Java Stream特性与lambda表达式
古人学问无遗力,少壮工夫老始成
Stream 简介
Stream 流是jdk1.8版本引进的,那么Stream主要是对Java中的集合所提出的的集合流抽象工具(java.util.stream),主要用于集合内的元素的计算,准确的说是过滤和统计计算。
lambda简介
Java9 在语法上提供了Lambda表达式来传递方法体,简化了之前方法必须藏身在不必要的类中的繁琐。Lambda表达式体现了函数式编程的思想,即一个函数亦可以作为另一个函数参数和返回值,使用了函数作参数/返回值的函数被称为高阶函数。
lambda使用实例
以Runnable接口为例, 如果要执行一个接口,其实就是执行的是run()方法,但是还得需要先创建一个Runnable接口,实现类。
这时候使用lambda就不必了,可以直接执行run()方法。
new Thread(()->System.out.println("Hello world")).start();
Stream流的使用实例
1)对Stream的理解
Stream不是一种真实的数据源(不存在数据结构),所以我们没有办法直接来创建它,Stream只能依赖其他数据源来转换成我们的抽象操作。Stream本身是不存在,只是我们抽象出来的一个抽象操作,经过各种操作之后,Stream还需要转换成真实的数据源。
而且流是一次性数据,经过一次的中间操作选择后,就发生改变,如果想对一开始的流操作,需要重新创建一开始的流,因为现在的流已经改变。
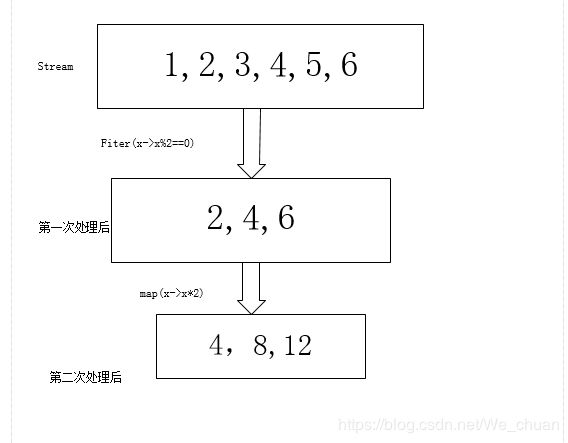
如上图所述,现在的流的内容为(4,8,12)
2)Stream的创建
三中stream的创建方法
//第一种 通过Stream接口的of静态方法创建一个流
Stream stream = Stream.of("hello", "world", "helloworld");
//第二种 通过Arrays类的stream方法,实际上第一种of方法底层也是调用的Arrays.stream(values);
String[] array = new String[]{"hello","world","helloworld"};
Stream stream3 = Arrays.stream(array);
//第三种 通过集合的stream方法,该方法是Collection接口的默认方法,所有集合都继承了该方法
Stream stream2 = Arrays.asList("hello","world","helloworld").stream();
接下来看一个简单的例子
现有 Arrays.asList(1, 2, 3, 4, 5, 6); 一个列表
需求 找出偶数并返回一个新的数组
传统做法
public class Test {
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4, 5, 6);
System.out.println(me(list));
}
public static Listme(List list){
ArrayList list2 = new ArrayList<>();
for (Integer integer : list) {
if (integer%2==0){
list2.add(integer);
}
}
return list2;
}
}
运用stream来做
public class Test1 {
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4, 5, 6);
list.stream().filter(x -> x % 2 == 0).forEach(s-> System.out.println(s));
}
}
用流仅仅一句话,就可以实现,摘出来分析一下。
list.stream() ###创建流对象
list.stream().filter() ##filter 中间操作,相当于过滤器,中间要写的就是判断条件
list.stream().filter(x->x%2==0) ##x->x lambda 表达式 x%2==0 判断条件。
其实,我们发现用stream 其实就是用一些中间操作,要注意这些中间操作,并不是一调用就会生效的,只用执行终端操作时,中间的操作才会生效。这就是Stream的延迟特性。
3)stream的中间及其终端操作操作

4)分组例子(groupingBy)
学生类中来自不同地方的学生,有男生也有女生。
需求
现在根据地方分成不同的小组
根据性别分组
用stream流来做
Student类
package com.westos.test;
public class Student {
private String name;
private String sex;
private String loc;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", loc='" + loc + '\'' +
'}';
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getSex() { return sex; }
public void setSex(String sex) { this.sex = sex; }
public String getLoc() { return loc; }
public void setLoc(String loc) { this.loc = loc; }
public Student(String name, String sex, String loc) {
this.name = name;
this.sex = sex;
this.loc = loc;
}}
实现方法按地区分组
package com.westos.test;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class TestStudent {
public static void main(String[] args) {
List students = Arrays.asList(
new Student("张", "男", "西安"),
new Student("李", "男", "西安"),
new Student("王", "女", "北京"),
new Student("赵", "女", "上海"),
new Student("周", "男", "北京"));
Map> collect = students.stream().collect(Collectors.groupingBy(Student -> Student.getLoc()));
System.out.println(collect);
}
}
运行结果
{上海=[Student{name=‘赵’, sex=‘女’, loc=‘上海’}],
西安=[Student{name=‘张’, sex=‘男’, loc=‘西安’}, Student{name=‘李’, sex=‘男’, loc=‘西安’}],
北京=[Student{name=‘王’, sex=‘女’, loc=‘北京’}, Student{name=‘周’, sex=‘男’, loc=‘北京’}]}
按照性别分组
package com.westos.test;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class TestStudent {
public static void main(String[] args) {
List students = Arrays.asList(
new Student("张", "男", "西安"),
new Student("李", "男", "西安"),
new Student("王", "女", "北京"),
new Student("赵", "女", "上海"),
new Student("周", "男", "北京"));
Map> collect = students.stream().collect(Collectors.groupingBy(Student -> Student.getSex()));
System.out.println(collect);
}
}
运行结果
{女=[Student{name=‘王’, sex=‘女’, loc=‘北京’},
Student{name=‘赵’, sex=‘女’, loc=‘上海’}],
男=[Student{name=‘张’, sex=‘男’, loc=‘西安’},
Student{name=‘李’, sex=‘男’, loc=‘西安’},
Student{name=‘周’, sex=‘男’, loc=‘北京’}]}
5)分区例子(partitioningBy)
再刚才的Student例子中再加入成绩属性。
那么我们要做的是将现有的学生类,按照成绩分成两类,这个时候可以用到分区
package com.westos.test;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class TestStudent {
public static void main(String[] args) {
List students = Arrays.asList(
new Student("张", "男", "西安",89),
new Student("李", "男", "西安",99),
new Student("王", "女", "北京",45),
new Student("赵", "女", "上海",25),
new Student("周", "男", "北京",66));
Map> collect = students.stream().collect(Collectors.partitioningBy(s -> s.getSco() >= 50));
List studentList = collect.get(false);//输出小于50分的
collect.get(true);//输出大于等于50分的
System.out.println(studentList);//输出小于50分的
}
}
结果
[Student{name=‘王’, sex=‘女’, loc=‘北京’, sco=45},
Student{name=‘赵’, sex=‘女’, loc=‘上海’, sco=25}]
总结:
其实分区会将我们的stream分成一个集合,集合中有两个列表,一个是false对应的,也就是低于50分的,另一个就是true对应的列表,也就是大于等于50分的。
那个我们可以将分区总结,它就经过条件,将stream分成两部分,一个是条件成立的,一个是筛选过后的。
6)总结
Stream每个操作都是依赖Lambda表达式或方法引用。
Stream操作是一种声明式的数据处理方式。
Stream操作提高了数据处理效率、开发效率