java查漏补缺
写在前面(JAVA 8 新特性)
1.关于lambda表达式:
多用于接口方法内部实现。例如在监听器中的应用,可以简化减少内部类的使用,简化代码。
语法()-> {}
// 接口
inteface A{
public void lambda(int a);
}
// 调用
A a = param -> System.out.println(param);
p.lambda(2);
2.java8 :: 关键字的使用:
JDK8中有双冒号的用法,就是把方法当做参数传到stream内部,使stream的每个元素都传入到该方法里面执行一下。
List list = new ArrayList();
list.add(new User("1","1"));
list.add(new User("2","2"));
list.add(new User("3","3"));
list.add(new User("4","4"));
list.add(new User("5","5"));
list.forEach(User::printValur);
注意:printValur的参数类型要与list中的泛型一致
// printValur 为User类中的方法
public static void printValur(User str){
System.out.println("print value : "+str);
}
3.list转map
Map maps = list.stream()
.collect(Collectors.toMap(User::getName, Function.identity(), (key1, key2) -> key2));
System.out.println(maps);
(一)java语言基础
-
java方法的签名:方法名和形参类型共同组成。例如:main(String[])
https://docs.oracle.com/javase/tutorial/java/javaOO/methods.html -
java变量定义:字母、$和下划线开头。
-
java对象的比较:非String对象可以使用“==”与equals()。因String对象复写了equals(),故String对象比较使用equals()。
分析:1、类未复写equals方法,则使用equals方法比较两个对象时,相当于==比较,即两个对象的地址是否相等。地址相等,返回true,地址不相等,返回false。
2、类复写equals方法,比较两个对象时,则走复写之后的判断方式。通常,我们会将equals复写成:当两个对象内容相同时,则equals返回true,内容不同时,返回false。 -
如何让如下代码跑的更快?
String a = "This is only a "; String b = "simple"; String c = "test"; String str = a + b + c;答:
String对象相加,相当于new一个StringBuffer 或 StringBuilder再进行append操作:
String str = a + b + c;
相当于
String str = new StringBuffer(a).append(b).append©.toString();因此可以修改为:
String str = new StringBuilder(a).append(b).append©.toString;
ArrayList集合
(1)ArrayList内部使用数组存储元素,当数组长度不够时进行扩容,每次加一半的空间,ArrayList不会进行缩容;
(2)ArrayList支持随机访问,通过索引访问元素极快,时间复杂度为O(1);
(3)ArrayList添加元素到尾部极快,平均时间复杂度为O(1);
(4)ArrayList添加元素到中间比较慢,因为要搬移元素,平均时间复杂度为O(n);
(5)ArrayList从尾部删除元素极快,时间复杂度为O(1);
(6)ArrayList从中间删除元素比较慢,因为要搬移元素,平均时间复杂度为O(n);
(7)ArrayList支持求并集,调用addAll(Collection c)方法即可;
(8)ArrayList支持求交集,调用retainAll(Collection c)方法即可;
(7)ArrayList支持求单向差集,调用removeAll(Collection c)方法即可;
LinkedList集合
(1)LinkedList是一个以双链表实现的List;
(2)LinkedList还是一个双端队列,具有队列、双端队列、栈的特性;
(3)LinkedList在队列首尾添加、删除元素非常高效,时间复杂度为O(1);
(4)LinkedList在中间添加、删除元素比较低效,时间复杂度为O(n);
(5)LinkedList不支持随机访问,所以访问非队列首尾的元素比较低效;
(6)LinkedList在功能上等于ArrayList + ArrayDeque
(二)面向对象相关知识
1.面向对象
- Java方法创建和重载
- 类的创建及类与对象的关系
- Java面向对象思想编程
- Java方法递归调用
2.封装性
- Java封装性的使用
- java匿名对象的使用
- java构造对象的使用
3.Java面向对象中引用的传递
- java引用传递
- java this关键字
- java static关键字
4.继承
- Java继承的实现
- Java继承的限制
- Java子类对象实例化过程
- Java方法重写与super关键字
- Java重写与重载的区别
表示类型必须是A或者A的子类;表示类型必须是A或者A的超类
List与List的区别?
答:
5.抽象类与接口
- Java final关键字的使用
- Java抽象类
- Java接口的实现
6.Java面向对象多态性
- Java面向对象多态性
- Java面向对象多态性的应用
- Java面向对象instanceof关键字
- Java面向对象抽象类应用
- Java面向对象接口的使用
7. Java面向对象之泛型
7.1 认识泛型
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许开发者在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
泛型带来的好处:
在没有泛型的情况的下,通过对类型 Object 的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是本身就是一个安全隐患。
那么泛型的好处就是在编译的时候能够检查类型安全,并且所有的强制转换都是自动和隐式的。
package aa;
public class GlmapperGeneric{
private T t;
public void set(T t){
this.t =t;
}
public T get(){
return t;
}
public static void main(String[]args){
// do nothing
}
/**
* 不指定类型
*/
public void noSpecifyType(){
GlmapperGeneric glmapperGeneric = new GlmapperGeneric();
glmapperGeneric.set("test");
// 需要强制类型转换
String test =(String)glmapperGeneric.get();
System.out.println(test);
}
/**
* 指定类型
*/
public void specifyType(){
GlmapperGeneric glmapperGeneric =new GlmapperGeneric();
glmapperGeneric.set("test");
// 不需要强制类型转换
String test = glmapperGeneric.get();
System.out.println(test);
}
}
上面这段代码中的 specifyType 方法中 省去了强制转换,可以在编译时候检查类型安全,可以用在类,方法,接口上。
- 构造方法中使用
- 指定多个泛型
7.4 通配符
泛型中通配符
我们在定义泛型类,泛型方法,泛型接口的时候经常会碰见很多不同的通配符,比如 T,E,K,V 等等,这些通配符又都是什么意思呢?
常用的 T,E,K,V,?
本质上这些个都是通配符,没啥区别,只不过是编码时的一种约定俗成的东西。比如上述代码中的 T ,我们可以换成 A-Z 之间的任何一个 字母都可以,并不会影响程序的正常运行,但是如果换成其他的字母代替 T ,在可读性上可能会弱一些。通常情况下,T,E,K,V,?是这样约定的:
?表示不确定的 java 类型
T (type) 表示具体的一个java类型
K V (key value) 分别代表java键值中的Key Value
E (element) 代表Element
? 无界通配符
下面先从一个小例子看起:
我有一个父类 Animal 和几个子类,如狗、猫等,现在我需要一个动物的列表,我的第一个想法是像这样的:
List listAnimals
但是老板的想法确实这样的:
List listAnimals
为什么要使用通配符而不是简单的泛型呢?通配符其实在声明局部变量时是没有什么意义的,但是当你为一个方法声明一个参数时,它是非常重要的。
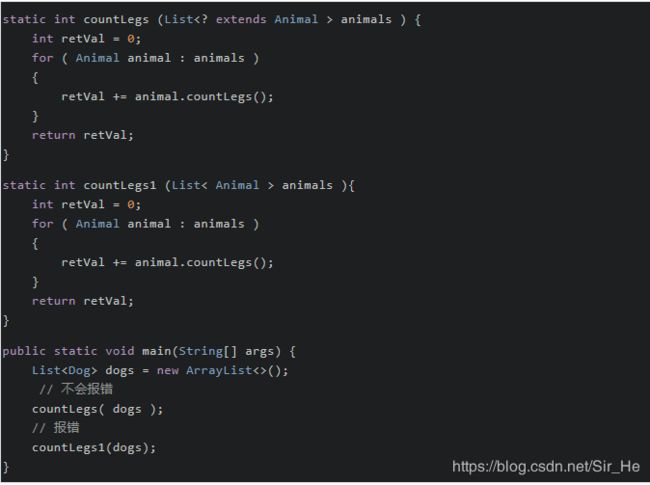
当调用 countLegs1 时,就会飘红,提示的错误信息如下:
![]()
所以,对于不确定或者不关心实际要操作的类型,可以使用无限制通配符(尖括号里一个问号,即 ),表示可以持有任何类型。像 countLegs 方法中,限定了上届,但是不关心具体类型是什么,所以对于传入的 Animal 的所有子类都可以支持,并且不会报错。而 countLegs1 就不行。
上界通配符 < ? extends E>
上界:用 extends 关键字声明,表示参数化的类型可能是所指定的类型,或者是此类型的子类。
- 如果传入的类型不是 E 或者 E 的子类,编译不成功
- 泛型中可以使用 E 的方法,要不然还得强转成 E 才能使用
- 如果传入的类型不是 E 或者 E 的子类,编译不成功
- 泛型中可以使用 E 的方法,要不然还得强转成 E 才能使用
下界通配符 < ? super E>
下界: 用 super 进行声明,表示参数化的类型可能是所指定的类型,或者是此类型的父类型,直至 Object
- 在类型参数中使用 super 表示这个泛型中的参数必须是 E 或者 E 的父类。
?和 T 的区别
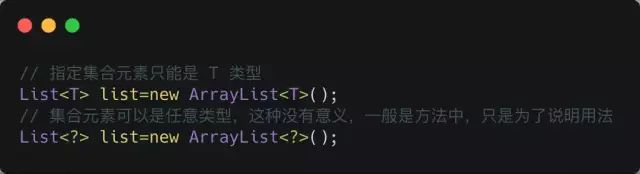
?和 T 都表示不确定的类型,区别在于我们可以对 T 进行操作,但是对 ?不行,比如如下这种 :

简单总结下:
T 是一个 确定的 类型,通常用于泛型类和泛型方法的定义,?是一个 不确定 的类型,通常用于泛型方法的调用代码和形参,不能用于定义类和泛型方法。
区别1:通过 T 来 确保 泛型参数的一致性

像下面的代码中,约定的 T 是 Number 的子类才可以,但是申明时是用的 String ,所以就会飘红报错。
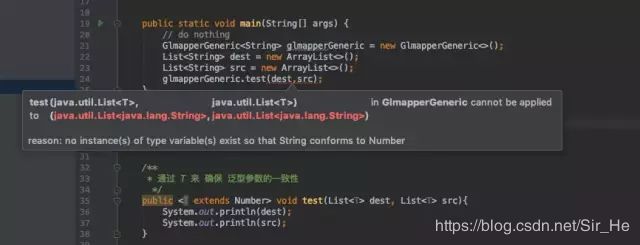
不能保证两个 List 具有相同的元素类型的情况

区别2:类型参数可以多重限定而通配符不行
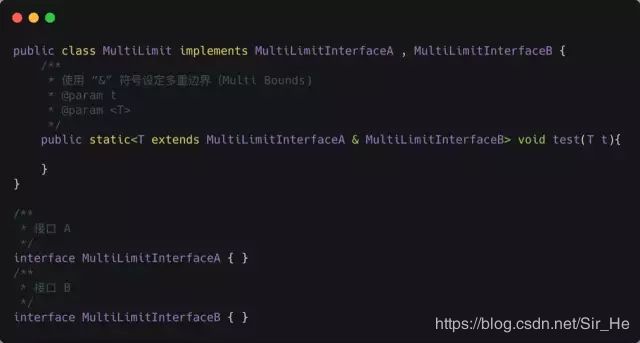
使用 & 符号设定多重边界(Multi Bounds),指定泛型类型 T 必须是 MultiLimitInterfaceA 和 MultiLimitInterfaceB 的共有子类型【子类型 : 强调的是新类具有父类一样的行为(未必是继承)】,此时变量 t 就具有了所有限定的方法和属性。对于通配符来说,因为它不是一个确定的类型,所以不能进行多重限定。
区别3:通配符可以使用超类限定而类型参数不行
类型参数 T 只具有 一种 类型限定方式:
T extends A
但是通配符 ? 可以进行 两种限定:
?extends A
? super A
Class 和 Class 区别
前面介绍了 ?和 T 的区别,那么对于, Class 和
最常见的是在反射场景下的使用,这里以用一段发射的代码来说明下。

对于上述代码,在运行期,如果反射的类型不是 MultiLimit 类,那么一定会报 java.lang.ClassCastException 错误。
对于这种情况,则可以使用下面的代码来代替,使得在在编译期就能直接 检查到类型的问题:

Class 在实例化的时候,T 要替换成具体类。Class 它是个通配泛型,? 可以代表任何类型,所以主要用于声明时的限制情况。比如,我们可以这样做申明:

所以当不知道定声明什么类型的 Class 的时候可以定义一 个Class。

那如果也想 publicClassclazzT; 这样的话,就必须让当前的类也指定 T 。

- 泛型接口
- 泛型方法
- 泛型数组
7.Java反射
-
ClassLoader.loadClass和Class.forName的区别
两者最大的区别
Class.forName得到的class是已经初始化完成的Classloder.loaderClass得到的class是还没有链接的
怎么使用
有些情况是只需要知道这个类的存在而不需要初始化的情况使用Classloder.loaderClass,而有些时候又必须执行初始化就选择Class.forName
详情参考
ClassLoader 做什么的?
顾名思义,它是用来加载 Class 的。它负责将 Class 的字节码形式转换成内存形式的 Class 对象。字节码可以来自于磁盘文件
*.class,也可以是 jar 包里的 *.class,也可以来自远程服务器提供的字节流,字节码的本质就是一个字节数组 []byte,它有特定的复杂的内部格式。有很多字节码加密技术就是依靠定制 ClassLoader 来实现的。先使用工具对字节码文件进行加密,运行时使用定制的 ClassLoader
先解密文件内容再加载这些解密后的字节码。
每个 Class 对象的内部都有一个 classLoader 字段来标识自己是由哪个 ClassLoader 加载的。
class Class { … private final ClassLoader classLoader; … }
延迟加载
JVM 运行并不是一次性加载所需要的全部类的,它是按需加载,也就是延迟加载。程序在运行的过程中会逐渐遇到很多不认识的新类,这时候就会调用ClassLoader 来加载这些类。加载完成后就会将 Class 对象存在 ClassLoader 里面,下次就不需要重新加载了。//
比如你在调用某个类的静态方法时,首先这个类肯定是需要被加载的,但是并不会触及这个类的实例字段,那么实例字段的类别 Class 就可以暂时不必去加载,但是它可能会加载静态字段相关的类别,因为静态方法会访问静态字段。而实例字段的类别需要等到你实例化对象的时候才可能会加载。
各司其职
JVM 运行实例中会存在多个 ClassLoader,不同的 ClassLoader
会从不同的地方加载字节码文件。它可以从不同的文件目录加载,也可以从不同的 jar 文件中加载,也可以从网络上不同的服务地址来加载。JVM 中内置了三个重要的 ClassLoader,分别是
BootstrapClassLoader、ExtensionClassLoader 和 AppClassLoader。
BootstrapClassLoader 负责加载 JVM 运行时核心类,这些类位于 JAVA_HOME/lib/rt.jar
文件中,我们常用内置库 java.xxx.* 都在里面,比如
java.util.、java.io.、java.nio.、java.lang. 等等。这个 ClassLoader
比较特殊,它是由 C 代码实现的,我们将它称之为「根加载器」。ExtensionClassLoader 负责加载 JVM 扩展类,比如 swing 系列、内置的 js 引擎、xml 解析器
等等,这些库名通常以 javax 开头,它们的 jar 包位于 JAVA_HOME/lib/ext/*.jar 中,有很多 jar 包。AppClassLoader 才是直接面向我们用户的加载器,它会加载 Classpath 环境变量里定义的路径中的 jar 包和目录。我们自己编写的代码以及使用的第三方 jar 包通常都是由它来加载的。
那些位于网络上静态文件服务器提供的 jar 包和 class文件,jdk 内置了一个 URLClassLoader,用户只需要传递规范的网络路径给构造器,就可以使用 URLClassLoader 来加载远程类库了。URLClassLoader 不但可以加载远程类库,还可以加载本地路径的类库,取决于构造器中不同的地址形式。ExtensionClassLoader 和 AppClassLoader 都是 URLClassLoader 的子类,它们都是从本地文件系统里加载类库。
AppClassLoader 可以由 ClassLoader 类提供的静态方法 getSystemClassLoader() 得到,它就是我们所说的「系统类加载器」,我们用户平时编写的类代码通常都是由它加载的。当我们的 main 方法执行的时候,这第一个用户类的加载器就是 AppClassLoader。
ClassLoader 传递性
程序在运行过程中,遇到了一个未知的类,它会选择哪个 ClassLoader 来加载它呢?虚拟机的策略是使用调用者 Class 对象的 ClassLoader 来加载当前未知的类。何为调用者 Class 对象?就是在遇到这个未知的类时,虚拟机肯定正在运行一个方法调用(静态方法或者实例方法),这个方法挂在哪个类上面,那这个类就是调用者 Class 对象。前面我们提到每个 Class 对象里面都有一个 classLoader 属性记录了当前的类是由谁来加载的。
因为 ClassLoader 的传递性,所有延迟加载的类都会由初始调用 main 方法的这个 ClassLoader 全全负责,它就是 AppClassLoader。
双亲委派
前面我们提到 AppClassLoader 只负责加载 Classpath 下面的类库,如果遇到没有加载的系统类库怎么办,AppClassLoader 必须将系统类库的加载工作交给 BootstrapClassLoader 和 ExtensionClassLoader 来做,这就是我们常说的「双亲委派」。
AppClassLoader 在加载一个未知的类名时,它并不是立即去搜寻 Classpath,它会首先将这个类名称交给 ExtensionClassLoader 来加载,如果 ExtensionClassLoader 可以加载,那么 AppClassLoader 就不用麻烦了。否则它就会搜索 Classpath 。
而 ExtensionClassLoader 在加载一个未知的类名时,它也并不是立即搜寻 ext 路径,它会首先将类名称交给 BootstrapClassLoader 来加载,如果 BootstrapClassLoader 可以加载,那么 ExtensionClassLoader 也就不用麻烦了。否则它就会搜索 ext 路径下的 jar 包。
这三个 ClassLoader 之间形成了级联的父子关系,每个 ClassLoader 都很懒,尽量把工作交给父亲做,父亲干不了了自己才会干。每个 ClassLoader 对象内部都会有一个 parent 属性指向它的父加载器。
class ClassLoader {
…
private final ClassLoader parent;
…
}
值得注意的是图中的 ExtensionClassLoader 的 parent 指针画了虚线,这是因为它的 parent 的值是 null,当 parent 字段是 null 时就表示它的父加载器是「根加载器」。如果某个 Class 对象的 classLoader 属性值是 null,那么就表示这个类也是「根加载器」加载的。
Class.forName
当我们在使用 jdbc 驱动时,经常会使用 Class.forName 方法来动态加载驱动类。
Class.forName(“com.mysql.cj.jdbc.Driver”);
其原理是 mysql 驱动的 Driver 类里有一个静态代码块,它会在 Driver 类被加载的时候执行。这个静态代码块会将 mysql 驱动实例注册到全局的 jdbc 驱动管理器里。
class Driver {
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException(“Can’t register driver!”);
}
}
…
}
forName 方法同样也是使用调用者 Class 对象的 ClassLoader 来加载目标类。不过 forName 还提供了多参数版本,可以指定使用哪个 ClassLoader 来加载
Class forName(String name, boolean initialize, ClassLoader cl)
通过这种形式的 forName 方法可以突破内置加载器的限制,通过使用自定类加载器允许我们自由加载其它任意来源的类库。根据 ClassLoader 的传递性,目标类库传递引用到的其它类库也将会使用自定义加载器加载。
自定义加载器
ClassLoader 里面有三个重要的方法 loadClass()、findClass() 和 defineClass()。
loadClass() 方法是加载目标类的入口,它首先会查找当前 ClassLoader 以及它的双亲里面是否已经加载了目标类,如果没有找到就会让双亲尝试加载,如果双亲都加载不了,就会调用 findClass() 让自定义加载器自己来加载目标类。ClassLoader 的 findClass() 方法是需要子类来覆盖的,不同的加载器将使用不同的逻辑来获取目标类的字节码。拿到这个字节码之后再调用 defineClass() 方法将字节码转换成 Class 对象。下面我使用伪代码表示一下基本过程
class ClassLoader {
// 加载入口,定义了双亲委派规则
Class loadClass(String name) {
// 是否已经加载了
Class t = this.findFromLoaded(name);
if(t == null) {
// 交给双亲
t = this.parent.loadClass(name)
}
if(t == null) {
// 双亲都不行,只能靠自己了
t = this.findClass(name);
}
return t;
}
// 交给子类自己去实现
Class findClass(String name) {
throw ClassNotFoundException();
}
// 组装Class对象
Class defineClass(byte[] code, String name) {
return buildClassFromCode(code, name);
}
}
class CustomClassLoader extends ClassLoader {
Class findClass(String name) {
// 寻找字节码
byte[] code = findCodeFromSomewhere(name);
// 组装Class对象
return this.defineClass(code, name);
}
}
自定义类加载器不易破坏双亲委派规则,不要轻易覆盖 loadClass 方法。否则可能会导致自定义加载器无法加载内置的核心类库。在使用自定义加载器时,要明确好它的父加载器是谁,将父加载器通过子类的构造器传入。如果父类加载器是 null,那就表示父加载器是「根加载器」。
// ClassLoader 构造器
protected ClassLoader(String name, ClassLoader parent);
双亲委派规则可能会变成三亲委派,四亲委派,取决于你使用的父加载器是谁,它会一直递归委派到根加载器。
Class.forName vs ClassLoader.loadClass
这两个方法都可以用来加载目标类,它们之间有一个小小的区别,那就是 Class.forName() 方法可以获取原生类型的 Class,而 ClassLoader.loadClass() 则会报错。
Class x = Class.forName("[I");
System.out.println(x);
x = ClassLoader.getSystemClassLoader().loadClass("[I");
System.out.println(x);
class [I
Exception in thread “main” java.lang.ClassNotFoundException: [I
…
作者-码洞
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
- Markdown
- Text-to- HTML conversion tool
- Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎