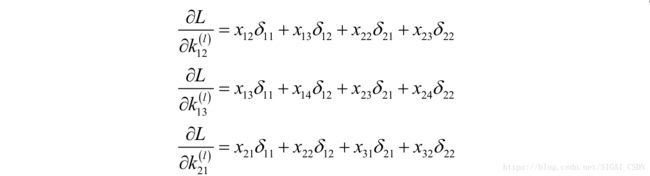
其他的以此类推。从上面几个偏导数的值我们可以总结出这个规律:损失函数对卷积核的偏导数实际上就是输入图像矩阵与误差矩阵的卷积:
其中 为卷积运算。写成矩阵形式为:
![]()
在这里conv为卷积运算,卷积输出图像的尺寸刚好和卷积核矩阵的尺寸相同。现在的问题是 怎么得到。如果卷积层后面是全连接层,按照全连接层的方式可以从后面的层的误差得到 。如果后面跟的是池化层,处理的方法在下一节中介绍。
接下来要解决的问题是怎样将误差项传播到前一层。卷积层从后一层接收到的误差为 ,尺寸和卷积输出图像相同,传播到前一层的误差为 ,尺寸和卷积输入图像相同。同样的,我们用上面的例子。假设已经得到了 ,现在要做的是根据这个值计算出 。根据定义:
正向传播时的卷积操作为:
根据定义:
由于:
![]()
因此有:
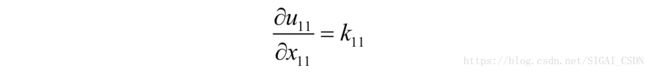
类似的可以得到:
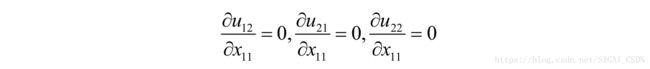
从而有:
![]()
类似的有:
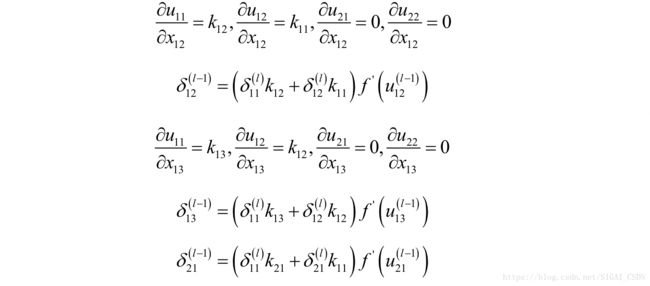
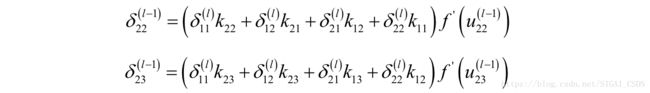
剩下的以此类推。从上面的过程我们可以看到,实际上是将 进行扩充(上下左右各扩充2个0)之后的矩阵和卷积核矩阵K进行顺时针180度旋转的矩阵的卷积,即:

将上面的结论推广到一般情况,我们得到误差项的递推公式为:
![]()
其中rot180表示矩阵顺时针旋转180度操作。至此根据误差项得到了卷积层的权重,偏置项的偏导数;并且把误差项通过卷积层传播到了前一层。推导卷积层反向传播算法计算公式的另外一种思路是把卷积运算转换成矩阵乘法,这种做法更容易理解,在后面将会介绍。
池化层
池化层没有权重和偏置项,因此无需对本层进行参数求导以及梯度下降更新,所要做的是将误差项传播到前一层。假设池化层的输入图像是 ,输出图像为 ,这种变换定义为:
![]()
其中down为下采样操作,在正向传播时,对输入数据进行了压缩。在反向传播时,接受的误差是 ,尺寸和 相同,传递出去的误差是 ,尺寸和 相同。和下采样相反,我们用上采样来计算误差项:
![]()
其中up为上采样操作。如果是对s×s的块进行的池化,在反向传播时要将 的一个误差项值扩展为 的对应位置的s×s个误差项值。下面分别对均值池化和max池化进行讨论。均值池化的变换函数为:
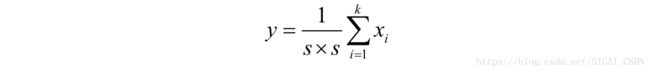
其中 为池化的s×s子图像块的像素,y是池化输出像素值。假设损失函数对输出像素的偏导数为 ,则对输入像素的偏导数为:
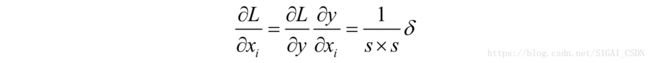
因此由 得到 的方法为,将 的每一个元素都扩充为s×s个元素:
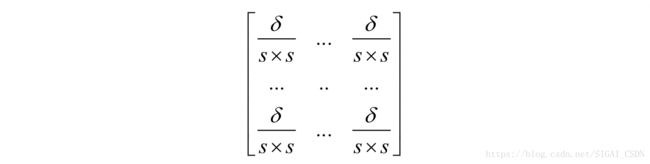
再看第二种情况。如果是max池化,在进行正向传播时,需要记住最大值的位置。在反向传播时,对于扩充的s×s块,最大值位置处的元素设为,其他位置全部置为0:

同样的,我们给出推导过程。假设池化函数为:
![]()
损失函数对 的偏导数为:
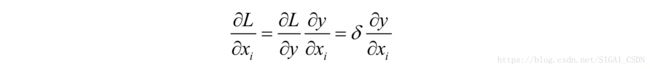
在这里分两种情况,如果i=t,则有:
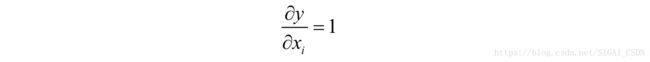
否则有:
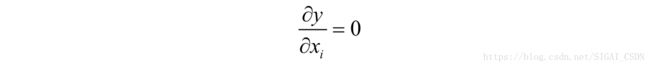
至此我们得到了卷积层和池化层的反向传播实现。全连接层的反向传播计算方法和全连接神经网络相同,组合起来我们就得到了整个卷积网络的反向传播算法计算公式。
将卷积转化成矩阵乘法
如果用标准的形式实现卷积,则要用循环实现,依次执行乘法和加法运算。为了加速,可以将卷积操作转化成矩阵乘法实现,以充分利用GPU的并行计算能力。
整个过程分为以下3步:
1.将待卷积图像、卷积核转换成矩阵
2.调用通用矩阵乘法GEMM函数对两个矩阵进行乘积
3.将结果矩阵转换回图像
在反卷积的原理介绍中,我们也介绍了这种用矩阵乘法实现卷积运算的思路。在Caffe的实现中和前面的思路略有不同,不是将卷积核的元素复制多份,而是将待卷积图像的元素复制多份。
首先将输入图像每个卷积位置处的子图像按照行拼接起来转换成一个列向量。假设子图像的尺寸为s×s,和卷积核大小一样,列向量的尺寸就是s×s;如果一共有 个卷积子图像,列向量的个数就是 ,接下来将这些列向量组合起来形成矩阵。假设有一个m×n的输入图像:
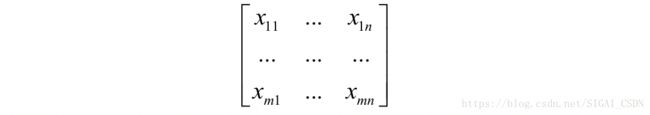
对于第一个卷积位置的s×s子图像,转换成列向量之后变为:
![]()
对于单通道图像,将所有位置的子矩阵都像这样转换成列向量,最后将 个列向量组成矩阵,矩阵的行数为s×s,列数为 :
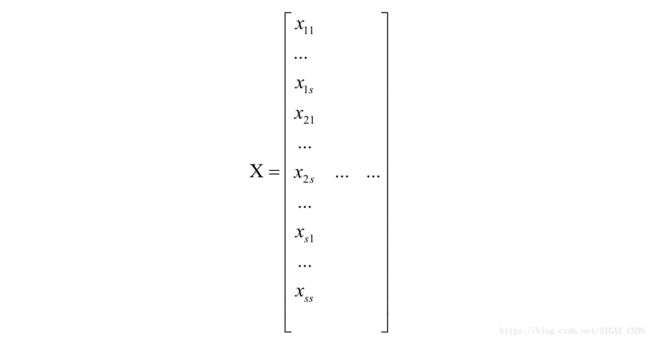
对于多通道图像,还要将上面的这种单通道图像转换成的矩阵在垂直方向依次拼接起来。最后形成的矩阵的行数为c×s×s,其中c是图像的通道数。
接下来,将卷积核矩阵也转换成向量。具体做法是,将卷积核矩阵的所有行拼接起来形成一个行向量。每个卷积核形成一个行向量,有 个卷积核,就有 个行向量。假设有一个s×s的卷积核矩阵:

转换之后变成这样的列向量:
![]()
如果卷积核有多个通道,就将这多个通道拼接起来,形成一个更大的行向量。由于卷积层有多个卷积核,因此这样的行向量有多个,将这些行向量合并在一起,形成一个矩阵:

有了上面这些矩阵,最后就将卷积操作转换成如下的矩阵乘积:
![]()
乘积结果矩阵的每一行是一个卷积结果图像。下面用一个实际的例子来说明。假设输入图像为:

卷积核为:

则输入图像的第一个卷积位置的子图像为:

转化为列向量后为:
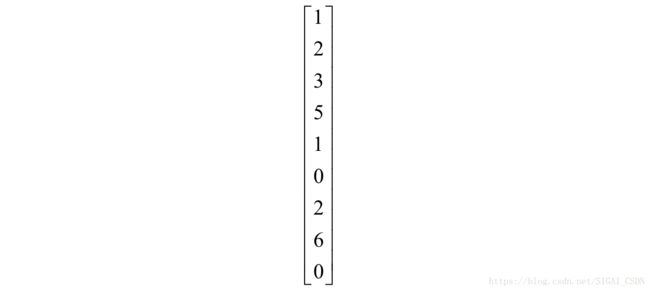
第二个卷积位置的子图像为:

转化成列向量为:
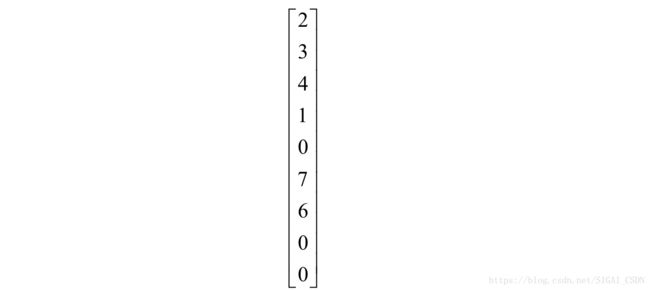
总共有4个卷积子图像,这样整个图像转换成矩阵之后为:
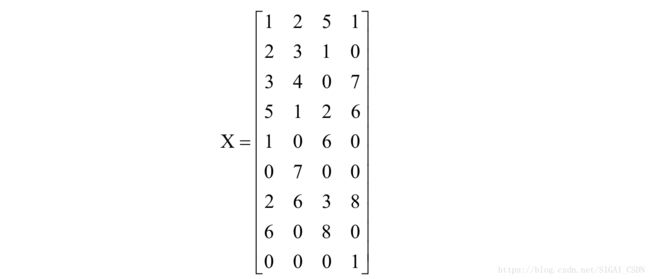
卷积核转换成矩阵之后为:
![]()
读者可以验证,矩阵乘法:
![]()
即为卷积的结果。
采用这种矩阵乘法之后,反向传播求导可以很方面的通过矩阵乘法实现,和全连接神经网络类似。假设卷积输出图像为Y,即:
Y=KX
则我们可以很方便的根据损失函数对Y的梯度计算出对卷积核的梯度,根据之前的文章“反向传播算法推导-全连接神经网络”中证明过的结论,有:
![]()
而误差项传播到前一层的计算公式为:
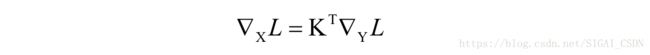
工程实现
下面我们介绍全连接层,卷积层,池化层,激活函层,损失层的工程实现细节。核心是正向传播和反向传播的实现。
在实现时,由于激活函数对全连接层,卷积层,以后要讲述的循环神经网络的循环层都是一样的,因此为了代码复用,灵活组合,一般将激活函数单独拆分成一层来实现。
下面我们将各种层抽象成统一的实现方式。在正向传播时,每一层根据输入数据 计算输出数据 ,本层可能还有需要训练得到的参数 。正向传播时的计算为:
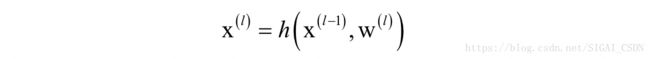
其中h是本层的映射函数。
无论是哪一种层,反向传播时要做的事情是:
如果本层有需要通过训练得到的参数,根据后一层传入的误差项 计算本层参数的梯度值 ,而这个误差项是损失函数对本层输出值的梯度:
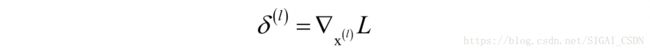
将误差传播到前一层,即根据 计算 是损失函数对本层输入数据的梯度:
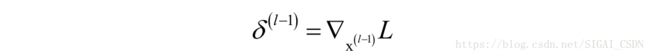
在之前的文章“反向传播算法推导-全连接神经网络”中已经介绍过,激活函数实现的是向量到向量的逐元素映射,对输入向量的每个分量进行激活函数变换。正向传播时接受前一层的输入,通过激活函数作用于输入数据的每个元素之后产生输出。反向传播时接受后一层传入的误差项,计算本层的误差项并把误差项传播到前一层,计算公式为:
![]()
由于激活层没有需要训练得到的参数,因此无需根据误差项计算本层的梯度值,只需要将误差传播到前一层即可。
拆出激活函数之后,全连接层的输入数据是一个向量,计算该向量与权重矩阵的乘积,如果需要还要加上偏置,最后产生输出。正向传播的计算公式为:
![]()
反向传播时计算本层权重与偏置的导数:
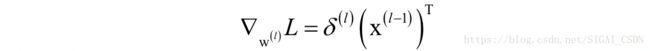
另外还要将误差传播到前一层:
![]()
卷积层和池化层的反向传播实现已经在前面介绍了,因此在这里不再重复。
损失层实现各种类型的损失函数,它们仅在训练阶段使用,是神经网络的最后一层,也是反向传播过程的起点。损失层的功能是在正向传播时根据传入的数据以及函数的参数计算损失函数的值,送入到求解器中使用;在反向传播时计算损失函数对输入数据的导数值,传入前一层。
推荐阅读
推荐阅读
[1]机器学习-波澜壮阔40年【获取码】SIGAI0413.
[2]学好机器学习需要哪些数学知识?【获取码】SIGAI0417.
[3] 人脸识别算法演化史【获取码】SIGAI0420.
[4]基于深度学习的目标检测算法综述 【获取码】SIGAI0424.
[5]卷积神经网络为什么能够称霸计算机视觉领域?【获取码】SIGAI0426.
[6] 用一张图理解SVM的脉络【获取码】SIGAI0428.
[7] 人脸检测算法综述【获取码】SIGAI0503.
[8] 理解神经网络的激活函数 【获取码】SIGAI2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读【获取码】SIGAI0508.
[10] 理解梯度下降法【获取码】SIGAI0511.
[11] 循环神经网络综述—语音识别与自然语言处理的利器【获取码】SIGAI0515
[12] 理解凸优化 【获取码】 SIGAI0518
[13] 【实验】理解SVM的核函数和参数 【获取码】SIGAI0522
[14]【SIGAI综述】行人检测算法 【获取码】SIGAI0525
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上)【获取码】SIGAI0529
[16]理解牛顿法【获取码】SIGAI0531
[17] 【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题【获取码】SIGAI 0601
[18] 大话Adaboost算法 【获取码】SIGAI0602
[19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法【获取码】SIGAI0604
[20] 理解主成分分析(PCA)【获取码】SIGAI0606
[21] 人体骨骼关键点检测综述 【获取码】SIGAI0608
[22]理解决策树 【获取码】SIGAI0611
[23] 用一句话总结常用的机器学习算法【获取码】SIGAI0611
[24] 目标检测算法之YOLO 【获取码】SIGAI0615
[25] 理解过拟合 【获取码】SIGAI0618
[26]理解计算:从√2到AlphaGo ——第1季 从√2谈起 【获取码】SIGAI0620
[27] 场景文本检测——CTPN算法介绍 【获取码】SIGAI0622
[28] 卷积神经网络的压缩和加速 【获取码】SIGAI0625
[29] k近邻算法 【获取码】SIGAI0627
[30]自然场景文本检测识别技术综述 【获取码】SIGAI0627
[31] 理解计算:从√2到AlphaGo ——第2季 神经计算的历史背景 【获取码】SIGAI0704
[32] 机器学习算法地图【获取码】SIGAI0706
[33] 反向传播算法推导-全连接神经网络【获取码】SIGAI0709
[34] 生成式对抗网络模型综述【获取码】SIGAI0709.
[35]怎样成为一名优秀的算法工程师【获取码】SIGAI0711.
[36] 理解计算:从根号2到AlphaGo——第三季 神经网络的数学模型【获取码】SIGAI0716
[37]【技术短文】人脸检测算法之S3FD 【获取码】SIGAI0716
[38] 基于深度负相关学习的人群计数方法【获取码】SIGAI0718
[39] 流形学习概述【获取码】SIGAI0723
[40] 关于感受野的总结 【获取码】SIGAI0723
[41] 随机森林概述 【获取码】SIGAI0725
[42] 基于内容的图像检索技术综述——传统经典方法【获取码】SIGAI0727
[43] 神经网络的激活函数总结【获取码】SIGAI0730
[44] 机器学习和深度学习中值得弄清楚的一些问题【获取码】SIGAI0802
[45] 基于深度神经网络的自动问答系统概述【获取码】SIGAI0806
[46] 机器学习与深度学习核心知识点总结 写在校园招聘即将开始时 【获取 码】SIGAI0808
[47] 理解Spatial Transformer Networks【获取码】SIGAI0810
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。