佛爷带你被玩火速封杀的Deepfake黑科技,用FakeApp深度换脸
介绍
Deepfake是一种人工智能基础的人物图像合成技术。它用于使用称为“ 生成对抗性网络 ”(GAN)的机器学习技术将现有图像和视频组合并叠加到源图像或视频上。现有视频和源视频的组合产生假视频,该视频显示在现实中从未发生过的事件中执行动作的一个或多个人。
例如,可以创建这样的假视频,以显示执行他们从未参与的性行为的人,或者可以用于改变政治家用来使其看起来像那个人说他们从未做过的事情的文字或手势。由于这些功能,Deepfake可能被用来制作虚假的名人色情视频或报复色情内容。Deepfakes也可用于制作假新闻和恶意恶作剧。
其一问世就被钉上了如此耻辱柱,现在在国内这项技术是已经被封了的。但是从科技的角度来看,这到底是人类的问题还是技术的无耻,我相信技术无罪就足够了。
2018年1月,推出了名为FakeApp的桌面应用程序。该应用程序允许用户轻松创建和分享面部交换的视频。该应用程序使用人工神经网络和图形处理器的功能以及3到4千兆字节的存储空间来生成虚假视频。对于详细信息,程序需要来自要插入的人的大量视觉材料,以便使用基于视频序列和图像的深度学习算法来学习必须交换哪些图像方面。
该软件使用了AI-框架TensorFlow的谷歌,这除其他外已经用于程序DeepDream。名人是这类假视频的主要目标,但其他一些人也受到影响。2018年8月,加州大学伯克利分校的研究人员发表了一篇论文,介绍了一种虚假的舞蹈应用程序,可以使用人工智能创造出高超的舞蹈能力。
这是一篇Fake APP的教程,自然现在开始言归正传。毫无疑问,创建Deepfakes的最容易获得的应用程序是FakeApp,它最近达到2.2版本。本教程将向您展示如何安装和使用它。(先提前说一声,玩这个需要你是机器学习或者深度学习的爱好者, 稍微懂点编程, 虽然FakeApp不用编程,但是其他更好的技术就需要编程了; 有一台Window10电脑, GPU(没有GPU就不要玩了,CPU训练太慢了))
安装
步骤1. 安装NVidia CUDA9
FakeApp依赖于神经网络,这种网络的训练成本非常高。尽管它们有成本,但训练神经网络的过程是高度可并行的。出于这个原因,大多数机器学习框架(如Keras和TernsorFlow)可以分派在计算GPU。GPU代表 图形处理单元,是机器内部通常处理图形输入的芯片。
GPU被设计为并行执行操作,因此它们非常适合训练建立在并行工作的独立神经元上的神经网络。FakeApp使用TensorFlow,一种机器学习框架,支持使用NVIDIA显卡进行GPU加速计算。但是,在使用它之前,您需要安装CUDA®,这是一个将密集计算委派给NVIDIA GPU的并行计算平台。
检查你的显卡。 并非NVIDIA的所有显卡都集成了对GPU计算的支持。您可以检查您的GPU是否兼容访问CUDA GPU列表。任何计算能力大于或等于3.0的图形卡都可以使用。
安装CUDA®Toolkit9.0, 官网直接去下载。确保为CUDA和操作系统选择正确的版本。

您可以选择您喜欢的任何安装程序类型。“exe(local)”将首先下载整个安装程序。该文件相当大,所以准备等待。
在安装过程中,选择“自定义”选项并选择其所有组件。
**安装cuDNN。**虽然CUDA®Toolkit提供了GPU计算所需的基本工具集,但它不包括某些特定任务的库。ML-Agents使用强化学习来训练神经网络。因此,您还需要下载CUDA®对深度神经网络的支持,也称为cuDNN。
下载cuDNN需要登录。您可以作为NVIDIA开发者免费注册,然后再次访问该网页以访问下载链接。FakeApp适用于cuDNN 7,因此请务必选择正确的版本。
本人Cuda版本:V9.0.176(我是成功实现FakeApp的使用,所以在配置上如果你不能准确配置,请和我的一样)
第2步. 安装FakeApp
尽管仍需要一些配置,但安装FakeApp是最简单的步骤。可以从FakeApp下载页面下载(www.fakeapp.org (不用想了,已经是上不去的了。如果想下,自行找办法吧,网上有的是办法下载,你懂的))安装程序。
您需要下载两个文件。一个是FakeApp二进制文件的实际安装程序,而另一个名为core.zip,包含它所需的所有依赖项。解压缩后,其所有内容都应合并到C:\Users[USER]\AppData\Local\FakeApp\app-2.2.0\resources\api 文件夹,它应如下所示:
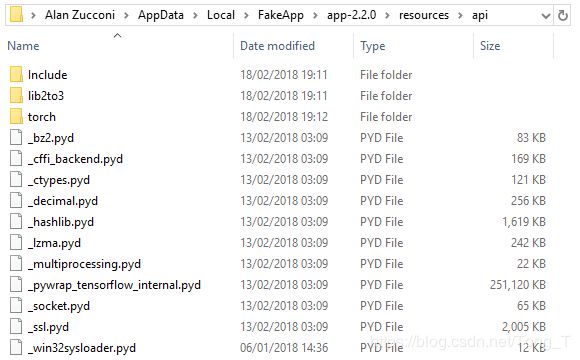
如果一切正常,您现在应该可以使用FakeApp。
使用
步骤1. 提取
为了训练您的模型,FakeApp需要大量的图像数据集。除非您已经选择了数百张图片,否则FakeApp会提供一个便捷功能,可以从视频中提取所有帧。这可以在GET DATASET选项卡中完成。您只需指定mp4视频的链接即可。单击EXTRACT将启动该过程。
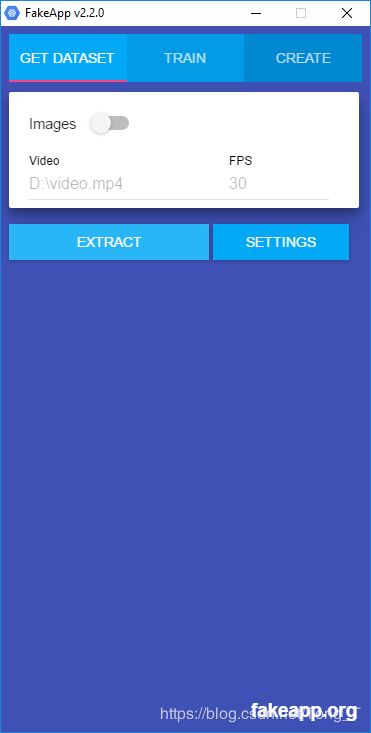
如果您的原始视频名为movie.mp4,则会在名为dataset-video的文件夹中提取这些帧。在里面,会有另一个名为extract的文件夹 ,其中包含准备在训练过程中使用的对齐图像。您可能还会看到一个名为alignments.json的文件,该文件为每个对齐的帧指示其在提取它的图像中的原始位置。
提取过程完成后,您唯一需要的是 extract 文件夹; 你可以删除所有其他文件。在继续下一步之前,只需确保对齐的面确实对齐(下图)。面部检测经常失败,因此需要一些手动工作。

理想情况下,您需要的是人A的视频和人B的视频。然后,您需要运行该过程两次,以获得两个文件夹。如果您有同一个人的多个视频,请提取所有这些视频合并文件夹。或者,您可以使用Movie Maker或等效程序依次附加视频。
第2步. 训练
在FakeApp中,您可以从TRAIN选项卡训练您的模型。在数据A和数据B下, 您需要复制解压缩文件夹的路径。按照惯例,数据A是从背景视频中提取的文件夹,数据B包含要插入数据A视频的人物的面部。训练过程将人A的面部转换为人B。实际上,神经网络在两个方向上工作; 你选择哪一个和你选择哪一个并不重要。
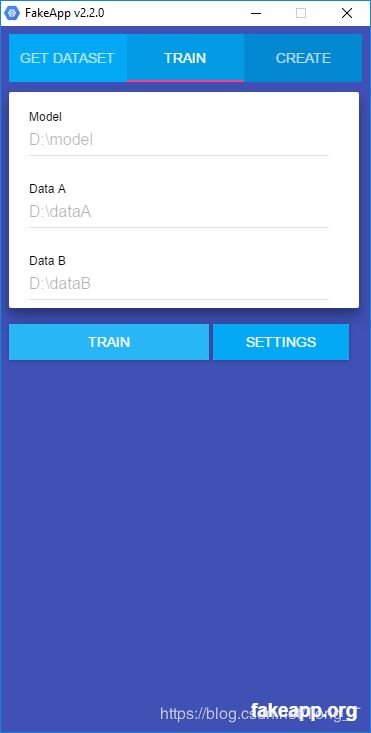
您还需要一个模型文件夹。如果这是您第一次从A人训练到B人,您可以使用空文件夹。FakeApp将使用它来存储训练好的神经网络的参数。
在开始此过程之前,需要设置训练设置。红色,下面,表示参考培训过程的那些。节点和层 用于配置神经网络; 批量大小用于在更多数量的面上训练它。
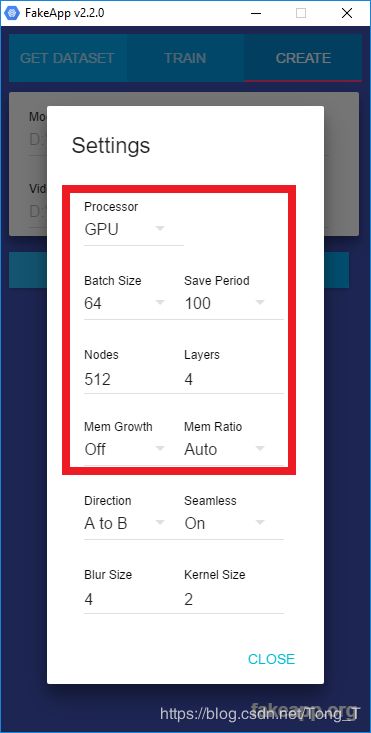
如果您的GPU的RAM少于2GB,那么您可以运行的最高设置可能是:
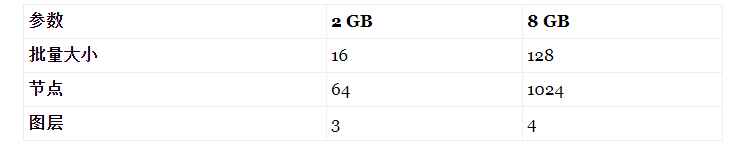
您必须根据GPU上可用的内存量来调整设置。这些是您通常应该运行的推荐设置,尽管这可能因您的型号而异。如果内存不足,则该过程将失败。
监控进度。 在训练时,您将看到一个窗口,显示神经网络的执行情况。

您可以随时按Q停止培训过程。要恢复它,只需使用与模型相同的文件夹再次启动它。FakeApp还显示一个分数,表示在尝试将人A重建为B而人B重建为A时所犯的错误。低于0.02的值通常被认为是可接受的。(至少15个小时以上)
第3步. 创作
创建视频的过程与GET DATASET中的过程非常相似。您需要提供mp4视频的路径以及模型的文件夹。这是一个包含文件的文件夹:encoder.h5,decoder_A.h5 和decoder_B.h5。您还需要指定目标FPS。
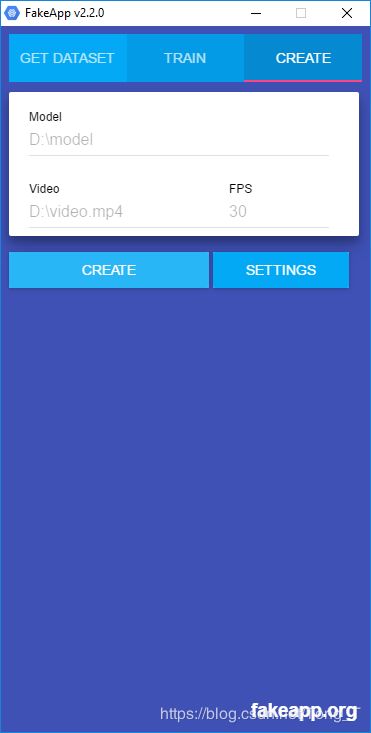
按CREATE将自动:
- 从workdir-video 文件夹中的源视频中提取所有帧,
- 裁剪所有面并在workdir-video / extracted 文件夹中对齐它们,裁剪所有面并在workdir-video / extracted 文件夹中对齐它们,
- 使用训练过的模型处理每个面部,使用训练过的模型处理每个面部,
- 将面合并回原始帧并将它们存储在workdir-video / merged 文件夹中,将面合并回原始帧并将它们存储在workdir-video / merged 文件夹中,
- 加入所有帧以创建最终视频。加入所有帧以创建最终视频。
在设置(下方)中,可以选择是否要将人A转换为人B(A至B)或人B转换为人A(B至A)。
结论:
这是我用GPU训练30小时的示例效果:
可以看得出来还是有部分是没有训练融合完整的。自然改进的方法除了增加训练样本,继续增加训练时间之外。还可以尝试更多deepfake的方式。
GAN的入门原理总结(其实不是深度学习算法从业者到这里就没必要看了)
Generative Adversarial Network,就是大家耳熟能详的 GAN,由 Ian Goodfellow 首先提出,在这两年更是深度学习中最热门的东西,仿佛什么东西都能由 GAN 做出来。我最近刚入门 GAN,看了些资料,做一些笔记。
1.Generation
什么是生成(generation)?就是模型通过学习一些数据,然后生成类似的数据。让机器看一些动物图片,然后自己来产生动物的图片,这就是生成。
以前就有很多可以用来生成的技术了,比如 auto-encoder(自编码器),结构如下图:
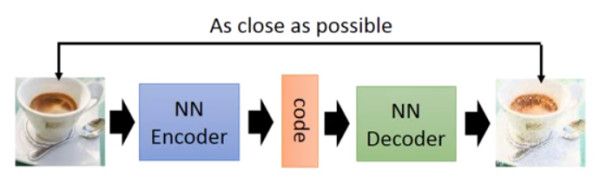
你训练一个 encoder,把 input 转换成 code,然后训练一个 decoder,把 code 转换成一个 image,然后计算得到的 image 和 input 之间的 MSE(mean square error),训练完这个 model 之后,取出后半部分 NN Decoder,输入一个随机的 code,就能 generate 一个 image。
但是 auto-encoder 生成 image 的效果,当然看着很别扭啦,一眼就能看出真假。所以后来还提出了比如VAE这样的生成模型,我对此也不是很了解,在这就不细说。
上述的这些生成模型,其实有一个非常严重的弊端。比如 VAE,它生成的 image 是希望和 input 越相似越好,但是 model 是如何来衡量这个相似呢?model 会计算一个 loss,采用的大多是 MSE,即每一个像素上的均方差。loss 小真的表示相似嘛?

比如这两张图,第一张,我们认为是好的生成图片,第二张是差的生成图片,但是对于上述的 model 来说,这两张图片计算出来的 loss 是一样大的,所以会认为是一样好的图片。
这就是上述生成模型的弊端,用来衡量生成图片好坏的标准并不能很好的完成想要实现的目的。于是就有了下面要讲的 GAN。
2.GAN
大名鼎鼎的 GAN 是如何生成图片的呢?首先大家都知道 GAN 有两个网络,一个是 generator,一个是 discriminator,从二人零和博弈中受启发,通过两个网络互相对抗来达到最好的生成效果。流程如下:
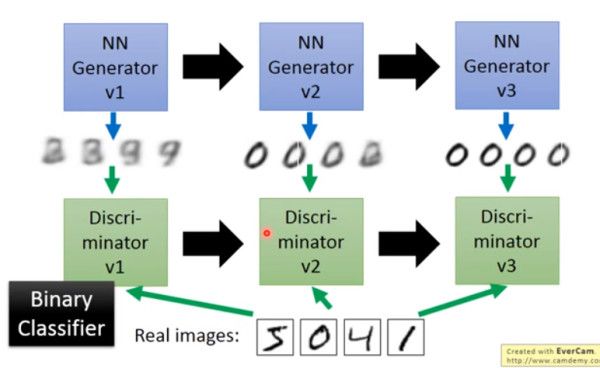
主要流程类似上面这个图。首先,有一个一代的 generator,它能生成一些很差的图片,然后有一个一代的 discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个 discriminator 就是一个二分类器,对生成的图片输出 0,对真实的图片输出 1。
接着,开始训练出二代的 generator,它能生成稍好一点的图片,能够让一代的 discriminator 认为这些生成的图片是真实的图片。然后会训练出一个二代的 discriminator,它能准确的识别出真实的图片,和二代 generator 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。
这就是 GAN,运行过程就是这么的简单。这就结束了嘛?显然没有,下面还要介绍一下 GAN 的原理。
3.原理
首先我们知道真实图片集的分布 Pdata(x),x 是一个真实图片,可以想象成一个向量,这个向量集合的分布就是 Pdata。我们需要生成一些也在这个分布内的图片,如果直接就是这个分布的话,怕是做不到的。
我们现在有的 generator 生成的分布可以假设为 PG(x;θ),这是一个由 θ 控制的分布,θ 是这个分布的参数(如果是高斯混合模型,那么 θ 就是每个高斯分布的平均值和方差)
假设我们在真实分布中取出一些数据,{x1, x2, ... , xm},我们想要计算一个似然 PG(xi; θ)。
对于这些数据,在生成模型中的似然就是
![]()
我们想要最大化这个似然,等价于让 generator 生成那些真实图片的概率最大。这就变成了一个最大似然估计的问题了,我们需要找到一个 θ* 来最大化这个似然。
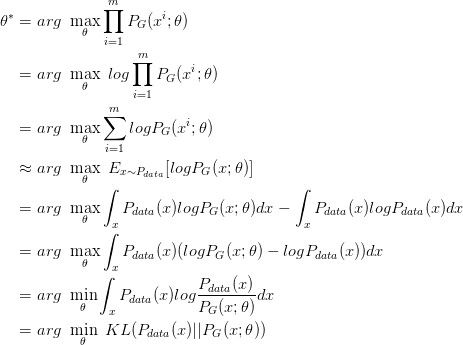
寻找一个 θ* 来最大化这个似然,等价于最大化 log 似然。因为此时这 m 个数据,是从真实分布中取的,所以也就约等于,真实分布中的所有 x 在 PG 分布中的 log 似然的期望。
真实分布中的所有 x 的期望,等价于求概率积分,所以可以转化成积分运算,因为减号后面的项和 θ 无关,所以添上之后还是等价的。然后提出共有的项,括号内的反转,max 变 min,就可以转化为 KL divergence 的形式了,KL divergence 描述的是两个概率分布之间的差异。
所以最大化似然,让 generator 最大概率的生成真实图片,也就是要找一个 θ 让 PG 更接近于 Pdata。
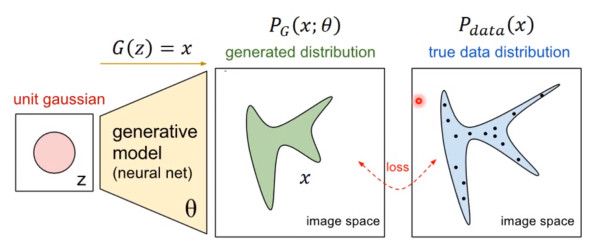
那如何来找这个最合理的 θ 呢?我们可以假设 PG(x; θ) 是一个神经网络。
首先随机一个向量 z,通过 G(z)=x 这个网络,生成图片 x,那么我们如何比较两个分布是否相似呢?只要我们取一组 sample z,这组 z 符合一个分布,那么通过网络就可以生成另一个分布 PG,然后来比较与真实分布 Pdata。
大家都知道,神经网络只要有非线性激活函数,就可以去拟合任意的函数,那么分布也是一样,所以可以用一直正态分布,或者高斯分布,取样去训练一个神经网络,学习到一个很复杂的分布。
如何来找到更接近的分布,这就是 GAN 的贡献了。先给出 GAN 的公式:
![]()
这个式子的好处在于,固定 G,max V(G,D) 就表示 PG 和 Pdata 之间的差异,然后要找一个最好的 G,让这个最大值最小,也就是两个分布之间的差异最小。
![]()
表面上看这个的意思是,D 要让这个式子尽可能的大,也就是对于 x 是真实分布中,D(x) 要接近与 1,对于 x 来自于生成的分布,D(x) 要接近于 0,然后 G 要让式子尽可能的小,让来自于生成分布中的 x,D(x) 尽可能的接近 1。
现在我们先固定 G,来求解最优的 D:


对于一个给定的 x,得到最优的 D 如上图,范围在 (0,1) 内,把最优的 D 带入
![]()
可以得到:

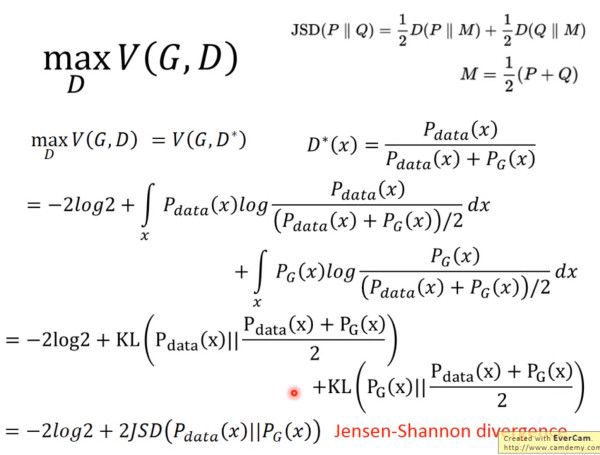
JS divergence 是 KL divergence 的对称平滑版本,表示了两个分布之间的差异,这个推导就表明了上面所说的,固定 G。
![]()
表示两个分布之间的差异,最小值是 -2log2,最大值为 0。
现在我们需要找个 G,来最小化
![]()
观察上式,当 PG(x)=Pdata(x) 时,G 是最优的。
4.训练
有了上面推导的基础之后,我们就可以开始训练 GAN 了。结合我们开头说的,两个网络交替训练,我们可以在起初有一个 G0 和 D0,先训练 D0 找到 :
![]()
然后固定 D0 开始训练 G0, 训练的过程都可以使用 gradient descent,以此类推,训练 D1,G1,D2,G2,...
但是这里有个问题就是,你可能在 D0* 的位置取到了:
![]()
然后更新 G0 为 G1,可能
![]()
了,但是并不保证会出现一个新的点 D1* 使得
![]()
这样更新 G 就没达到它原来应该要的效果,如下图所示:
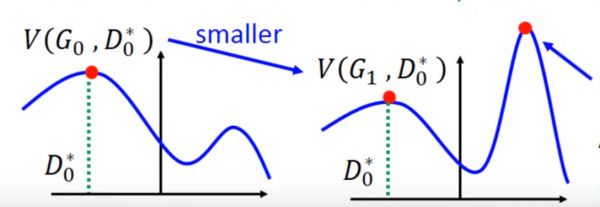
避免上述情况的方法就是更新 G 的时候,不要更新 G 太多。
知道了网络的训练顺序,我们还需要设定两个 loss function,一个是 D 的 loss,一个是 G 的 loss。下面是整个 GAN 的训练具体步骤:

上述步骤在机器学习和深度学习中也是非常常见,易于理解。
5.存在的问题
但是上面 G 的 loss function 还是有一点小问题,下图是两个函数的图像:
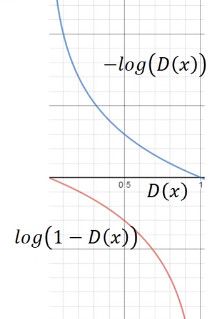
log(1-D(x)) 是我们计算时 G 的 loss function,但是我们发现,在 D(x) 接近于 0 的时候,这个函数十分平滑,梯度非常的小。这就会导致,在训练的初期,G 想要骗过 D,变化十分的缓慢,而上面的函数,趋势和下面的是一样的,都是递减的。但是它的优势是在 D(x) 接近 0 的时候,梯度很大,有利于训练,在 D(x) 越来越大之后,梯度减小,这也很符合实际,在初期应该训练速度更快,到后期速度减慢。
所以我们把 G 的 loss function 修改为
![]()
这样可以提高训练的速度。
还有一个问题,在其他 paper 中提出,就是经过实验发现,经过许多次训练,loss 一直都是平的,也就是
![]()
JS divergence 一直都是 log2,PG 和 Pdata 完全没有交集,但是实际上两个分布是有交集的,造成这个的原因是因为,我们无法真正计算期望和积分,只能使用 sample 的方法,如果训练的过拟合了,D 还是能够完全把两部分的点分开,如下图:
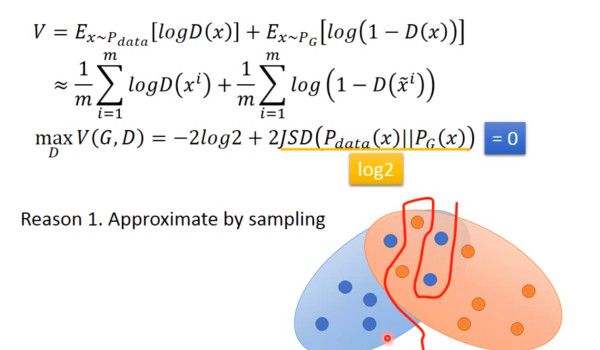
对于这个问题,我们是否应该让 D 变得弱一点,减弱它的分类能力,但是从理论上讲,为了让它能够有效的区分真假图片,我们又希望它能够 powerful,所以这里就产生了矛盾。
还有可能的原因是,虽然两个分布都是高维的,但是两个分布都十分的窄,可能交集相当小,这样也会导致 JS divergence 算出来 =log2,约等于没有交集。
解决的一些方法,有添加噪声,让两个分布变得更宽,可能可以增大它们的交集,这样 JS divergence 就可以计算,但是随着时间变化,噪声需要逐渐变小。
还有一个问题叫 Mode Collapse,如下图:
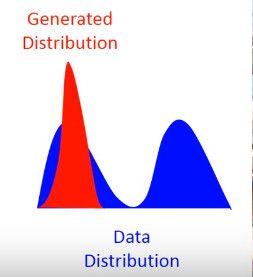
这个图的意思是,data 的分布是一个双峰的,但是学习到的生成分布却只有单峰,我们可以看到模型学到的数据,但是却不知道它没有学到的分布。
造成这个情况的原因是,KL divergence 里的两个分布写反了
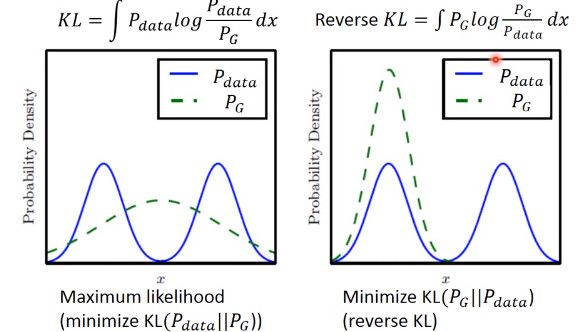
这个图很清楚的显示了,如果是第一个 KL divergence 的写法,为了防止出现无穷大,所以有 Pdata 出现的地方都必须要有 PG 覆盖,就不会出现 Mode Collapse。
机器学习参考教程
佛爷芸: 机器学习算法原理总结系列—算法基础之(1)机器学习介绍
机器学习算法原理总结系列—算法基础之(2)决策树(Decision Tree)
机器学习算法原理总结系列—算法基础之(3)随机森林(Random Forest)
机器学习算法原理总结系列—算法基础之(4)最邻近规则分类(K-Nearest Neighbor)
机器学习算法原理总结系列—算法基础之(5)朴素贝叶斯(Naive Bayesian)
机器学习算法原理总结系列—算法基础之(6)支持向量机(Support Vectors Machine)
机器学习算法原理总结系列—算法基础之(7)神经网络(Neural Network)
机器学习算法原理总结系列—算法基础之(8)简单线性回归(Simple Linear Regression)
机器学习算法原理总结系列—算法基础之(9)多元回归分析(Multiple Regression)
机器学习算法原理总结系列—算法基础之(10)非线性回归(Logistic Regression)
机器学习算法原理总结系列—算法基础之(11)聚类K均值(Clustering K-means)
机器学习算法原理总结系列—算法基础之(12)层次聚类(hierarchical clustering)
机器学习算法原理总结系列—算法基础之(13)模糊C均值聚类(Fuzzy C-means Clustering)