风控建模很难?一篇文章教你从0到1建立回归模型
⊙1. 回归模型 : 一场盛大的变量选秀
⊙ 2. 海选-精选-群组PK-联排
⊙ 3. 衡量模型效果的重要指标
⊙ 4. 总结与后续预告
在当今互联网经济及金融领域,“模型”是一个传播极为广泛的词汇,各种酷炫的模型应用也十分广泛。而在金融领域,特别是传统金融领域,模型的可解释性成为其应用中很重要的一个考虑因素,所以一些可解释性高的成熟模型方法称为了应用中的主力军。因此笔者这里就不费力阳春白雪,来试试下里巴人的路数,聊聊最为广泛应用的模型方法之一的逻辑回归模型的建模流程。
首先来谈谈“模型”,这个数据风控入门词汇。模型的建立是对于某个实际问题或客观事物、规律进行抽象后的一种形式化表达方式。
在数据分析领域,我所理解的模型是一个有多个输入,有涉及所有输入的加工计算过程,最后有输出的一个功能性模块。因此单一指标的判断规则不算模型,多个单一指标的判断规则组合(串联、并联、交叉……)后大概就能进入模型范畴了。然而为了保持“模型”一词的逼格,不让她成为落入凡间的仙子,我还是固执地把有一定方法理论基础,具备特有名词加持的模型称为“模型”。
例如本文重点讨论的回归模型,考虑到篇幅,重点讨论逻辑回归模型(Logistic Regression Model)。对于“回归”一词感到莫名的读者,欢迎搜索“高尔顿与回归分析的起源”,你会发现一个有趣的故事。回归模型的现代含义是:确定因变量与自变量间的关联性,即变量间相关关系的数学表达式(通常称为经验公式)。
![]()
为了让建模过程更具象,现在开始想象一下你要包装出一个偶像团体,这个团体实力超群,能够获得观众的喜爱。团体就是最终的模型,而团体中的成员就是自变量(Independent Variable,后面简称变量)。那么首先我们需要确定这个团体最终需要达到什么目的,也就是我们的因变量(Dependent Variable,后面简称预测值)。好,假设我们的团体目的是能否在未来3年内俘获14~18岁少女们的心(是或否)。针对逻辑回归而言,我们预测的因变量就是一个取值为0或1的变量。
接下来我们要做的是找寻足够的候选队员,候选的队员越多,我们可选择的余地也越大,很多时候变量池的大小已经决定了我们最后模型的效果。所以开始准备尽量多的变量,就像选秀节目初期那样,搜罗来自五湖四海选手。另外,我们的需求是在未来3年内俘获14~16岁少女的心,那么颜值高、能够善舞、演技精湛等都称为我们需要覆盖的能力。因此除了关注量的多少,我们同时需要关注候选变量尽可能覆盖更多的维度,如果你的候选队员们都只是会唱歌,那么谁来跳舞呢?
![]()
当变量们已经就位,我们可以拉开变量选秀的序幕了。
1、海选
第一步,海选。从众多的变量中先剔除那些五音不全、肢体不协调的。比如缺失率过高,数值中存在大量无效值的变量。海选中,总有些让你取舍两难的候选人,那么尝试一些方法来看看他们日后是否真的对团体有帮助:
1.信息缺失本身也意味着某种信息,把是否缺失该信息作为一个新的变量留下来;
2.字符型的变量不能用于回归模型,尝试把他们变成数值型变量,比如对于城市,把他转化成是否上海、是否北京、是否广州等数个变量;
3.时间型变量,把他们转化为距离某个时间点的月份数、年份数等等,具体如图:

2、精选
第二步,精选。精选过程和选秀节目一样,通过300进100,100进30等阶段的选择来一步步筛选变量。只是在这个筛选过程中,需要有一些客观衡量,如何区分候选成员是否能为最终的团体带来充分的价值,这时候就需要用一些指标来衡量。在变量选择中,我们可以采用单变量的IV值,KS值来区分一个变量是否能够有效地区分因变量(0/1)。在IV值的取舍上,一般我们会保留0.2以上的变量,而实际保留的阈值则取决于变量的多寡,如果你只有一堆IV值为0.1的变量,那么还是谨慎些保留更多的候选成员吧,或者你可以从变量准备开始从新做起,尝试搜罗一些更有用的候选成员。
3、群组PK
第三步,群组PK。这一过程有时候是和第二步交叉着进行,很难严格地界定他们的流程次序,在这里暂且放在第三步。经历了精选,你的候选成员开始锁定在较小的一个范围内,此时,你需要留心观察一下他们所覆盖的维度,或许有十几个同样擅长舞蹈的候选人,或许有十几个同样精通于吉他的候选人,又或许有十几个同样喜欢唱抒情歌曲的。你并不希望在一个团体里,某一个维度被太多人占据,它也许会导致你的团体在某一方面过分突出,而在综合能力上则不尽人意。于是你可以在单个维度下对候选变量做一些筛选,从中挑出相对出众的。这样的做法目的在于消除变量间的共线性问题,这对于模型最终的表现有着非常重要的意义。而对于分组的做法,你可以是根据业务理解的,也可以借助一些群组算法(Cluster)来将所有变量归入不同的维度组别。
4、联排
第四步,联排。之前的步骤中主要还在针对个别候选成员进行考察,接下来,我们要对最后形成的团体进行考察。当然在此过程中,你仍然可以对单个变量做进一步的筛选。此时也许颜值也会成为重要的考虑因素,我们用Bi-var(单个变量和预测值之间的关系)来评价一个变量的颜值。提问,下面两个变量哪个变量颜值更高:

A
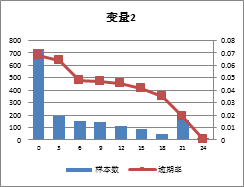
B
答案:【A】?
我很欣赏你的独特审美,但是很遗憾不符合一个数据分析师的审美,正确答案是【B】。
一个变量和它的预测值之间具有更强的单调线性关系才是我们追求的美。当然,更需要关注的是团队成员之间的配合,于是我们让变量们开始组合成模型,并对它们最终对因变量的预测能力做评价。首先哪些变量可以组成一个团体,我们通过假设检验来完成,所有能够通过假设检验的变量便被安排在一起成为一个模型。当你无法确定你的团体中最终有多少个人或者最终效果有多好时,你只能通过尽量多试来得到相对可靠的组合方式。
衡量模型效果的重要指标
在这个相对枯燥又繁琐的尝试不同的组合过程中,我们可以借助几个重要指标来帮助我们衡量最终模型的效果:
1. 进入模型中的变量个体的VIF值,这个值反映了变量之间存在多重共线性的程度有多严重,当过于严重时(例.VIF>1.5)时,你的团体中有几个人的角色过于雷同,尝试替换掉其中的某些团员;
2. 变量和变量间的共线性(collinearity,简称collin),除了关注整体共线性,你还需要关注变量和变量的两两相关性,这个指标在某种程度上也在帮助你筛选变量,降低VIF,例如在两个collin在0.4以上的变量中,你只需要选择其中一个更优的变量。两个擅长抒情歌的团员中,选那个唱的更撕心裂肺的;
3. C统计值,这个值衡量的是整个模型的效果,C值越高,则模型效果越好;
4. K-S值,K-S可以理解为模型对于好用户和坏用户(0和1)区分能力大小的判断指标,K-S值越高越好;
5. Top Capture Rate, 这个指标中,主要衡量的是在前10%或者前20%的人群中能够俘获的坏人的比例(1的比例)有多大,越大越好;
6. 排序(Ranking),在一个表现良好的模型中,按照单调排列的模型分组别中的坏人比例(1的比例)也应该是单调分布的,单调性越好则模型效果也越好。
最后还要提到一个衡量模型可靠性和稳定性的重要方面:不同人群的验证。
这也就是我们熟悉的训练样本、验证样本和已经Out-of-time样本。这3个样本可以这样理解,你所建立的团体需要有一些评委来投票确认,那些参与投票的评委就是你的训练样本,而当这个团体确立后你要找一些观众来测试他们真的如评委们想的那样受到认可,这些找来的观众就是你的验证样本。为了确保你的观众们不是只是受时下流行的趋势或者舆论的蛊惑,而表达出太离谱的喜好,你还想在半年后找一群差不多的人群再来复查一下你所组的团体是可以经得住时间考验的,这就是你的out-of-time样本。当这些都验证完毕,你终于有信心确定自己组了一个优质偶像实力团体,该把他们推向市场啦~~~祝贺你,你的模型完成了。但别高兴得太早,团体再红也有过气的那一天,模型再好也有失效的那一天。做好监控,当它表现不再良好时,你就该进行新一轮的选拔。
作者:Fenn;授权转自:众安数盟 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读:
原创系列文章:
1:从0开始搭建自己的数据运营指标体系(概括篇)
2 :从0开始搭建自己的数据运营指标体系(定位篇)
3 :从0开始搭建自己的数据运营体系(业务理解篇)
4 :数据指标的构建流程与逻辑
5 :系列 :从数据指标到数据运营指标体系
6: 实战 :为自己的公号搭建一个数据运营指标体系
7: 从0开始搭建自己的数据运营指标体系(运营活动分析)
数据运营 关联文章阅读:
运营入门,从0到1搭建数据分析知识体系
推荐 :数据分析师与运营协作的9个好习惯
干货 :手把手教你搭建数据化用户运营体系
推荐 :最用心的运营数据指标解读
干货 : 如何构建数据运营指标体系
从零开始,构建数据化运营体系
干货 :解读产品、运营和数据三个基友关系
干货 :从0到1搭建数据运营体系
数据分析、数据产品 关联文章阅读:
干货 :数据分析团队的搭建和思考
关于用户画像那些事,看这一文章就够了
数据分析师必需具备的10种分析思维。
如何构建大数据层级体系,看这一文章就够了
干货 : 聚焦于用户行为分析的数据产品
如何构建大数据层级体系,看这一文章就够了
80%的运营注定了打杂?因为你没有搭建出一套有效的用户运营体系
从底层到应用,那些数据人的必备技能
读懂用户运营体系:用户分层和分群
做运营必须掌握的数据分析思维,你还敢说不会做数据分析