Python爬虫之Scrapy爬虫框架
Scrapy是一个用Python写的爬虫框架,使用Twisted这个异步网络库来处理网络通信。
这里通过创建CSDN博客爬虫来学习Scrapy爬虫框架。
安装Scrapy:
在Linux上,直接pip install scrapy即可;
在Windows上,需要依次安装pywin32、pyOpenSSL、lxml和scrapy。
本次在Kali上安装,安装成功后能成功看到版本信息:
![]()
CSDN博客爬虫项目:
创建爬虫项目:
到相应的目录中在命令行输入:scrapy startproject csdnSpide
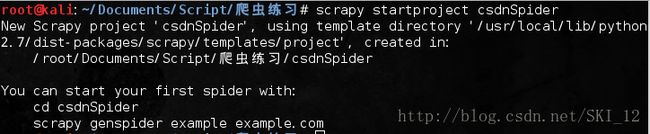
接着进入该项目根目录并显示目录结构信息:
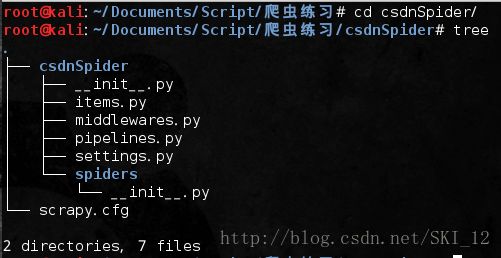
scrapy.cfg:项目部署文件
csdnSpider/:该项目的Python模块,可以在此加入代码
csdnSpider/items.py:项目中的item文件
csdnSpider/pipelines.py:项目中的Pipelines文件
csdnSpider/settings.py:项目的配置文件
csdnSpider/spiders/:放置Spider代码的目录
创建爬虫模块:
到spiders目录中编写爬虫模块,创建一个Spider类,需要继承scrapy.Spider类并定义三个属性:name爬虫的名字(必须唯一)、start_urls、parse()
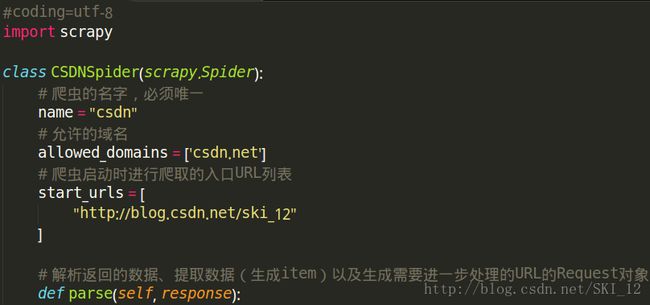
Selector选择器解析HTML内容:
构造XPath,i表示第i篇博文:
每页的文章数量://*[@class="list_item article_item"],然后再获取相应的数组大小即可
标题://*[@id="article_list"]/div[i]/div[1]/h1/span/a/text()
摘要://*[@id="article_list"]/div[i]/div[2]/text()
链接://*[@id="article_list"]/div[i]/div[1]/h1/span/a/@href
调试XPath语法是否正确:在命令行输入:scrapy shell "http://blog.csdn.net/ski_12"
接着输入以下命令测试链接的XPath,另外两个元素也是同样则是即可:
response.xpath('//*[@id="article_list"]/div[1]/div[1]/h1/span/a/@href').extract()
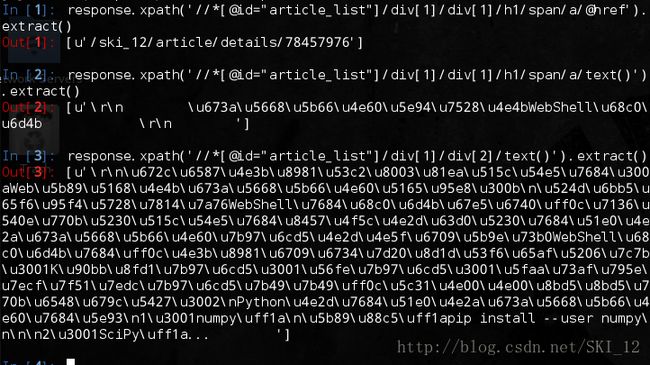
没有问题。然后修改代码直接在该文件中进行输出:
运行爬虫:scrapy crawl csdn
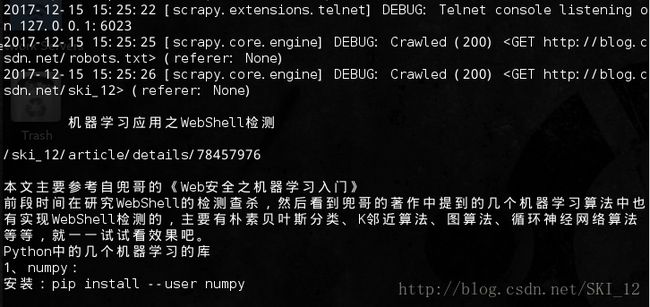
正常解析出来了。
接着添加翻页操作的解析:
![]()
使用re模块正则匹配的表达式下一页
再次运行爬虫:scrapy crawl csdn
定义Item:
Item对象是一种简单的容器,用来保存爬取的诗句,使用简单的class定义语法以及Field对象来声明。定义存储数据的Item类时,需要继承scrapy.Item。Item的操作方式与字典的操作方式相似。

构建Item Pipeline:
当Item在Spider中被收集之后,将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。Item Pipeline的应用主要有:清理HTML数据;验证爬取的数据的合法性,检查Item是否包含某些字段;查重并丢弃;将爬取结果保存到文件或数据库中。
每个Item Pipeline组件都是一个独立的Python类,必须实现process_item方法,且该方法必须返回Item对象或者抛出DropItem异常。

激活Item Pipeline,到settings.py的ITEM_PIPELINES变量中添加该Item Pipeline组件:

至此,简单的爬虫已经基本编写完了,但是还可以添加新的东西。
编写下载器中间件RandomUserAgent:
进一步地,伪造随机的User-Agent来绕过反爬来进行爬取,伪造随机User-Agent的使用需要编写下载器中间件:
下载器中间件是介于Scrapy的request和response处理的钩子函数,是用于全局修改Scrapy的request和response,可以帮助我们定制自己的爬虫系统。
每个中间件组件是定义了以下一个或多个方法的Python类:process_request(request, spider)、process_response(request, response, spider)、process_exception(request, exception, spider)
而本次的编写是定义process_request(request, spider)方法:
在csdnSpider目录中新建一个middlewares目录,在该目录添加__init__.py文件并编写RandomUserAgent.py:
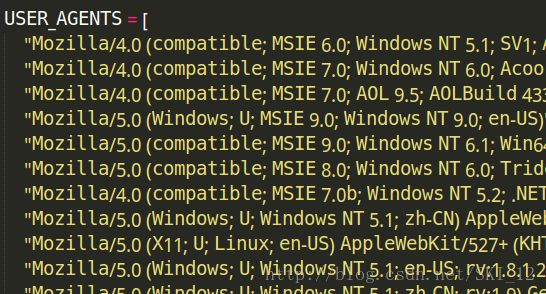
然后在settings.py中添加User-Agent列表:
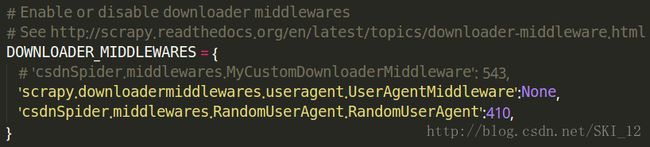
下载器中间件组件需要激活,要添加到settings.py的DOWNLOADER_MIDDLEWARES设置中,禁用内置的User-Agent中间件并启用编写的中间件:
运行爬虫:scrapy crawl csdn
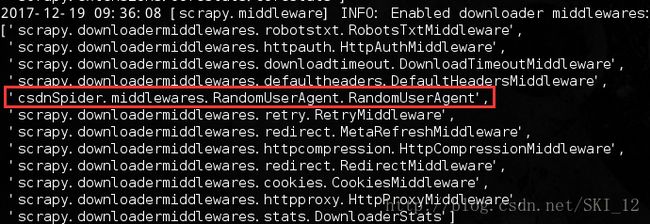
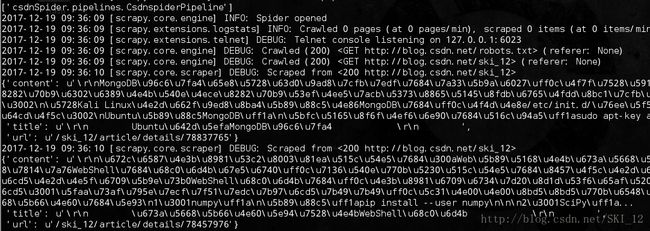

可以看到调用了RandomUserAgent下载器中间件,并成功保存了爬取的数据。
使用Scrapy_redis的分布式爬虫:
在之前的基础上,接着尝试添加基于Redis的分布式爬虫搭建。
安装:pip install scrapy_redis
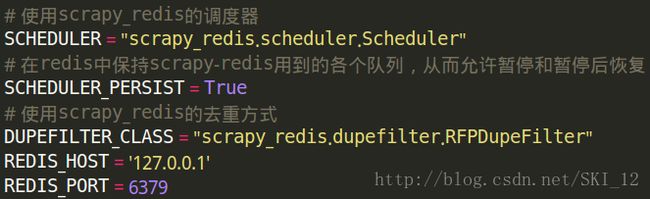
在settings.py中配置Redis:
运行爬虫:
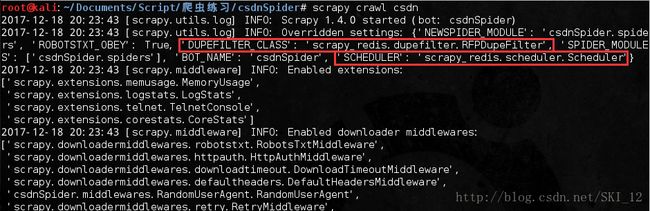
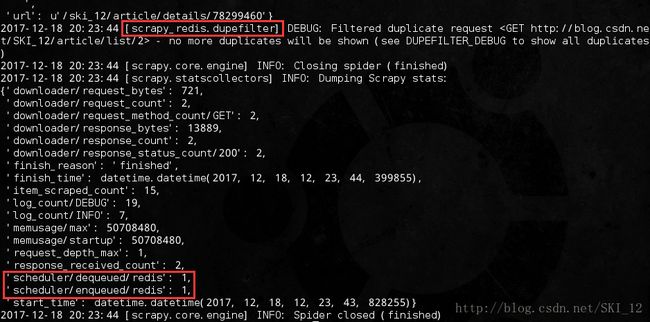

可以看到爬虫正常运行,scrapy_redis的调度器和去重方式被调度使用了。
使用MongoDB集群存储爬取的数据:
最后添加个MongoDB集群来进行保存,关于MongoDB集群的搭建参考《Ubuntu搭建MongoDB集群》即可。这时需要修改pipelines.py的代码:
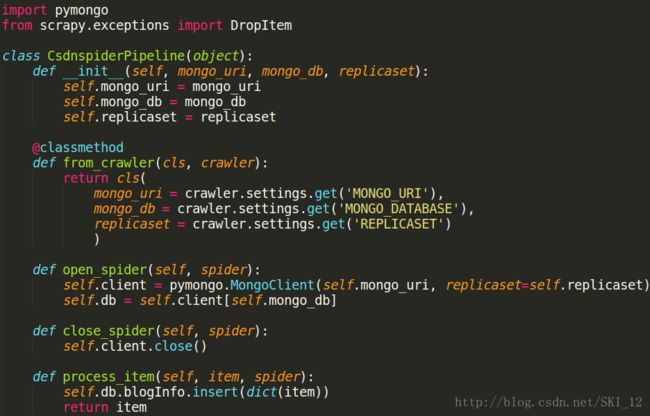
在settings.py中添加MongoDB的内容:

确认环境已配置好:
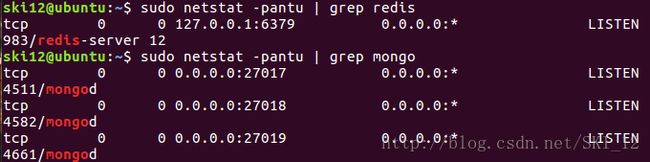
配置开启好MongoDB集群环境后,直接运行爬虫:
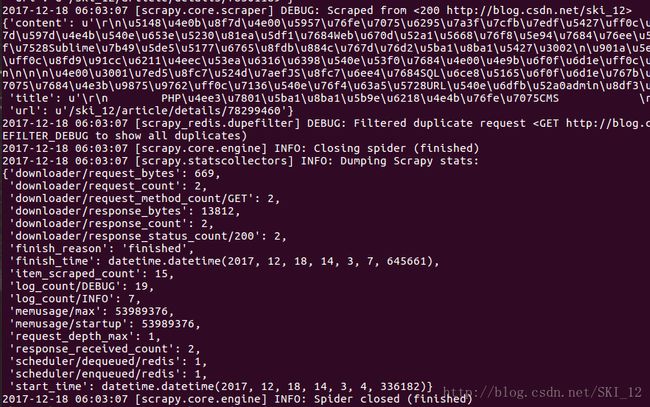
正常爬取到消息,但并没有显示MongoDB相关的信息。
接着直接访问MongoDB的主节点并查看是否保存了爬取的数据:
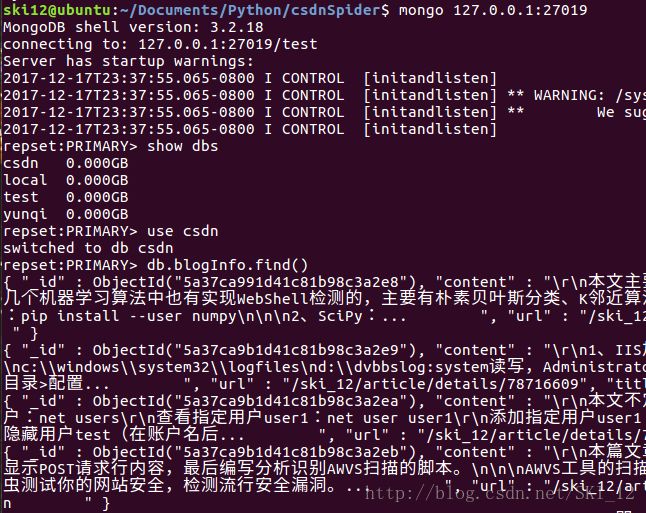
没有问题。
项目源代码:
csdn_spider.py:
#coding=utf-8
import scrapy
import re
from scrapy import Selector
from csdnSpider.items import CsdnspiderItem
class CSDNSpider(scrapy.Spider):
# 爬虫的名字,必须唯一
name = "csdn"
# 允许的域名
allowed_domains = ['csdn.net']
# 爬虫启动时进行爬取的入口URL列表
start_urls = [
"http://blog.csdn.net/ski_12"
]
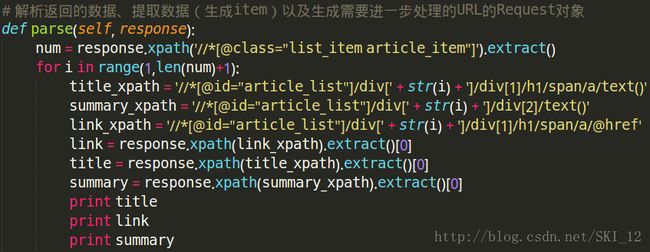
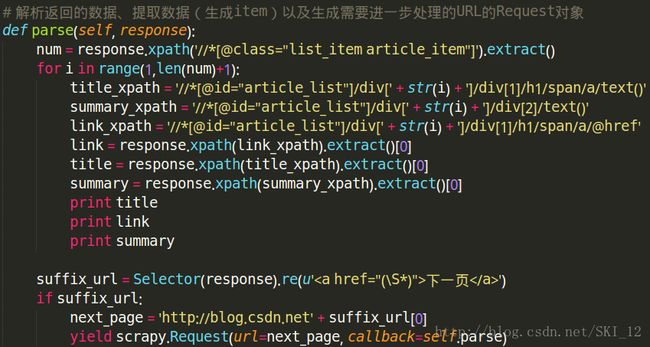
# 解析返回的数据、提取数据(生成item)以及生成需要进一步处理的URL的Request对象
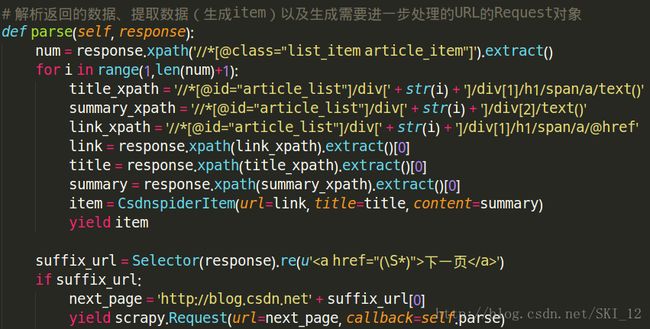
def parse(self, response):
num = response.xpath('//*[@class="list_item article_item"]').extract()
for i in range(1,len(num)+1):
title_xpath = '//*[@id="article_list"]/div[' + str(i) + ']/div[1]/h1/span/a/text()'
summary_xpath = '//*[@id="article_list"]/div[' + str(i) + ']/div[2]/text()'
link_xpath = '//*[@id="article_list"]/div[' + str(i) + ']/div[1]/h1/span/a/@href'
link = response.xpath(link_xpath).extract()[0]
title = response.xpath(title_xpath).extract()[0]
summary = response.xpath(summary_xpath).extract()[0]
item = CsdnspiderItem(url=link, title=title, content=summary)
yield item
suffix_url = Selector(response).re(u'下一页')
if suffix_url:
next_page = 'http://blog.csdn.net' + suffix_url[0]
yield scrapy.Request(url=next_page, callback=self.parse)items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnspiderItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem
class CsdnspiderPipeline(object):
def __init__(self, mongo_uri, mongo_db, replicaset):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.replicaset = replicaset
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DATABASE'),
replicaset = crawler.settings.get('REPLICASET')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri, replicaset=self.replicaset)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db.blogInfo.insert(dict(item))
return itemRandomUserAgent.py:
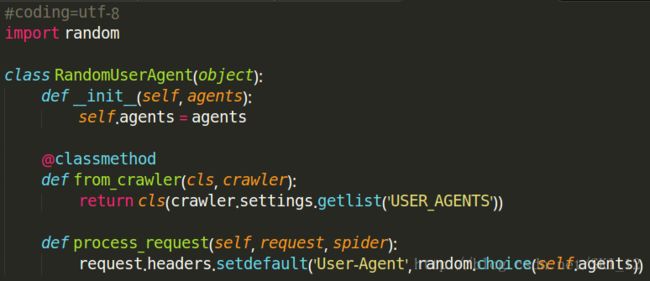
#coding=utf-8
import random
class RandomUserAgent(object):
def __init__(self, agents):
self.agents = agents
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.getlist('USER_AGENTS'))
def process_request(self, request, spider):
request.headers.setdefault('User-Agent', random.choice(self.agents))settings.py:
# -*- coding: utf-8 -*-
# Scrapy settings for csdnSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'csdnSpider'
SPIDER_MODULES = ['csdnSpider.spiders']
NEWSPIDER_MODULE = 'csdnSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdnSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'csdnSpider.middlewares.CsdnspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'csdnSpider.middlewares.MyCustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
'csdnSpider.middlewares.RandomUserAgent.RandomUserAgent':410,
}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'csdnSpider.pipelines.CsdnspiderPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 使用scrapy_redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复
SCHEDULER_PERSIST = True
# 使用scrapy_redis的去重方式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]