python爬虫:使用selenium + ChromeDriver爬取途家网
代码写的比较粗糙和不规范,请见谅。欢迎交流!
完整代码及说明,请参考 https://gitee.com/yeoman92/tujia_craw
说明
本站(途家网https://www.tujia.com)通过常规抓页面的方法不能获取数据,可以使用selenium + ChromeDriver来获取页面数据。
0 脚本执行顺序与说明
0.1 先执行craw_url.py,获得所有房子详情页的url
0.2 执行slice_url.py,把所有的url等份,便于后续作多线程爬取
0.3 执行craw.py,获取每个房子的具体数据
1 注意
1.1 本站的数据为动态加载,用到了selenium + ChromeDriver来获取页面数据
1.2 项目中附有chromedriver.exe,需要安装谷歌浏览器(如果运行不了,可能是浏览器和chromedriver.exe版本不对应,对应的浏览器版本为69)
1.3 注意driver模拟操作后,需要等待1-2s后才能获取到数据
1.4 本站有反爬,每一次页面操作设置睡眠6s即可
1.5 chrome_options.add_argument(“headless”) 设置为不打开浏览器界面
2 爬取内容
2.1 途家网https://www.tujia.com/unitlist?cityId=10
2.2 爬取字段及说明见截图
截图

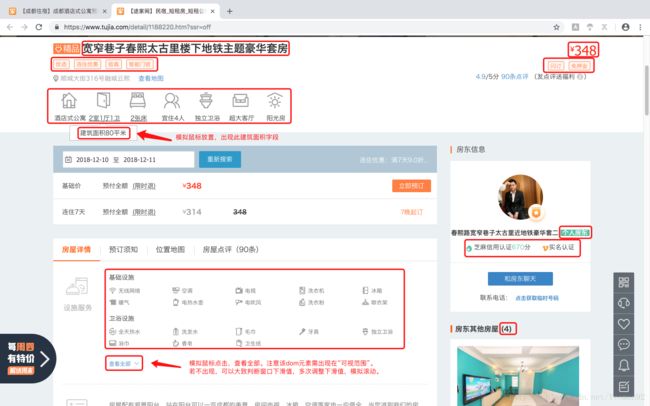

代码
1 craw_url.py (获得所有房子详情页的url)
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import time
import os
# 启动driver
def init_driver(url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("headless") # 不打开浏览器
driver_path = "./bin/chromedriver.exe"
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path=driver_path)
driver.get(url)
# html = driver.page_source
# print(html.encode("GBK",'ignore'))
# time.sleep(3)
return driver
# 如果文件存在,则删除
def del_file(file_path):
if os.path.exists(file_path):
os.remove(file_path)
# 获取页面url
def get_url(drive):
# 设置等待
wait = WebDriverWait(driver, 10)
# 关闭弹出的广告层
wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="j-tjdc-close"]'))).click()
# 获取总页数
total_str = driver.find_elements_by_class_name('pageItem')[-1].get_attribute('page-data')
total = int(total_str)
# 点击下一页
click_num = 0
while click_num < total:
driver.find_elements_by_class_name('pageItem')[-2].click()
click_num += 1
time.sleep(6)
# 每一页的项数
item = driver.find_elements_by_class_name('searchresult-cont')
item_num = len(item)
# 获取到该页面所有项的url
for i in range(item_num):
xpath = '//*[@id="unitList-container"]/div/div[' + str(i+1) + ']/div[2]/div[1]/h3/a'
url = driver.find_element_by_xpath(xpath).get_attribute('href')
print(str(i) + '\t' + url)
# 把url写到本地
with open('./data/url/url.txt', 'a', encoding='utf-8') as f:
f.write(url + '\n')
close_driver(driver)
def close_driver(driver):
driver.quit()
if __name__ == '__main__':
root_url = 'https://www.tujia.com/unitlist?startDate=2018-12-10&endDate=2018-12-11&cityId=10&ssr=off'
driver = init_driver(root_url)
del_file('./data/url/url.txt')
get_url(driver)
2 slice_url.py(把所有的url等份,便于后续作多线程爬取)
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import math
# url比较多,一次性爬取可能会出现问题,分多步爬取
def main(slice_num):
# 读取所有的url
with open('./data/url/url.txt', 'r') as f:
urls = f.readlines()
urls_num = len(urls)
step = math.ceil(urls_num / slice_num)
# 写url
for i in range(slice_num):
with open('./data/url/url_' + str(i+1) + '.txt', 'w', encoding='utf-8') as f:
for j in range(step*i, step*(i+1)):
try:
f.write(urls[j])
except:
break
if __name__ == '__main__':
# 分30等份
main(30)3 craw.py(获取每个房子的具体数据)
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import os
import time
import threading
# 启动driver
def init_driver(url, index):
global threads
threads['Thread_' + str(index)] += 1
print('Thread_' + str(index) + '\t' + str(threads['Thread_' + str(index)]))
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument("headless") # 不打开浏览器
driver_path = "./bin/chromedriver.exe"
driver = webdriver.Chrome(options=chrome_options, executable_path=driver_path)
try:
driver.get(url)
except:
pass
# html = driver.page_source
# print(html.encode("GBK",'ignore'))
# time.sleep(2)
return driver
def close_driver(driver):
driver.quit()
# 如果文件存在,则删除
def del_file(file_path):
if os.path.exists(file_path):
os.remove(file_path)
# 读取本地的url
def read_url(file_path):
with open(file_path, 'r') as f:
urls = f.readlines()
return urls
# 获取页面数据
def get_data(driver, file_path, index):
try:
# 店名,价格,房屋标签,支付标签,优势标签
name = driver.find_element_by_xpath('//div[@class="house-name"]').text
price = ''
try:
price = driver.find_element_by_xpath('//a[@class="present-price"]').text
except:
pass
# 房屋面积
area = ''
try:
house_type_element = driver.find_element_by_xpath('//*[@id="houseInfo"]/div/div/div[1]/div[3]/ul/li[2]')
ActionChains(driver).move_to_element(house_type_element).perform()
area = driver.find_element_by_xpath('//*[@id="houseInfo"]/div/div/div[1]/div[3]/ul/li[2]/div').text
except:
pass
room_tag = ''
try:
room_tag = driver.find_element_by_xpath('//ul[@class="room-tag"]').text.replace('\n', ' ')
except:
pass
pay_tag = ''
try:
pay_tag = driver.find_element_by_xpath('//ul[@class="pay-tag"]').text.replace('\n', ' ')
except:
pass
advan_tag = ''
try:
advan_tag = driver.find_element_by_xpath('//div[@class="hotel-advan-tag"]').text.replace('\n', ' ')
except:
pass
# 房屋守则
house_rules = ''
try:
house_rules_all = driver.find_elements_by_xpath('//*[@id="unitcheckinneedtoknow"]/div[2]/div[2]/div[5]/ol/li')
house_rules_dis = driver.find_elements_by_xpath('//*[@id="unitcheckinneedtoknow"]/div[2]/div[2]/div[5]/ol/li[@class="not"]')
house_rules = ''
for item in house_rules_all:
house_rules += item.text + ' '
for item in house_rules_dis:
if item.text:
house_rules = house_rules.replace(item.text + ' ', '')
# print(house_rules.encode('gbk', 'ignore').decode('gbk'))
except:
pass
# 设施服务
facility_service = ''
# try:
# 点击查看更多
scrollTop = 800
success = False
while not success:
try:
js = "var q=document.documentElement.scrollTop=800"
driver.execute_script(js)
driver.find_element_by_xpath('//*[@id="facilityshowmore"]/a').click()
success = True
except:
scrollTop += 100
time.sleep(1)
# 分类,内容
try:
category_item = driver.find_elements_by_xpath('//*[@id="listWrap"]/h5')
# print(category_item)
content_item = driver.find_elements_by_xpath('//*[@id="listWrap"]/ul')
# print(content_item)
for index, category_ in enumerate(category_item):
category = category_.text
content = content_item[index].text.replace('\n', ' ')
if category:
facility_service += category + '('
facility_service += content + ') '
except:
pass
try:
facility_dis = driver.find_elements_by_xpath('//*[@id="listWrap"]//li[@class="i-not"]')
for item in facility_dis:
# print(item)
if item.text:
facility_service = facility_service.replace(item.text + ' ', '')
# print(item.text.encode('gbk', 'ignore').decode('gbk'),end=' ')
# print(facility_service.encode('gbk', 'ignore').decode('gbk'))
except:
pass
# 房东信息
# 房东类型
landlord_type = ''
try:
landlord_type = driver.find_element_by_xpath('//*[@id="landlordInfo"]/div/div[2]/div/h2/span').text
except:
pass
# 房东认证
landlord_authentication = ''
try:
landlord_authentication = driver.find_element_by_xpath('//*[@id="landlordInfo"]/div/div[2]/div/div[2]').text
except:
pass
# 其他房屋数
landlord_other_house_num = ''
try:
landlord_other_house_num = driver.find_element_by_xpath('//div[@class="landlord-other-house"]/h2/span').text
except:
pass
# print(landlord_type)
# print(landlord_authentication)
# print(landlord_other_house_num)
# # 评价
# # 综合评分,单项评分,评论数,带照片评论数
overall_score = ''
single_score = ''
comment_sum = ''
comment_photo_sum = ''
try:
overall_score = driver.find_element_by_xpath('//*[@id="overallScore"]').text
single_score = driver.find_element_by_xpath('//*[@id="comment-summary"]/div[2]/div[1]/div[2]').text.replace('分', '')
comment_sum = driver.find_element_by_xpath('//*[@id="comment_filter"]/li[1]/span').text.replace('(', '').replace(')', '')
comment_photo_sum = driver.find_element_by_xpath('//*[@id="comment_filter"]/li[2]/span').text.replace('(', '').replace(')', '')
except:
pass
# print('Thread_' + str(index) + '\t' + str(threads['Thread_' + str(index)]), end='\t')
# print('\tThread_' + str(index))
# # 先用 GBK 编码,加个 ignore 丢弃错误的字符,然后再解码
print('\t----店名----\t' + name.encode('gbk', 'ignore').decode('gbk'))
# print('\t----价格----\t' + price.encode('gbk', 'ignore').decode('gbk'))
print('\t--建筑面积--\t' + area.encode('gbk', 'ignore').decode('gbk'))
# print('\t----房屋----\t' + room_tag.encode('gbk', 'ignore').decode('gbk'))
# print('\t----支付----\t' + pay_tag.encode('gbk', 'ignore').decode('gbk'))
# print('\t----优势----\t' + advan_tag.encode('gbk', 'ignore').decode('gbk'))
# print('\t--设施服务--\t' + facility_service.encode('gbk', 'ignore').decode('gbk'))
# print('\t--房屋守则--\t' + house_rules.encode('gbk', 'ignore').decode('gbk'))
# print('\t--房东类型--\t' + landlord_type.encode('gbk', 'ignore').decode('gbk'))
# print('\t--房东认证--\t' + landlord_authentication.encode('gbk', 'ignore').decode('gbk'))
# print('\t--其他房数--\t' + landlord_other_house_num.encode('gbk', 'ignore').decode('gbk'))
# print('\t--综合评分--\t' + overall_score.encode('gbk', 'ignore').decode('gbk'))
# print('\t--单项评分--\t' + single_score.encode('gbk', 'ignore').decode('gbk'))
# print('\t---评论数---\t' + comment_sum.encode('gbk', 'ignore').decode('gbk'))
# print('\t--照评论数--\t' + comment_photo_sum.encode('gbk', 'ignore').decode('gbk'))
# 写入数据到本地
with open(file_path, 'a', encoding='utf-8') as f:
f.write('--------------------------------------------------------------\n')
f.write('\t----店名----\t' + name.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t----价格----\t' + price.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--建筑面积--\t' + area.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t----房屋----\t' + room_tag.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t----支付----\t' + pay_tag.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t----优势----\t' + advan_tag.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--设施服务--\t' + facility_service.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--房屋守则--\t' + house_rules.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--房东类型--\t' + landlord_type.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--房东认证--\t' + landlord_authentication.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--其他房数--\t' + landlord_other_house_num.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--综合评分--\t' + overall_score.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--单项评分--\t' + single_score.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t---评论数---\t' + comment_sum.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t--照评论数--\t' + comment_photo_sum.encode('gbk', 'ignore').decode('gbk') + '\n')
# 获取当前页评论
get_data_comment(driver, file_path)
# 评论内容
# 评论总页数
comment_page_num = 1
try:
comment_page_num_str = driver.find_elements_by_xpath('//*[@id="comment_list"]/li[1]/div[2]/ul/li')[-1].get_attribute('page-data')
comment_page_num = int(comment_page_num_str)
except:
pass
# 点击下一页
if comment_page_num > 1:
click_num = 0
while click_num < comment_page_num:
# 当前页最后一项评论的时间
try:
last_item = driver.find_element_by_xpath('//*[@id="comment_list"]/li[1]/div[1]/ul/li[last()]/div[2]/div[1]/div/span[2]').text
date = last_item.replace('-', '')[:6]
# 日期大于2017年9月的
if int(date) < 201709:
break
except:
pass
# print(date.encode('gbk', 'ignore').decode('gbk'))
# 滑动到底部
js = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
time.sleep(2)
try:
driver.find_elements_by_xpath('//*[@id="comment_list"]/li[1]/div[2]/ul/li')[-2].click()
except:
break
'//*[@id="comment_list"]/li[1]/div[2]/ul/li[7]'
click_num += 1
time.sleep(4)
# 获取当前页评论
get_data_comment(driver, file_path)
close_driver(driver)
except:
print('error')
close_driver(driver)
# 获取评论模块数据
def get_data_comment(driver, file_path):
try:
# 当前页评论数
comment_curr_page = driver.find_elements_by_xpath('//*[@id="comment_list"]/li[1]/div[1]/ul/li')
comment_curr_page_num = len(comment_curr_page)
for index in range(comment_curr_page_num):
xpath_head = '//*[@id="comment_list"]/li[1]/div[1]/ul/li[' + str(index + 1) + ']'
# 评论人
comment_person = driver.find_element_by_xpath(xpath_head + '/div[2]/div[1]/div/span[1]').text
# 评论时间
comment_time = driver.find_element_by_xpath(xpath_head + '/div[2]/div[1]/div/span[2]').text.replace('点评', '')
# 评论内容
comment_content = driver.find_element_by_xpath(xpath_head + '/div[2]/div[2]').text
# 是否回复
comment_replay = ''
try:
comment_replay = driver.find_element_by_xpath(xpath_head + '/div[2]/div[4]/div[1]/div[2]/p').text.replace(
':', '')
except:
pass
# print('\t---------------------评论---------------------')
# print('\t\t---评论人---\t' + comment_person.encode('gbk', 'ignore').decode('gbk'))
# print('\t\t---评论时间---\t' + comment_time.encode('gbk', 'ignore').decode('gbk'))
# print('\t\t---评论内容---\t' + comment_content.encode('gbk', 'ignore').decode('gbk'))
# print('\t\t---是否回复---\t' + comment_replay.encode('gbk', 'ignore').decode('gbk'))
# 写入评论数据到本地
with open(file_path, 'a', encoding='utf-8') as f:
f.write('\t---------------------评论---------------------\n')
f.write('\t\t---评论人---\t' + comment_person.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t\t--评论时间--\t' + comment_time.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t\t--评论内容--\t' + comment_content.encode('gbk', 'ignore').decode('gbk') + '\n')
f.write('\t\t--是否回复--\t' + comment_replay.encode('gbk', 'ignore').decode('gbk') + '\n')
except:
pass
def main(index):
urls = read_url('./data/url/url_' + str(index) + '.txt')
del_file('./data/house/data_' + str(index) + '.txt')
for url in urls:
driver = init_driver(url, index)
get_data(driver, './data/house/data_' + str(index) + '.txt', index)
if __name__ == '__main__':
# 每次运行使用10个线程来爬取
global threads
threads = {}
# 上文craw_url中共切分成30份,这里我份三次运行,我的电脑只能开10个线程。(1-11,11-21,21-31)
for index in range(1, 11):
threads['Thread_' + str(index)] = 0
thread = threading.Thread(target=main, args=(index,))
thread.start()