Java 大数据【Hadoop 安装入门】
一、开始
1.创建用户及权限
$ adduser hadoop # 添加用户名
$ passwd hadoop # 添加密码
$ su - hadoop # 切换用户
$ sudo ls –la /root # 确认成功
2.添加权限
有时会提示没有权限,切换到 root
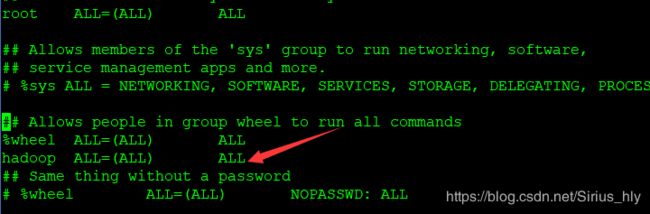
$ visudo
找到 root ALL = (ALL) ALL
在98行,在键盘上输入:98,然后按回车就能跳到,然后添加箭头所指的内容,空格为Tab,然后 :wq 退出。
3.安装 ssh
如果有 client 和 server 表示不需要安装
$ rpm -qa | grep ssh

如果需要安装,安装命令
$ sudo yum install openssh-clients
$ sudo yum install openssh-server
查看是否可用
$ ssh localhost
第一次登陆需要密码
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat id_rsa.pub >> authorized_keys # 加入授权
$ chmod 600 ./authorized_keys # 修改文件权限
4.安装 Java 环境
CentOS 安装 JDK
5.安装 Hadoop
http://mirror.bit.edu.cn/apache/hadoop/common/
注意不要下载错了,下载完成后,可以复制到 CentOS 服务器,然后解压。

$ sudo tar -zxf ~/下载/hadoop-2.6.5.tar.gz -C /usr/local
$ sudo mv ./hadoop-2.6.5/ ./hadoop # 将文件夹名改为 hadoop
$ sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
$ cd /usr/local/hadoop
查看版本
$ ./bin/hadoop version
6. Hadoop 伪分布式配置
配置文件目录,
vim /usr/local/hadoop/etc/hadoop/core-site.xml
修改配置文件 core-site.xml
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
修改配置文件 hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
配置完成后,执行 NameNode 的格式化
在 hadoop 解压目录下执行
$ ./bin/hdfs namenode -format
开启 NaneNode 和 DataNode 守护进程
$ ./sbin/start-dfs.sh
伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录
$ ./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
$ ./bin/hdfs dfs -mkdir input
$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml input
查看 HDFS 中的文件列表
$ ./bin/hdfs dfs -ls input
7. 启动 YARN
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行 于 MapReduce 之上,提供了高可用性、高扩展性。
首先修改配置文件 mapred-site.xml,这边需要先进行重命名:
$ mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
$ vim ./etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
修改配置文件 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
启动YARN,stop 为停止
$ ./sbin/start-yarn.sh
#开启历史服务器,才能在Web中查看任务运行情况
./sbin/mr-jobhistory-daemon.sh start historyserver
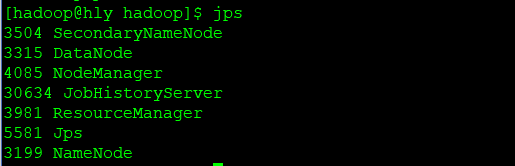
开启后通过 jps 查看,可以看到多了 NodeManager 和 ResourceManager 两个后台进程,如下图所示。
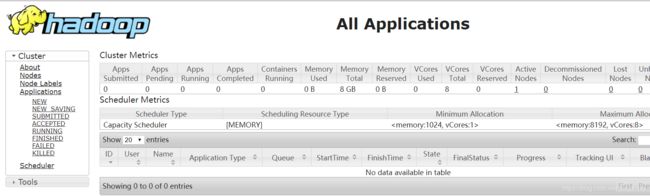
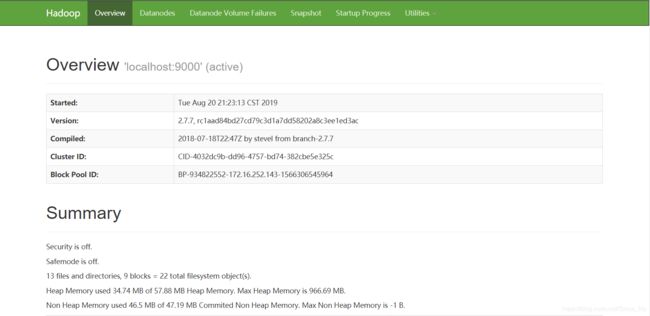
访问一下地址可查看任务运行情况
http://123.56.***:8088/cluster
http://123.56.***:50070
如果没有响应,则可以查看一下端口,看有没有启动,如果启动了,又访问不到,可能是防火墙问题,看看阿里云端口有没有开启。
netstat -anp | grep 50070
参考资料
如何安装 : https://blog.csdn.net/jimuka_liu/article/details/82784313
JAVA_HOME 问题 : https://www.cnblogs.com/codeOfLife/p/5940642.
关于
我的 Github:Github
CSDN: CSDN
个人网站: sirius 的博客
E-mail: [email protected]
推荐阅读
史上最全,最完美的 JAVA 技术体系思维导图总结,没有之一!