本地环境虚拟机部署hadoop集群
1 环境
1.1 实体电脑
Windows10操作系统 4核CPU 8G内存
安装Vmware 14.0.0
1.2 虚拟机
在Vmware上建两台虚拟机(可以创建好一台,JAVA hadoop等安装好、hadoop配置配好之后再通过克隆快照的方式克隆另一台虚拟机),一台做namenode和datanode,另一台只做datanode配置如下:
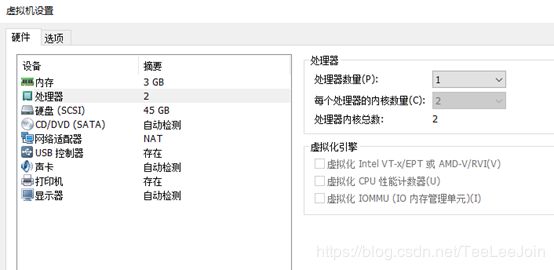
Ubuntu19.04操作系统 2核CPU 3G内存 45GB硬盘 网络模式NAT
2 安装
2.1 安装一台虚拟机
下载并安装好Vmware 14.0.0,下载地址:
百度云盘 https://pan.baidu.com/s/1yC6FrsfAMu7gVdkV0Eyrgg
提取码:eyko
下载ubuntu19.04,可以选desktop类型的,安装好后有图形界面,下载地址:
官网 https://ubuntu.com/download/desktop
清华大学镜像 https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/19.04/
百度云盘 https://pan.baidu.com/s/1RljTRMegFe64N7cfciX_rg
提取码:u8i0
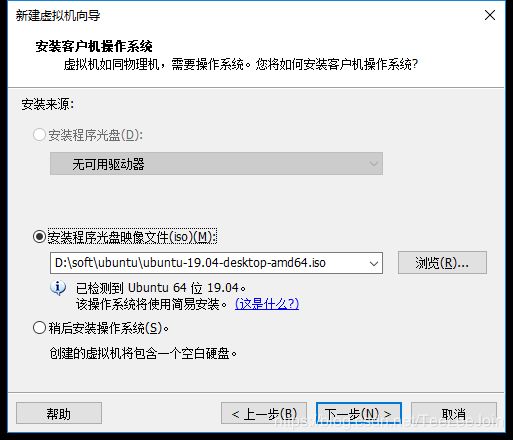
下载好ios镜像之后,在Vmware上用该镜像创建虚拟机,安装过程不在此描述,安装时其中有一步是选择映像文件的,选下载好的ios
2.2 本机和虚拟机设置目录共享
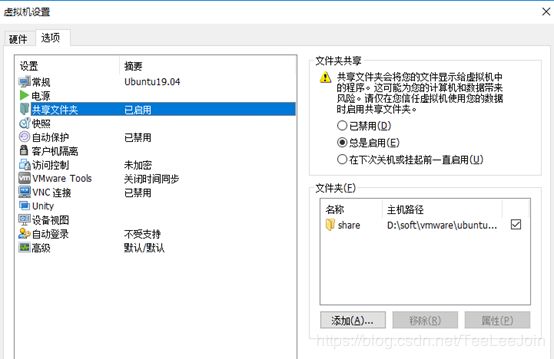
将本机的某个目录共享给Vmware中的虚拟机,比如:我用D:\soft\vmware\ubuntu\share作为共享的文件夹,方便在windows上下载软件之后,在ubuntu上可以直接使用。
在虚拟机设置中启用共享文件夹,并指定文件夹的主机路径:
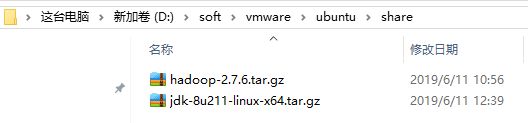
在主机路径中放入要共享的内容:
在ubuntu系统的 /mnt/hgfs/share中能看到共享的内容:
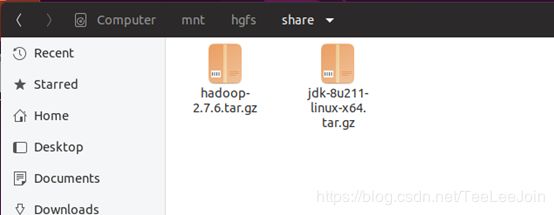
2.3 安装和配置JAVA
下载地址:
官网 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 选 jdk-8u211-linux-x64.tar.gz
百度云盘 https://pan.baidu.com/s/1WQM5z34qKenKKlWGHn4HLw
提取码:4jtv
在windows上下载后,放到共享目录中,在ubuntu上用命令行工具进入到 /mnt/hgfs/share,找到jdk-8u211-linux-x64.tar.gz,
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-8u211-linux-x64.tar.gz -C /usr/lib/jvm #解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.8.0_211 java #重命名为java
$ vi ~/.bashrc #给JDK配置环境变量
如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 sudo -i 语句进入root账户来操作。
在.bashrc文件添加如下指令:
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
在文件修改完毕以后,输入代码:
$ source ~/.bashrc #使新配置的环境变量生效
$ java -version #检测是否安装成功,查看java版本
能正常显示java版本即表示jdk安装成功

2.4 创建HADOOP用户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
$ su - hadoop #切换当前用户为用户hadoop
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装
2.5 安装SSH,设置SSH无密码登陆
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa
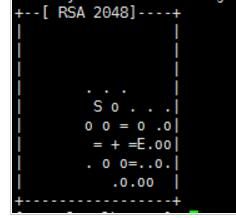
输入完 $ ssh-keygen -t rsa 语句以后,需要连续敲击三次回车,如下图:

其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。两次回车输入完毕以后,如果出现类似于下图所示的输出,即成功:
之后再输入:
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost #此时已不需密码即可登录localhost,并可见下图。如果失败则可以搜索SSH免密码登录来寻求答案

2.6 安装和配置hadoop
官网推荐地址 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
百度云盘 https://pan.baidu.com/s/12CoREFFszc-MUjRPHzutVQ
提取码:5zq9
我用的是2.7.6版本
在windows上下载后,放到共享目录中,在ubuntu上用命令行工具进入到 /mnt/hgfs/share,找到hadoop-2.7.6.tar.gz,
$ sudo tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local
$ sudo mv hadoop-2.7.6 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"

执行source ~/.bashrc使设置生效,并用hadoop version查看hadoop是否安装成功

2.7 Hadoop分布式配置
至少需要两台虚拟机,一台作为namenode和datanode,一台仅作为datanode,本例以说明namenode所在的机器配置为主,datanode机器通过虚拟机克隆的方式可以完整的克隆所有的软件和配置。
需要配置的虚拟机文件主要有两个
/etc/hosts 和 /etc/hostname
[注]: 配置host和hostname时,切换到root用户再做配置
sudo -i
需要配置的hadoop文件主要包括
一个sh:
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
四个xml :
$HADOOP_HOME/etc/hadoop/core-site.xml,
$HADOOP_HOME/etc/hadoop/hdfs-site.xml,
$HADOOP_HOME/etc/hadoop/yarn-site.xml,
$HADOOP_HOME/etc/hadoop/mapred-site.xml
和一个
$HADOOP_HOME/etc/hadoop/slaves
[注]: 配置hadoop文件时,切换到hadoop用户再做配置
su – hadoop
2.7.1 /etc/hostname
$ sudo vi /etc/hostname #修改机器名称
在文本中输入 : namenode ,将机器名命为namenode
$ sudo reboot #重启使hostname更改生效
2.7.2 /etc/hosts
$ sudo vi /etc/hosts
#注意hosts是s结尾的,打开之后里面是有内容的,不要vi /etc/host
在原文本内容中删除127.0.0.1的配置项(一定要删,不然在格式化hadoop后,pool_id会带有127.0.0.1信息,导致其他机器上的datanode在找namenode时通过127.0.0.1找),补充namenode项,此时datanode的地址不知道,先不配置,等 虚拟机克隆 环节处理完之后,再回来配置。ip地址就是虚拟机实际的地址,可用ifconfig查看。

2.7.3 hadoop-env.sh
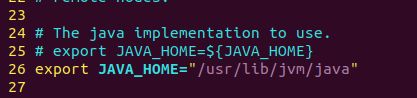
$ vi hadoop-env.sh
在文本中补充 : export JAVA_HOME=/usr/lib/jvm/java
2.7.4 core-site.xml
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://namenode:9000

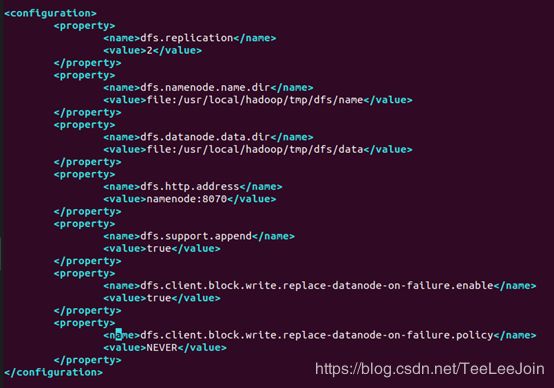
2.7.5 hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
dfs.http.address
namenode:8070
dfs.support.append
true
dfs.client.block.write.replace-datanode-on-failure.enable
true
dfs.client.block.write.replace-datanode-on-failure.policy
NEVER
2.7.6 yarn-site.xml
yarn.resourcemanager.hostname
namenode
yarn.nodemanager.aux-services
mapreduce_shuffle

2.7.7 mapred-site.xml
默认文件名为 mapred-site.xml.template,需拷贝一份再修改
mapreduce.framework.name
yarn
mapreduce.jobhistory.address q
namenode:10020
mapreduce.jobhistory.webapp.address
namenode:19888

2.7.8 slaves
将 DataNode 的主机名(就是/etc/hostname)写入该文件,每行一个,我们是两台数据节点,写两行(namenode也作为数据节点)

2.8 虚拟机克隆
配置好之后,将虚拟机克隆,作为独立的datanode,并且配置其hostname为datanode。
虚拟机关机->在虚拟机名称上右键->快照->快照管理器

在快照管理器面板中选->克隆

按提示操作,在选择【克隆类型】时,选【创建完整克隆】,按提示继续

克隆完成之后,就有了两台虚拟机

2.9 克隆后的配置更新
被克隆的机器是namenode节点(同时也是datanode),克隆出来的机器仅是datanode节点。
到namenode机器,补充修改/etc/hosts,添加datanode的地址,最终namenode中的hosts要包含namenode和datanode两项

到datanode机器,修改/etc/hostname,将name改为datanode,修改/etc/hosts,添加namenode和datanode两行配置
2.10 格式化和启动
在namenode机器,执行
$ hdfs namenode -format
进行格式化
在namenode机器,执行
$ cd /usr/local/hadoop/sbin #进入可执行脚本目录
$ ./start-all.sh #执行启动全部
执行完启动之后,在namenode执行
$ jps #查看进程
列表如下:
NameNode ResourceManager DataNode NodeManager SecondaryNameNode
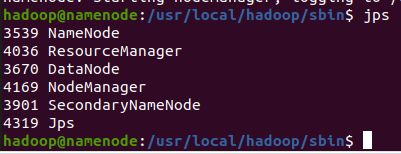
在datanode机器上执行
$ jps #查看进程
列表如下:

也可以通过访问hdfs webui查看namenode和datanode的信息,访问地址是hdfs-site.xml中配置的这个地址:
dfs.http.address
namenode:8070
如果没用这个项没配置的话,默认端口是50070

另:执行格式化完之后
hdfs-site.xml中配置的这个地址下
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
会有个current目录,目录下有VERSION文件,打开该文件,里面有clusterID和blockpoolID等信息,在所有的datanode和namenode中,VERSION文件的clusterID在每个机器上都要是一样的。
namenode VERSION文件

datanode VERSION文件

datanode的data目录下会有一个带有blockpoolID标识的目录
![]()
2.11 测试
在namenode机器上,切换到hadoop用户
$ su - hadoop
上传文件
$ hdfs dfs -mkdir /dir #创建目录
$ hdfs dfs -put /usr/local/hadoop/sbin/start-all.sh /dir #上传文件到dir目录
查看文件
$ hdfs dfs -cat /dir/start-all.sh
也可以通过页面查看
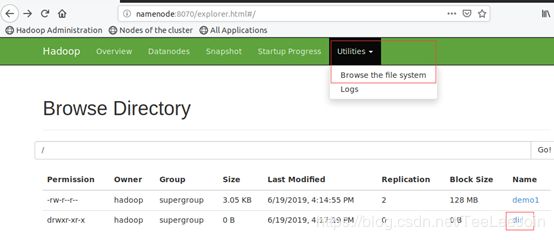
3 一些命令
(如果直接拷贝运行报命令识别不了,则手工命令)
hdfs dfsadmin -refreshNodes #刷新节点,在动态添加或删除了datanode之后,可能会用到
hdfs dfsadmin -report #查看挂载的datanode信息
hadoop-daemons.sh start datanode #sbin目录下的,启动数据节点daemons是带s的那个,执行命令时会去读slaves配置文件,把里面配置的节点都执行一遍,如果在datanode机器上只想启停本机器的程序,则在slaves文件中只配置本机器
hadoop-daemons.sh stop datanode #关闭数据节点
4 过程中遇到的问题和处理
4.1 /etc/hosts和/etc/host
修改host时,vi /etc/host,漏了后面的s,相当于创建了一个新文件,配置完之后,导致sudo –i命令很久才有响应,且在namenode上不能正确的ping通datanode,报 Temporary failure in name resolution 错误,后面是 ll /etc/host时才发现的。
4.2 HADOOP_OPTS
在~/.bashrc中配置环境变量时,漏了HADOOP_OPTS配置项,导致在datanode机器上执行hadoop-daemons.sh start datanode启动数据节点时,报错:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform
4.3 hosts中的127.0.0.1
明明在namenode机器上slaves配置了两个节点,两台机器上执行jps命令也能看到datanode进程,但是在执行hdfs dfsadmin –report时,只能看到namenode所在机器的1个datanode,远程的那个datanode挂载不上。
查看在datanode所在的机器上,查看$HADOOP_HOST/logs/hadoop-hadoop-datanode-datanode.log日志,在日志中发现大量连接127.0.0.1的日志,才怀疑配置可能有问题,而且此时,在datanode的data目录下带有blockpoolID标识的目录名称是127.0.0.1的。
处理时将namenode和datanode下/etc/hosts中的127.0.0.1的配置删除,把namenode和datanode的file:/usr/local/hadoop/tmp/dfs/name(即hdfs-site.xml中配置项dfs.namenode.name.dir)和file:/usr/local/hadoop/tmp/dfs/data(即hdfs-site.xml中配置项dfs.namenode.data.dir)目录删掉,重新格式化namenode,重新启动hadoop。
5 参考文档
官方网站安装说明 :
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
87hbteo的博文:Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境) https://www.cnblogs.com/87hbteo/p/7606012.html