- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- swagger访问路径
igotyback
swagger
Swagger2.x版本访问地址:http://{ip}:{port}/{context-path}/swagger-ui.html{ip}是你的服务器IP地址。{port}是你的应用服务端口,通常为8080。{context-path}是你的应用上下文路径,如果应用部署在根路径下,则为空。Swagger3.x版本对于Swagger3.x版本(也称为OpenAPI3)访问地址:http://{ip
- html 中如何使用 uniapp 的部分方法
某公司摸鱼前端
htmluni-app前端
示例代码:Documentconsole.log(window);效果展示:好了,现在就可以uni.使用相关的方法了
- 高级编程--XML+socket练习题
masa010
java开发语言
1.北京华北2114.8万人上海华东2,500万人广州华南1292.68万人成都华西1417万人(1)使用dom4j将信息存入xml中(2)读取信息,并打印控制台(3)添加一个city节点与子节点(4)使用socketTCP协议编写服务端与客户端,客户端输入城市ID,服务器响应相应城市信息(5)使用socketTCP协议编写服务端与客户端,客户端要求用户输入city对象,服务端接收并使用dom4j
- Python教程:一文了解使用Python处理XPath
旦莫
Python进阶python开发语言
目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业javascripthtmlcss旅游风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- 【目标检测数据集】卡车数据集1073张VOC+YOLO格式
熬夜写代码的平头哥∰
目标检测YOLO人工智能
数据集格式:PascalVOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1073标注数量(xml文件个数):1073标注数量(txt文件个数):1073标注类别数:1标注类别名称:["truck"]每个类别标注的框数:truck框数=1120总框数:1120使用标注工具:labelImg标注
- 钢筋长度超限检测检数据集VOC+YOLO格式215张1类别
futureflsl
数据集YOLO深度学习机器学习
数据集格式:PascalVOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):215标注数量(xml文件个数):215标注数量(txt文件个数):215标注类别数:1标注类别名称:["iron"]每个类别标注的框数:iron框数=215总框数:215使用标注工具:labelImg标注规则:对类别进
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- SpringBlade dict-biz/list 接口 SQL 注入漏洞
文章永久免费只为良心
oracle数据库
SpringBladedict-biz/list接口SQL注入漏洞POC:构造请求包查看返回包你的网址/api/blade-system/dict-biz/list?updatexml(1,concat(0x7e,md5(1),0x7e),1)=1漏洞概述在SpringBlade框架中,如果dict-biz/list接口的后台处理逻辑没有正确地对用户输入进行过滤或参数化查询(PreparedSta
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- BART&BERT
Ambition_LAO
深度学习
BART和BERT都是基于Transformer架构的预训练语言模型。模型架构:BERT(BidirectionalEncoderRepresentationsfromTransformers)主要是一个编码器(Encoder)模型,它使用了Transformer的编码器部分来处理输入的文本,并生成文本的表示。BERT特别擅长理解语言的上下文,因为它在预训练阶段使用了掩码语言模型(MLM)任务,即
- spring如何整合druid连接池?
惜.己
springspringjunit数据库javaidea后端xml
目录spring整合druid连接池1.新建maven项目2.新建mavenModule3.导入相关依赖4.配置log4j2.xml5.配置druid.xml1)xml中如何引入properties2)下面是配置文件6.准备jdbc.propertiesJDBC配置项解释7.配置druid8.测试spring整合druid连接池1.新建maven项目打开IDE(比如IntelliJIDEA,Ecl
- matlab mle 优化,MLE+: Matlab Toolbox for Integrated Modeling, Control and Optimization for Buildings...
Simon Zhong
matlabmle优化
摘要:FollowingunilateralopticnervesectioninadultPVGhoodedrat,theaxonguidancecueephrin-A2isup-regulatedincaudalbutnotrostralsuperiorcolliculus(SC)andtheEphA5receptorisdown-regulatedinaxotomisedretinalgan
- JavaScript 中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)
跳房子的前端
前端面试javascript开发语言ecmascript
在JavaScript中,深拷贝(DeepCopy)和浅拷贝(ShallowCopy)是用于复制对象或数组的两种不同方法。了解它们的区别和应用场景对于避免潜在的bugs和高效地处理数据非常重要。以下是对深拷贝和浅拷贝的详细解释,包括它们的概念、用途、优缺点以及实现方式。1.浅拷贝(ShallowCopy)概念定义:浅拷贝是指创建一个新的对象或数组,其中包含了原对象或数组的基本数据类型的值和对引用数
- 遥感影像的切片处理
sand&wich
计算机视觉python图像处理
在遥感影像分析中,经常需要将大尺寸的影像切分成小片段,以便于进行详细的分析和处理。这种方法特别适用于机器学习和图像处理任务,如对象检测、图像分类等。以下是如何使用Python和OpenCV库来实现这一过程,同时确保每个影像片段保留正确的地理信息。准备环境首先,确保安装了必要的Python库,包括numpy、opencv-python和xml.etree.ElementTree。这些库将用于图像处理
- 入门MySQL——查询语法练习
K_un
前言:前面几篇文章为大家介绍了DML以及DDL语句的使用方法,本篇文章将主要讲述常用的查询语法。其实MySQL官网给出了多个示例数据库供大家实用查询,下面我们以最常用的员工示例数据库为准,详细介绍各自常用的查询语法。1.员工示例数据库导入官方文档员工示例数据库介绍及下载链接:https://dev.mysql.com/doc/employee/en/employees-installation.h
- 00. 这里整理了最全的爬虫框架(Java + Python)
有一只柴犬
爬虫系列爬虫javapython
目录1、前言2、什么是网络爬虫3、常见的爬虫框架3.1、java框架3.1.1、WebMagic3.1.2、Jsoup3.1.3、HttpClient3.1.4、Crawler4j3.1.5、HtmlUnit3.1.6、Selenium3.2、Python框架3.2.1、Scrapy3.2.2、BeautifulSoup+Requests3.2.3、Selenium3.2.4、PyQuery3.2
- 详解:如何设计出健壮的秒杀系统?
夜空_2cd3
作者:Yrion博客园:cnblogs.com/wyq178/p/11261711.html前言:秒杀系统相信很多人见过,比如京东或者淘宝的秒杀,小米手机的秒杀。那么秒杀系统的后台是如何实现的呢?我们如何设计一个秒杀系统呢?对于秒杀系统应该考虑哪些问题?如何设计出健壮的秒杀系统?本期我们就来探讨一下这个问题:image目录一:****秒杀系统应该考虑的问题二:****秒杀系统的设计和技术方案三:*
- RabbitMQ生产者重复机制与确认机制
java炒饭小能手
java-rabbitmqrabbitmqjava
重复机制生产者发送消息时,出现了网络故障,导致与MQ的连接中断。为了解决这个问题,SpringAMQP提供的消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试。需要修该发送端模块的application.yaml文件,添加下面的内容:spring:rabbitmq:connection-timeout:1s#设置MQ的连接超时时间template:retry:ena
- yolov5>onnx>ncnn>apk
图像处理大大大大大牛啊
opencv实战代码讲解yoloonnxncnn安卓
一.yolov5pt模型转onnx条件:colabnotebookyolov51.安装环境!pipinstallonnx>=1.7.0#forONNXexport!pipinstallcoremltools==4.0#forCoreMLexport!pipinstallonnx-simplifier2.修改common.py在classFocus下面
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- 使用由 Python 编写的 lxml 实现高性能 XML 解析
hunyxv
python笔记pythonxml
转载自:文章lxml简介Python从来不出现XML库短缺的情况。从2.0版本开始,它就附带了xml.dom.minidom和相关的pulldom以及SimpleAPIforXML(SAX)模块。从2.4开始,它附带了流行的ElementTreeAPI。此外,很多第三方库可以提供更高级别的或更具有python风格的接口。尽管任何XML库都足够处理简单的DocumentObjectModel(DOM
- java工厂模式
3213213333332132
java抽象工厂
工厂模式有
1、工厂方法
2、抽象工厂方法。
下面我的实现是抽象工厂方法,
给所有具体的产品类定一个通用的接口。
package 工厂模式;
/**
* 航天飞行接口
*
* @Description
* @author FuJianyong
* 2015-7-14下午02:42:05
*/
public interface SpaceF
- nginx频率限制+python测试
ronin47
nginx 频率 python
部分内容参考:http://www.abc3210.com/2013/web_04/82.shtml
首先说一下遇到这个问题是因为网站被攻击,阿里云报警,想到要限制一下访问频率,而不是限制ip(限制ip的方案稍后给出)。nginx连接资源被吃空返回状态码是502,添加本方案限制后返回599,与正常状态码区别开。步骤如下:
- java线程和线程池的使用
dyy_gusi
ThreadPoolthreadRunnabletimer
java线程和线程池
一、创建多线程的方式
java多线程很常见,如何使用多线程,如何创建线程,java中有两种方式,第一种是让自己的类实现Runnable接口,第二种是让自己的类继承Thread类。其实Thread类自己也是实现了Runnable接口。具体使用实例如下:
1、通过实现Runnable接口方式 1 2
- Linux
171815164
linux
ubuntu kernel
http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.1.2-unstable/
安卓sdk代理
mirrors.neusoft.edu.cn 80
输入法和jdk
sudo apt-get install fcitx
su
- Tomcat JDBC Connection Pool
g21121
Connection
Tomcat7 抛弃了以往的DBCP 采用了新的Tomcat Jdbc Pool 作为数据库连接组件,事实上DBCP已经被Hibernate 所抛弃,因为他存在很多问题,诸如:更新缓慢,bug较多,编译问题,代码复杂等等。
Tomcat Jdbc P
- 敲代码的一点想法
永夜-极光
java随笔感想
入门学习java编程已经半年了,一路敲代码下来,现在也才1w+行代码量,也就菜鸟水准吧,但是在整个学习过程中,我一直在想,为什么很多培训老师,网上的文章都是要我们背一些代码?比如学习Arraylist的时候,教师就让我们先参考源代码写一遍,然
- jvm指令集
程序员是怎么炼成的
jvm 指令集
转自:http://blog.csdn.net/hudashi/article/details/7062675#comments
将值推送至栈顶时 const ldc push load指令
const系列
该系列命令主要负责把简单的数值类型送到栈顶。(从常量池或者局部变量push到栈顶时均使用)
0x02 &nbs
- Oracle字符集的查看查询和Oracle字符集的设置修改
aijuans
oracle
本文主要讨论以下几个部分:如何查看查询oracle字符集、 修改设置字符集以及常见的oracle utf8字符集和oracle exp 字符集问题。
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货
- png在Ie6下透明度处理方法
antonyup_2006
css浏览器FirebugIE
由于之前到深圳现场支撑上线,当时为了解决个控件下载,我机器上的IE8老报个错,不得以把ie8卸载掉,换个Ie6,问题解决了,今天出差回来,用ie6登入另一个正在开发的系统,遇到了Png图片的问题,当然升级到ie8(ie8自带的开发人员工具调试前端页面JS之类的还是比较方便的,和FireBug一样,呵呵),这个问题就解决了,但稍微做了下这个问题的处理。
我们知道PNG是图像文件存储格式,查询资
- 表查询常用命令高级查询方法(二)
百合不是茶
oracle分页查询分组查询联合查询
----------------------------------------------------分组查询 group by having --平均工资和最高工资 select avg(sal)平均工资,max(sal) from emp ; --每个部门的平均工资和最高工资
- uploadify3.1版本参数使用详解
bijian1013
JavaScriptuploadify3.1
使用:
绑定的界面元素<input id='gallery'type='file'/>$("#gallery").uploadify({设置参数,参数如下});
设置的属性:
id: jQuery(this).attr('id'),//绑定的input的ID
langFile: 'http://ww
- 精通Oracle10编程SQL(17)使用ORACLE系统包
bijian1013
oracle数据库plsql
/*
*使用ORACLE系统包
*/
--1.DBMS_OUTPUT
--ENABLE:用于激活过程PUT,PUT_LINE,NEW_LINE,GET_LINE和GET_LINES的调用
--语法:DBMS_OUTPUT.enable(buffer_size in integer default 20000);
--DISABLE:用于禁止对过程PUT,PUT_LINE,NEW
- 【JVM一】JVM垃圾回收日志
bit1129
垃圾回收
将JVM垃圾回收的日志记录下来,对于分析垃圾回收的运行状态,进而调整内存分配(年轻代,老年代,永久代的内存分配)等是很有意义的。JVM与垃圾回收日志相关的参数包括:
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc
-XX:+PrintGC
通
- Toast使用
白糖_
toast
Android中的Toast是一种简易的消息提示框,toast提示框不能被用户点击,toast会根据用户设置的显示时间后自动消失。
创建Toast
两个方法创建Toast
makeText(Context context, int resId, int duration)
参数:context是toast显示在
- angular.identity
boyitech
AngularJSAngularJS API
angular.identiy 描述: 返回它第一参数的函数. 此函数多用于函数是编程. 使用方法: angular.identity(value); 参数详解: Param Type Details value
*
to be returned. 返回值: 传入的value 实例代码:
<!DOCTYPE HTML>
- java-两整数相除,求循环节
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class CircleDigitsInDivision {
/**
* 题目:求循环节,若整除则返回NULL,否则返回char*指向循环节。先写思路。函数原型:char*get_circle_digits(unsigned k,unsigned j)
- Java 日期 周 年
Chen.H
javaC++cC#
/**
* java日期操作(月末、周末等的日期操作)
*
* @author
*
*/
public class DateUtil {
/** */
/**
* 取得某天相加(减)後的那一天
*
* @param date
* @param num
*
- [高考与专业]欢迎广大高中毕业生加入自动控制与计算机应用专业
comsci
计算机
不知道现在的高校还设置这个宽口径专业没有,自动控制与计算机应用专业,我就是这个专业毕业的,这个专业的课程非常多,既要学习自动控制方面的课程,也要学习计算机专业的课程,对数学也要求比较高.....如果有这个专业,欢迎大家报考...毕业出来之后,就业的途径非常广.....
以后
- 分层查询(Hierarchical Queries)
daizj
oracle递归查询层次查询
Hierarchical Queries
If a table contains hierarchical data, then you can select rows in a hierarchical order using the hierarchical query clause:
hierarchical_query_clause::=
start with condi
- 数据迁移
daysinsun
数据迁移
最近公司在重构一个医疗系统,原来的系统是两个.Net系统,现需要重构到java中。数据库分别为SQL Server和Mysql,现需要将数据库统一为Hana数据库,发现了几个问题,但最后通过努力都解决了。
1、原本通过Hana的数据迁移工具把数据是可以迁移过去的,在MySQl里面的字段为TEXT类型的到Hana里面就存储不了了,最后不得不更改为clob。
2、在数据插入的时候有些字段特别长
- C语言学习二进制的表示示例
dcj3sjt126com
cbasic
进制的表示示例
# include <stdio.h>
int main(void)
{
int i = 0x32C;
printf("i = %d\n", i);
/*
printf的用法
%d表示以十进制输出
%x或%X表示以十六进制的输出
%o表示以八进制输出
*/
return 0;
}
- NsTimer 和 UITableViewCell 之间的控制
dcj3sjt126com
ios
情况是这样的:
一个UITableView, 每个Cell的内容是我自定义的 viewA viewA上面有很多的动画, 我需要添加NSTimer来做动画, 由于TableView的复用机制, 我添加的动画会不断开启, 没有停止, 动画会执行越来越多.
解决办法:
在配置cell的时候开始动画, 然后在cell结束显示的时候停止动画
查找cell结束显示的代理
- MySql中case when then 的使用
fanxiaolong
casewhenthenend
select "主键", "项目编号", "项目名称","项目创建时间", "项目状态","部门名称","创建人"
union
(select
pp.id as "主键",
pp.project_number as &
- Ehcache(01)——简介、基本操作
234390216
cacheehcache简介CacheManagercrud
Ehcache简介
目录
1 CacheManager
1.1 构造方法构建
1.2 静态方法构建
2 Cache
2.1&
- 最容易懂的javascript闭包学习入门
jackyrong
JavaScript
http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
下面就是我的学习笔记,对于Javascript初学者应该是很有用的。
一、变量的作用域
要理解闭包,首先必须理解Javascript特殊
- 提升网站转化率的四步优化方案
php教程分享
数据结构PHP数据挖掘Google活动
网站开发完成后,我们在进行网站优化最关键的问题就是如何提高整体的转化率,这也是营销策略里最最重要的方面之一,并且也是网站综合运营实例的结果。文中分享了四大优化策略:调查、研究、优化、评估,这四大策略可以很好地帮助用户设计出高效的优化方案。
PHP开发的网站优化一个网站最关键和棘手的是,如何提高整体的转化率,这是任何营销策略里最重要的方面之一,而提升网站转化率是网站综合运营实力的结果。今天,我就分
- web开发里什么是HTML5的WebSocket?
naruto1990
Webhtml5浏览器socket
当前火起来的HTML5语言里面,很多学者们都还没有完全了解这语言的效果情况,我最喜欢的Web开发技术就是正迅速变得流行的 WebSocket API。WebSocket 提供了一个受欢迎的技术,以替代我们过去几年一直在用的Ajax技术。这个新的API提供了一个方法,从客户端使用简单的语法有效地推动消息到服务器。让我们看一看6个HTML5教程介绍里 的 WebSocket API:它可用于客户端、服
- Socket初步编程——简单实现群聊
Everyday都不同
socket网络编程初步认识
初次接触到socket网络编程,也参考了网络上众前辈的文章。尝试自己也写了一下,记录下过程吧:
服务端:(接收客户端消息并把它们打印出来)
public class SocketServer {
private List<Socket> socketList = new ArrayList<Socket>();
public s
- 面试:Hashtable与HashMap的区别(结合线程)
toknowme
昨天去了某钱公司面试,面试过程中被问道
Hashtable与HashMap的区别?当时就是回答了一点,Hashtable是线程安全的,HashMap是线程不安全的,说白了,就是Hashtable是的同步的,HashMap不是同步的,需要额外的处理一下。
今天就动手写了一个例子,直接看代码吧
package com.learn.lesson001;
import java
- MVC设计模式的总结
xp9802
设计模式mvc框架IOC
随着Web应用的商业逻辑包含逐渐复杂的公式分析计算、决策支持等,使客户机越
来越不堪重负,因此将系统的商业分离出来。单独形成一部分,这样三层结构产生了。
其中‘层’是逻辑上的划分。
三层体系结构是将整个系统划分为如图2.1所示的结构[3]
(1)表现层(Presentation layer):包含表示代码、用户交互GUI、数据验证。
该层用于向客户端用户提供GUI交互,它允许用户


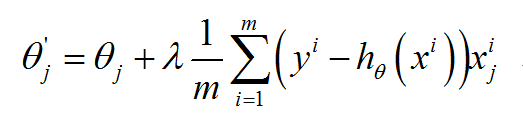 (1)
(1)