基于Speex的声学回声消除
所谓声学回声消除,是为了解决VoIP(网络电话)中这样一个问题:即A与B进行通话,A端有麦克风和扬声器分别用来采集A的声音和播放B的声音,B端有麦克风和扬声器分别用来采集B的声音和播放A的声音,很明显,由于声音传播的特性,A端的麦克风在采集A的声音的同时,也采集到了A端扬声器播放的来自B的声音,也就是A端采集到的声音是一个混合的声音,这个声音通过网络发给B时,B就不仅能听到A的声音,也能听见B前几秒自己的声音,这就是在B端听到了B自己的回声,同理在A端也可以听到A自己的回声,这显然不是我们想要的。
声学回声消除一般可以通过硬件和软件分别实现,目前来说,硬件实现比较简单,软件实现较难,这里的难并不是说回声消除算法很难,而是在应用算法时的实时同步问题很难,目前软件实现较好的应该是微软,但似乎也对硬件配置和操作系统有要求。而Speex提供了声学回声消除算法库,本文就简单用Speex对一段录音进行回声消除,当然这不是实时处理的。
Speex中回声消除API封装在语音处理API中,在最新版本的Speex中将语音处理相关的API独立封装成libspeexdsp。
应用Speex回声消除API流程很简单:包含相关头文件——创建回声消除器状态——对每帧进行回声消除——销毁回声消除器状态。一般可以与Speex中的预处理器一起使用,已达到较好的声音效果,应用预处理器API的流程也很简单:包含相关头文件——创建预处理器状态——对每帧进行预处理——销毁预处理器状态。当然可以设置预处理器状态,在此我们使用默认设置。可以看到两者流程相同,因而写成一个CSpeexEC类,这是一个开源的回声消除器,对其中的两个函数调用做了稍微的修改。原文参见http://www.360doc.com/content/11/1008/18/11192_154383516.shtml,原文所用speex版本是1.1.9,我们用的是speex-1.2beta3-win32,执行预处理和回声消除的函数进行了更新。
1、speexEC.h
#ifndef SPEEX_EC_H
#define SPEEX_EC_H
#include
#include
/*在项目属性里设置VC++目录的包含目录和库目录分别为speex库中的include和lib,我用的是speex-1.2beta3-win32*/
#include
#include
class CSpeexEC
{
public:
CSpeexEC();
~CSpeexEC();
void Init(int frame_size=160, int filter_length=1280, int sampling_rate=8000);
void DoAEC(short *mic, short *ref, short *out);
protected:
void Reset();
private:
bool m_bHasInit;
SpeexEchoState* m_pState;
SpeexPreprocessState* m_pPreprocessorState;
int m_nFrameSize;
int m_nFilterLen;
int m_nSampleRate;
spx_int32_t* m_pfNoise;
};
#endif
2、speexEC.cpp
#include "stdafx.h"
#include "SpeexEC.h"
CSpeexEC::CSpeexEC()
{
m_bHasInit = false;
m_pState = NULL;
m_pPreprocessorState = NULL;
m_nFrameSize = 160;
m_nFilterLen = 160*8;
m_nSampleRate = 8000;
m_pfNoise = NULL;
}
CSpeexEC::~CSpeexEC()
{
Reset();
}
void CSpeexEC::Init(int frame_size, int filter_length, int sampling_rate)
{
Reset();
if (frame_size<=0 || filter_length<=0 || sampling_rate<=0)
{
m_nFrameSize =160;
m_nFilterLen = 160*8;
m_nSampleRate = 8000;
}
else
{
m_nFrameSize =frame_size;
m_nFilterLen = filter_length;
m_nSampleRate = sampling_rate;
}
m_pState = speex_echo_state_init(m_nFrameSize, m_nFilterLen);
m_pPreprocessorState = speex_preprocess_state_init(m_nFrameSize, m_nSampleRate);
m_pfNoise = new spx_int32_t[m_nFrameSize+1];
m_bHasInit = true;
}
void CSpeexEC::Reset()
{
if (m_pState != NULL)
{
speex_echo_state_destroy(m_pState);
m_pState = NULL;
}
if (m_pPreprocessorState != NULL)
{
speex_preprocess_state_destroy(m_pPreprocessorState);
m_pPreprocessorState = NULL;
}
if (m_pfNoise != NULL)
{
delete []m_pfNoise;
m_pfNoise = NULL;
}
m_bHasInit = false;
}
void CSpeexEC::DoAEC(short* mic, short* ref, short* out)
{
if (!m_bHasInit)
return;
/*1.1.9版本中所使用的函数*/
//speex_echo_cancel(m_pState, mic, ref, out, m_pfNoise);
//speex_preprocess(m_pPreprocessorState, (__int16 *)out, m_pfNoise);
/*1.2beta3-win32版本中使用的函数,从参数可以看出最新版本没有参数m_pfNoise,所以CSpeex中可以删除数据成员m_pfNoise*/
/*本文依然保留,是为了测试两个版本的差别,从结果来看,至少人耳似乎听不出有多大差别*/
speex_echo_cancellation(m_pState, mic, ref, out);
speex_preprocess_run(m_pPreprocessorState, (__int16 *)out);
}
3、测试驱动文件echocancel.cpp
#include "stdafx.h"
#include "speexEC.h"
#include
#include
#define NN 160
void main()
{
FILE *ref_fd;
FILE *mic_fd;
FILE *out_fd;
short ref[NN];
short mic[NN];
short out[NN];
ref_fd = fopen("FarEnd.pcm", "r+b");
mic_fd = fopen("NearEnd.pcm", "r+b");
out_fd = fopen("out.pcm", "w+b");
CSpeexEC ec;
ec.Init();
while (fread(mic, 1, NN*2, mic_fd))
{
fread(ref, 1, NN*2, ref_fd);
ec.DoAEC(mic, ref, out);
fwrite(out, 1, NN*2, out_fd);
}
fclose(ref_fd);
fclose(mic_fd);
fclose(out_fd);
}
程序需要两个FarEnd.pcm和NearEnd.pcm文件作为输入,输出out.pcm文件,其中FarEnd.pcm为远端回放音频,即待消除的回声参考文件,NearEnd.pcm是近端麦克风采集音频,是人的语音和回声的混合音频,out.pcm是对NearEnd.pcm进行回声消除后的文件。我们用matlab将纯净语音与FarEnd.pcm线性相加来产生NearEnd.pcm,其中采样率为8kHz,这样FarEnd与NearEnd是严格同步的,注意,是线性相加,而且可以将FarEnd乘以一个幅值再与纯净语音相加。从下图和听觉结果来看,完全同步时回声消除效果很好。
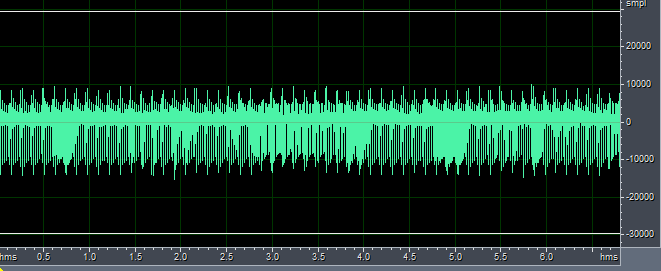
FarEnd-8kHz.pcm
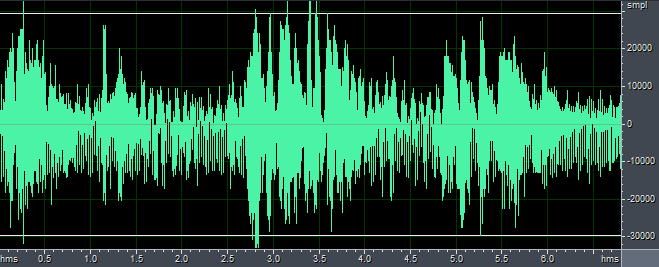
NearEnd-8kHz.pcm
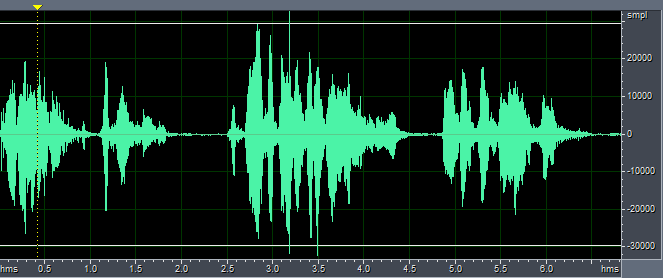
out-8kHz.pcm
但实际VoIP中麦克风采集到的人的语音和扬声器播放的声音并不是简单的线性混合,一方面是由于房间内的混响,它们更接近于卷积混合;更重要的是,麦克风采集到的回放和参考回放不是严格同步的,即FarEnd.pcm信号与NearEnd.pcm中的回放FarEnd信号不是同步的,一般会有几帧的延时,这是因为FarEnd.pcm是直接从声卡提取的,而NearEnd.pcm中的回放FarEnd信号是经过声卡经扬声器播放,再被麦克风采集的。
为此,我们选取一段歌曲作为FarEnd.pcm,在播放的FarEnd.pcm的同时开始录音,产生NearEnd.pcm。程序进行回声消除的结果如下:

FarEnd1-8kHz.pcm
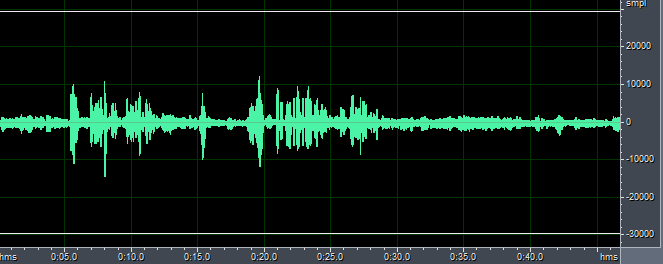
NearEnd1-8kHz.pcm
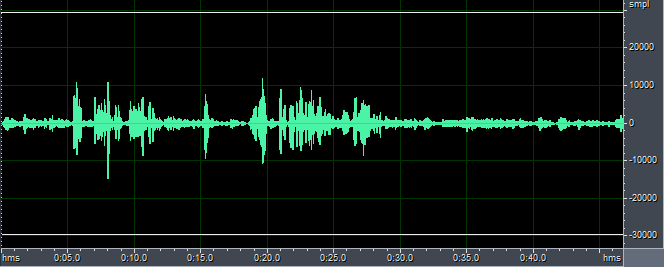
out1-8kHz.pcm
从上图及听力结果来看,在这样没同步的情况下,回声消除的效果并不理想。注意FarEnd.pcm参考回放的幅值比NearEnd.pcm录音到的回放幅值大,这是因为声音在传播过程中是会衰减的。
上图的结果是在采样率为8kHz下进行的,一个有趣的现象是,若提高采样率,效果似乎变好了。为此,我们将音频采样率转为44.1kHz并相应修改程序中的采样率,得到结果如下图所示:
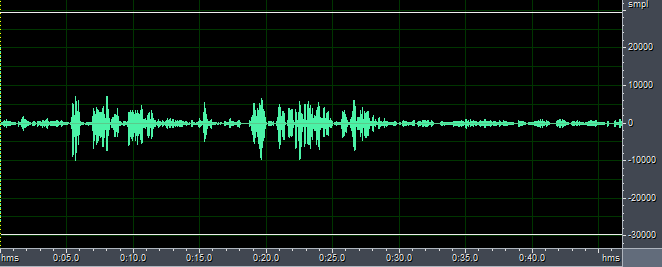
out2-44.1kHz.pcm
从上图来看似乎看不出效果变好,但是从听觉效果来看,回声的的确确是变小了。这应该跟回声消除算法的收敛有关,因为采样率变大,每秒的采样点多。采样率为8kHz,帧长160对应20ms;采样率为44.1kHz,帧长160对应约3.6ms,所以可能跟帧大小相关。具体什么原因,我还没想到一个很好的解释方法。
以上就是基于Speex的回声消除简单应用,在能保证同步的情况下效果不错,但不同步时效果变差,可以适当提高采样率(frame_size不变)以提高处理效果。