核心技术与算法学习笔记:中文分词技术
目录:
1.常用分词(包括规则分词 、 统计分词 以及混合分词等)的技术介绍
2.开源、中文分词工具一一Jieba 简介
难点:分词歧义、未登录词、分词粒度粗细等都是影响分词效果的重要因素
方法:规则分词、统计分词和混合分词(规则+统计)
1. 常用分词的技术介绍
1.1规则分词
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配找到则切分,否则不予切分。
按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法。
1.1.1 正向最大匹配(MM法)
其算法描述如下 :
1)从左向右取待切分汉语句的m个字符作为匹配字段,m为机器词典中 最长词条的字符数。
2)查找机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
实例
class MM(object):
def __init__(self):
self.window_size = 3
def cut(self,text):
result = []
index = 0
text_length = len(text)
dic = ['研究','研究生','生命','命','的','起源']
while text_length>index:
for size in range(self.window_size+index,index,-1):#3,0,1
piece = text[index:size]
if piece in dic:
index = size - 1
break #打破最小封闭的for或者while循环
index += 1
result.append(piece+'---')
print(result)
if __name__ == '__main__':
text = '研究生命的起源'
tokenizer = MM()
print(tokenizer.cut(text))
1.1.2 逆向最大匹配法(RMM法)
逆向最大匹配( Reverse Maximum Match Method , RMM 法)的基本原理与MM法相同,不同的是分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端i个字符(i 为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文挡。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
RMM法比MM法的误差要小。
实例:
class RMM(object):
def __init__(self):
self.window_size = 3
def cut(self,test):
result = []
index = len(test)
test_length = len(test)
dic = ['研究', '研究生', '生命', '命', '的', '起源']
while index > 0:
for size in range(index-self.window_size, index):
piece = text[size:index]
if piece in dic:
index = size+1
break # 打破最小封闭的for或者while循环
index -= 1
result.append(piece+'---')
result.reverse()
print(result)
if __name__ == '__main__':
text = '研究生命的起源'
tokenizer = RMM()
print(tokenizer.cut(text))
1.1.3 双向最大匹配法
双向最大匹配法(Bi-directction Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
实例:
if __name__ == '__main__':
text = '研究生命的起源'
tokenizer1 = MM()
tokenizer2 = RMM()
result_MM = tokenizer1.cut(text)
result_RMM = tokenizer2.cut(text)
len_MM = len(result_MM)
len_RMM = len(result_RMM)
if len_MM != len_RMM: # 正反向词数不同
if len_MM < len_RMM:
result = result_MM
else:
result = result_RMM
else: # 分词结果数相同
if operator.eq(result_MM, result_RMM): # 两个分词结果相同
result = result_MM # 返回任意一个
else: # 分词结果不同,返回单个字数较少的那个
min_MM = (x for x in result_MM if len(x) == 4) # 返回MM中的单个字
min_RMM = (x for x in result_RMM if len(x) == 4) # 返回RMM中的单个字
min_len_MM = len(list(min_MM))
min_len_RMM = len(list(min_RMM))
if min_len_MM > min_len_RMM:
result = result_RMM
else:
result = result_MM
print(result)
1.2 统计分词
主要思想如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能是一个词。因此可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
基于统计的分词,一般要做如下两步操作 :
1 )建立统计语言模型 。
2 )对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就用到了统计学习算法,如隐含马尔可夫 (HMM)、条件随机场 (CRF) 等。
1.2.1 语言模型
所谓 n 元模型就是在估算条件概率时,忽略距离大于等于 n 的上文词的影响,因此
![]()
n=1时(一元模型),此时整个句子的概率为P(w1,w2,…,wm)=P(w1)P(w2)…P(wm),即整个句子的概率等于各个词语概率的乘积。也就是各个词之间是相互独立的,完全损失句中的次序信息,效果不理想。

当n越大时,模型包含的词序信息越丰富,同时计算量随之增大。与此同时,长度越长的文本序列出现的次数也会减少。分母可能为0,因此,一般在n元模型中需要配合相应的平滑算法解决该问题,如拉普拉斯平滑算法等。
1.2.2 HMM模型
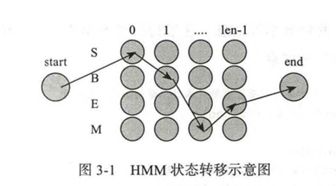
基本思路是 : 每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),现规定每个字最多只有四个构词位置 : 即 B (词首)、 M(词中)、 E (词尾)和 s (单独成词)。
在HMM中,求解maxP(λ|o)P(o) 的常用方法是 Veterbi 算法。它是一种动态规划方法,核心思想是 :如果最终的最优路径经过某个 o_i , 那么从初始节点到o_i-1点的路径必然也是一个最优路径,因为每一个节点o_i只会影响前后两个 P(o_i-1|o_i)和P(o_i|o_i+1)。
Viterbi 算法的效率是O(n•l),l是候选数目最多的节点o_i的候选数目,它正比于n,这是非常高效率的。
2. jieba
详情请看我的博客《NLP——jieba用法》
https://learningdayup.github.io/2019/08/27/NLP%E2%80%94%E2%80%94jieba%E7%94%A8%E6%B3%95/