C/C++ 之 C发展史及 各标准特性说明
Tips:
1. 本人当初学习C/C++的记录。
2. 资源很多都是来自网上的,如有版权请及时告知!
3. 可能会有些错误。如果看到,希望能指出,以此共勉!
C 发展史
1951年,IBM的Jhon Backus(Fortran开发小组组长)基于汇编语言着手研发Fortran语言。
1960年,图灵奖获得者Alan J.Perlis在巴黎举行的有全世界一流软件专家参加的讨论会上,发表了"算法语言Algol 60报告",确定了程序设计语言Algol 60。Algol60语言的第一个编译器由Edsger W. Dijkstra来实现。1962年,Alan J.Perlis又对Algol 60进行了修正。Algo60语言,是从Fortran演化的一个标准,目的是标准化一种数值计算语言。
1963年,剑桥大学将ALGOL 60语言发展成为CPL语言(Combined Programming Language)。
1967年,剑桥大学的Matin Richards对CPL语言进行了简化,于是产生了BCPL语言。
1970年,美国贝尔实验室的Ken Thompson将BCPL进行了修改,并为它起了一个有趣的名字“B语言”(最初是为Unix设计的)。并且他用B语言写了第一个UNIX操作系统(第二版)。
1973年,美国贝尔实验室的D.M. Ritchie在B语言的基础上最终设计出了一种新的语言,他取了BCPL的第二个字母作为这种语言的名字,这就是C语言。此后,其用C语言对Unix进行了重写(第三版)。
C 标准发展
最初,C语言没有官方标准。1978年Brian W.Kernighian和Dennis M.Ritchie出版了名著《The C Programming Language》,从而使C语言成为目前世界上流行最广泛的高级程序设计语言。而这本书附录中的C Referrence Manual成为了事实上的C语言标准,被人们称为K&R C或者Classic C。但是,该附录中只定义了C语言,却没有定义C库。由于C的出现离不开Unix,因此,Unix上实现的库成为了一个C语言事实上的标准库。
随着C语言的日益流行,美国国家标准化组织(ANSI)在1983年成立了一个委员会(X3J11),以制定C语言标准。该标准于1989年正式被批准采用。它就是ANSI C标准。该标准定义了C语言标准和C的标准库。1990年,国际标准化组织(ISO)也要制定了一个C标准,以使C语言在国际上统一标准,方便使用,他们直接采用了ANSI C标准,发布了标准文件:ISO/IEC 9899-1990 Programming languages – C。最终第一版的C标准被称为C98或C90。算是C语言的第一个官方标准。由于ANSI C出现较早,该标准也称为 ANSI C。
1994年,ISO 对C语言标准的修订工作正式开始。1999年12月1日,国际标准化组织(ISO)和国际电工委员会(IEC)旗下的C语言标准委员会(ISO/IEC JTC1/SC22/WG14)正式发布了标准文件: ISO/IEC 9899:1999 - Programming languages – C。这就是大家熟知的C99标准。这成为了C语言的第二个官方标准。
C99的修订为C语言引入了大量新的特性,其借鉴了C++98标准一些特性。然而,如今不是所有C的编译器都支持C99标准,而完全或几乎完全支持C99标准的主流编译器有:GCC、Clang、Intel C++ Compiler等。另外,Visual Studio2013也部分支持了C99语法特征。
C99标准之后,新的C语言标准是国际标准化组织(ISO)和国际电工委员会(IEC)在2011年12月8日正式发布的C11标准,官方正式名为ISO/IEC 9899:2011。
C标准由ISO和IEC旗下的C语言标准委员会(ISO/IEC JTC1/SC22/WG14)编写,在其官方网站(http://www.open-std.org/)上可以找到标准的草稿,草稿是免费的!
C99 新特性
- 对编译器限制增加了,比如源程序每行要求至少支持到4095字节,变量名函数名的要求支持到63字节 (extern要求支持到31)
- 预处理增强了。例如:
- 宏支持取参数 #define Macro(…) __VA_ARGS__
- 使用宏的时候,参数如果不写,宏里用#,## 这样的东西会扩展成空串。(以前会出错的)
- 支持 // 行注释(这个特性实际上在C89的很多编译器上已经被支持了)
- 增加了新关键字restrict(C++目前并未引入), inline, _Complex, _Imaginary, _Bool
- 支持 long long, long double _Complex, float _Complex 这样的类型
- 支持 <: :> <% %> %: %:%: ,等等奇怪的符号替代,D&E 里提过这个
- 支持了不定长的数组。数组的长度就可以用变量了。声明类型的时候呢,就用 int a[*] 这样的写法。不过考虑到效率和实现,这玩意并不是一个新类型。所以就不能用在全局里,或者 struct union 里面,如果你用了这样的东西,goto 语句就受限制了。
- 变量声明不必放在语句块的开头,for 语句提倡这么写 for(int i=0;i<100;++i) 就是说,int i 的声明放在里面,i 只在 for 里面有效。
- 当一个类似结构的东西需要临时构造的时候,可以用 (type_name){.numberN=valueN, .numberK=valueK,…} 这有点像 C++ 的构造函数
- 初始化结构的时候现在可以这样写:
struct {int a[3], b;} hehe[] = { [0].a = {1}, [1].a = 2 };
struct {int a, b, c, d;} hehe = { .a = 1, .c = 3, 4, .b = 5} // 3,4 是对 .c,.d 赋值的 - 字符串里面,\u 支持 unicode 的字符
- 支持 16 进制的浮点数的描述
- 所以 printf scanf 的格式化串多支持了 ll / LL对应新的 long long 类型。
- 浮点数的内部数据描述支持了新标准,这个可以用 #pragma 编译器指定
- 除了已经有的 line file 以外,又支持了一个 func 可以得到当前的函数名
- 对于非常数的表达式,也允许编译器做化简
- 修改了对于 / % 处理负数上的定义,比如老的标准里 -22 / 7 = -3, -22 % 7 = -1 而现在 -22 / 7 = -4, -22 % 7 = 6
- 取消了不写函数返回类型默认就是 int 的规定
- 允许 struct 定义的最后一个数组写做 [] 不指定其长度描述
- const const int i; 将被当作 const int i; 处理
- 增加和修改了一些标准头文件。
- 输入输出对宽字符还有长整数等做了相应的支持
增加restrict指针
关键字restrict只用于限定指针;该关键字用于告知编译器,所有修改该指针所指向内容的操作全部都是基于(base on)该指针的,即不存在其它进行修改操作的途径;这样的后果是帮助编译器进行更好的代码优化,生成更有效率的汇编代码。restrict指针指针主要用做函数变元,或者指向由malloc()函数所分配的内存变量。restrict数据类型不改变程序的语义。
如果某个函数定义了两个restrict指针变元,编译程序就假定它们指向两个不同的对象,memcpy()函数就是restrict指针的一个典型应用示例。
C89中memcpy()函数原型如下:
void *memcpy (void *s1, const void *s2, size_t size);
如果s1和s2所指向的对象重叠,其操作就是未定义的。memcpy()函数只能用于不重叠的对象。
C99中memcpy()函数原型如下:
void *memcpy(void *restrict s1, const void *restrict s2,size_t size);
通过使用restrict修饰s1和s2 变元,可确保它们在该原型中指向不同的对象。
但要注意:restrict是C99中新增的关键字,在C89和C++中都不支持,在gcc中可以通过-std=c99来得到对它的支持。
inline(内联)关键字
内联函数除了保持结构化和函数式的定义方式外,还能使程序员写出高效率的代码。函数的每次调用与返回都会消耗相当大的系统资源,尤其是当函数调用发生在重复次数很多的循环语句中时。一般情况下,当发生一次函数调用时,变元需要进栈,各种寄存器内存需要保存。当函数返回时,寄存器的内容需要恢复。如果该函数在代码内进行联机扩展,当代码执行时,这些保存和恢复操作旅游活动会再发生,而且函数调用的执行速度也会大大加快。函数的联机扩展会产生较长的代码,所以只应该内联对应用程序性能有显著影响的函数以及长度较短的函数
新增数据类型
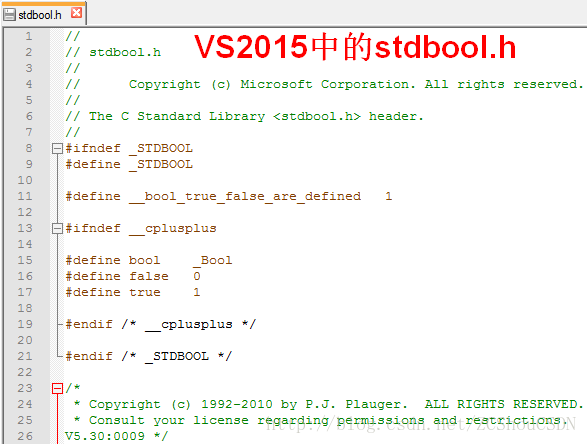
_Bool
值是0或1。C99中增加了用来定义bool、true以及false宏的头文件

_Complex and _Imaginary(复数和虚数)
C99标准中定义的复数类型如下:
float_Complex;
float_Imaginary;
double_Complex;
double_Imaginary;
long double_Complex;
long double_Imaginary;
long long int
C99标准中引进了long long int(-(2e63 - 1)至2e63 - 1)和unsigned long long int(0 - 2e64 - 1)。long long int能够支持的整数长度为64位。对应的常量后缀是ll/ull/LL/ULL;格式化输入输出为%lld,%llu,%llx……
对数组的增强
可变长数组
C99中,程序员声明数组时,数组的维数可以由任一有效的整型表达式确定,包括只在运行时才能确定其值的表达式,这类数组就叫做可变长数组,但是只有局部数组才可以是变长的。
可变长数组的维数在数组生存期内是不变的,也就是说,可变长数组不是动态的。可以变化的只是数组的大小。
void func(int n)
{
int vla[n];
printf("int vla[n] = %d\n", sizeof(vla));
}
- 变长数组有一些限制:变长数组必须是自动存储类的,意味着它们必须在函数内部或作为函数参数声明,而且声明时不可以进行初始化。
- C99标准规定,可以省略函数原型中的名称,但是如果省略名称,则需要用星号来代替省略的维数:
int sum2d(int , int, int ar[*][*]);// 只能用在函数声明中
数组声明中的类型修饰符
在C99中,如果需要使用数组作为函数变元,可以在数组声明的方括号内使用static关键字,这相当于告诉编译程序,变元所指向的数组将至少包含指定的元素个数。也可以在数组声明的方括号内使用restrict,volatile,const关键字,但只用于函数变元。如果使用restrict,指针是初始访问该对象的惟一途径。如果使用const,指针始终指向同一个数组。使用volatile没有任何意义。(类型限定词和static关键字只能用于具有数组类型的函数形参的第一维中)。由于形参中的VLA被自动调整为等效的指针,因此这些类型限定词实际上限定的是一个指针,例如:
void func3( int, int, int a[const][*] ); // 等价于void func( int, int, int ( *const a )[*] );
void func4( int, int, int a[const static 20][*] ); //static表示传入的实参的值至少要跟其所修饰的长度表达式的值一样大。
单行注释
// 行注释也是从C++过来的东西。引入了单行注释标记 “//” , 可以象C++一样使用这种注释了。//注释另外一个最大的好处还是在于排版方便。
/* / 注释是不支持嵌套的,所以只要里头出现一个/就会导致注释结束。不过这样也带来了一个有点可怕的陷阱,比如原来用/* */注释的宏:
#define macro(arg1, arg2) \
func(arg1, /* xxxxxxx */ \
arg2 /* xxxxxxx */ \
)
你要是改成这样:
#define macro(arg1, arg2) \
func(arg1, // xxxxxxx \
arg2 // xxxxxxx \
)
这就杯具了~~因为这样等价于:
#define macro(arg1, arg2) func(arg1, // xxxxxxx arg2 // xxxxxxx )
arg2就落入第一个//的魔掌,变成注释了~~
总得来说,用//写注释肯定是比较方便的。只要能保证别在一个文件里面一会儿用/* */做行注释,一会儿用//做行注释就行了。
建议所有的单行注释都可以用//搞。而文档化注释(函数头部、文件头部或者重要数据结构头部的那些注释),还是建议用正统的格式来写:
/**
* xxxxxxx
* xxxxxxx
*/
另外最好别用//来垒多行注释。
分散代码与声明
解除了原先必须在block的第一条语句之前声明变量的限制:现在C99也和C++一样,可以在代码中随时声明变量了。
#include 其实混合声明对于编码的重要意义在于它对提高代码的可读性方面帮助很大。在C89里面,稍微复杂一点的函数中通常会看到这样的壮观景象:
int load_elf_file(const char *filename, int argc, int argv, int *retcode)
{
int elf_exec_fileno;
int i, retval;
uint k, elf_bss, elf_brk, elf_entry;
uint start_code, end_code, end_data;
struct elf_phdr *elf_ppnt, *elf_phdata;
struct elfhdr elf_ex;
struct file *file;
...;
}
这个就是C89必须在Block第一条语句之前声明变量带来的后果,不管一个变量是否一直到Block的最后一行才被用到,你也不得不在一开始就声明它。
预处理程序的修改
变参宏(Variadic Macros)
宏可以带变元,在宏定义中用省略号(…)表示。内部预处理标识符__VA_ARGS__决定变元将在何处得到替换。变参宏的最大好处是可以让你很容易地用宏来封装一些带变参的函数(主要是打印函数)
如可以这样写一个输出到stderr的宏:
#define print_err(...) fprintf(stderr, __VA_ARGS__) // 宏参数里面“...”的部份会展开到__VA_ARGS__处。
如果在__VA_ARGS__前面加上##,就可以写出允许变参部份为空的变参宏。比如我自己常用的调试信息打印宏:
#define debug(fmt, ...) \
printf("[DEBUG] %s:%d <%s>: " fmt, \
__FILE__, __LINE__, __func__, ##__VA_ARGS__)
##__VA_ARGS__表示变参“…”部份允许为空。当变参部份为空时__VA_ARGS__会展开成空字符串,并且##前面那个逗号也会在展开时去掉。于是你可以这样调用这个宏:debug(“Hello”);

_Pragma运算符
C99引入了在程序中定义编译指令的另外一种方法:_Pragma运算符。格式如下:
_Pragma("directive")
其中directive是要满打满算的编译指令。_Pragma运算符允许编译指令参与宏替换。
如果字符串文字具有L前缀,则删除该前缀。
删除前导和结尾双引号。
用双引号替换每个换码序列’。
用单个反斜杠替换每个换码序列\
内部编译指令
STDC FP_CONTRACT ON/OFF/DEFAULT 若为ON,浮点表达式被当做基于硬件方式处理的独立单元。默认值是定义的工具。
STDC FEVN_ACCESS ON/OFF/DEFAULT 告诉编译程序可以访问浮点环境。默认值是定义的工具。
STDC CX_LIMITED_RANGE ON/OFF/DEFAULT 若值为ON,相当于告诉编译程序某程序某些含有复数的公式是可靠的。默认是OFF。
新增的内部宏
STDC_HOSTED 若操作系统存在,则为1
STDC_VERSION 199991L或更高。代表C的版本
STDC_IEC_599 若支持IEC 60559浮点运算,则为1
STDC_IEC_599_COMPLEX 若支持IEC 60599复数运算,则为1
STDC_ISO_10646 由编译程序支持,用于说明ISO/IEC 10646标准的年和月格式:yyymmmL
for语句内的变量声明
C99中,程序员可以在for语句的初始化部分定义一个或多个变量,这些变量的作用域仅于本for语句所控制的循环体内。在C89中,这样是不可以的,具体可以在VC6中验证(VC6支持到C89)。for循环的初始化语句中声明的任何变量的作用域是整个循环(包括控制和迭代表达式)。
如下:
for (int i=0; i<10; i++){
//loop body
};
复合赋值
C99复合赋值中,可以指定对象类型的数组、结构或联合表达式。当使用复合赋值时,应在括弧内指定类型,后跟由花括号围起来的初始化列表;若类型为数组,则不能指定数组的大小。建成的对象是未命名的。
例: double *fp = (double[]) {1.1, 2.2, 3.3};
该语句用于建立一个指向double的指针fp,且该指针指向这个3元素数组的第一个元素。 在文件域内建立的复合赋值只在程序的整个生存期内有效。在模块内建立的复合赋值是局部对象,在退出模块后不再存在。
伸缩型数组成员
C99具有一个称为伸缩型数组成员(flexible array member)的新特性。结构中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员。利用这一新特性可以声明最后一个成员是一个具有特殊属性的数组的结构体。该数组成员的特殊属性之一是它不立即存在。第二个特殊属性是您可以编写适当的代码使用这个伸缩型数组成员,就像它确实存在并且拥有您需要的任何数目的元素一样。柔性数组成员在做变长的报文或字符串处理时极为好用,也是一个几乎所有的C码农都应该掌握的技巧。
声明一个伸缩型数组成员的规则:
- 伸缩型数组成员必须是最后一个数组成员。
- 结构中必须至少有一个其他成员。
- 伸缩型数组就像普通数组一样被声明,但是它的方括号是空的。
比如:
typedef struct {
int count;
char word[]; // 只能放在末尾,等价于gcc的char word[0]
} word_counter_t;
注意:
- sizeof返回的这种结构大小不包括柔性数组的内存
- 直接声明带有伸缩数组成员结构体的变量没有任何意义,因为伸缩数组没有内存,例如:word_counter_t wd; // 这里变量wd中没有word
- 包含柔性数组成员的结构用malloc()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。当给其指针动态分配内存空间时,多余的空间会分配给scores数组
指定的初始化符
C99中,该特性对经常使用稀疏数组的程序员十分有用。简单来说,就是在初始化结构体和数组时,可以通过指定具体成员名或数组下标来赋初值。
用于数组的格式:
[index] = vol; // 其中,index表示数组的下标,vol表示本数组元素的初始化值。
例如:
int x[10] = {[0] = 10, [5] = 30}; 其中只有x[0]和x[5]得到了初始化
用于结构或联合的格式如下:
.成员名 = vol; // 其中, vol表示本数组元素的初始化值。
例如:
struct example{ int k, m, n; } object = {.m = 10, .n = 200};
注意:该方法只能用在定义时初始化,不能再后续使用

printf()和scanf()函数系列的增强
C99中printf()和scanf()函数系列引进了处理long long int和unsigned long long int数据类型的特性。long long int 类型的格式修饰符是ll。在printf()和scanf()函数中,ll适用于d, i, o, u 和x格式说明符。另外,C99还引进了hh修饰符。当使用d, i, o, u和x格式说明符时,hh用于指定char型变元。ll和hh修饰符均可以用于n说明符。
格式修饰符a和A用在printf()函数中时,结果将会输出十六进制的浮点数。格式如下:[-]0xh, hhhhp + d 使用A格式修饰符时,x和p必须是大写。A和a格式修饰符也可以用在scanf()函数中,用于读取浮点数。调用printf()函数时,允许在%f说明符前加上l修饰符,即%lf,但不起作用。
C99新增的库
C89中标准的头文件
定义宏assert()
字符处理
错误报告
定义与实现相关的浮点值
定义与实现相关的各种极限值
支持函数setlocale()
数学函数库使用的各种定义
支持非局部跳转
定义信号值
支持可变长度的变元列表
定义常用常数
支持文件输入和输出
其他各种声明
支持串函数
支持系统时间函数
C99新增的头文件和库
支持复数算法
给出对浮点状态标记和浮点环境的其他方面的访问
定义标准的、可移植的整型类型集合。也支持处理最大宽度整数的函数
在1995年第一次修订时首次引进,用于定义对应各种运算符的宏
支持布尔数据类型类型。定义宏bool,以便兼容于C++
定义标准的、可移植的整型类型集合。该文件包含在中
定义一般类型的浮点宏
在1995年第一次修订时首次引进,用于支持多字节和宽字节函数
在1995年第一次修订时首次引进,用于支持多字节和宽字节分类函数
__func__预定义标识符
用于指出__func__所存放的函数名,类似于字符串赋值。
幂等限定符
C99中,如果同一类型限定符在同一说明符限定符列表中出现多次(无论直接出现还是通过一个或多个typedef),行为与该类型限定符仅出现一次时相同。
在C90中,以下代码会导致错误:
const const int a;
int main(void)
{
return(0);
}
但是,对于C99,C编译器接受多个限定符。
Static及数组声明符中允许的其他类型限定符
现在,关键字static可以出现在函数声明符中及参数的数组声明符中,表示编译器至少可以假定许多元素将传递到所声明的函数中。使优化器能够作出以其他方式无法确定的假定。
- C编译器将数组参数调整为指针,因此void foo(int a[]) 与void foo(int *a) 相同。
如果您指定void foo(int * restrict a); 等类型限定符,则C 编译器使用实质上与声明限定指针相同的数组语法void foo(int a[restrict]); 表示它。 - C编译器还使用static限定符保留关于数组大小的信息。例如,如果您指定void foo(int a[10]),则编译器仍将它表达为void foo(int *a)。按以下所示使用static限定符:void foo(int a[static 10]),让编译器知道指针a不是NULL,并且使用它可访问至少包含十个元素的整数数组。
## 其它特性的改动
1.放宽的转换限制
| 限制 | C89标准 | C99标准 |
|---|---|---|
| 数据块的嵌套层数 | 15 | 127 |
| 条件语句的嵌套层数 | 8 | 63 |
| 内部标识符中的有效字符个数 | 31 | 63 |
| 外部标识符中的有效字符个数 | 6 | 31 |
| 结构或联合中的成员个数 | 127 | 1023 |
| 函数调用中的参数个数 | 31 | 127 |
- 不再支持隐含式的int规则
每个声明中的声明说明符中应至少指定一个类型说明符,现在不支持没有类型就默认是int的声明语句。比如在C89中, auto i = 0;是合法的 - 删除了隐含式函数声明
- 对返回值的约束。C99中,非空类型函数必须使用带返回值的return语句
- 扩展的整数类型
| 扩展类型 | 含义 |
|---|---|
| int16_t | 整数长度为精确16位 |
| int_least16_t | 整数长度为至少16位 |
| int_fast32_t | 最稳固的整数类型,其长度为至少32位 |
| intmax_t | 最大整数类型 |
| uintmax_t | 最大无符号整数类型 |
- 对整数类型提升规则的改进。C89中,表达式中类型为char,short int或int的值可以提升为int或unsigned int类型。
- C99中,每种整数类型都有一个级别。例如:long long int 的级别高于int, int的级别高于char等。在表达式中,其级别低于int或unsigned int的任何整数类型均可被替换成int或unsigned int类型。
但是各个公司对C99的支持所表现出来的兴趣不同。当GCC和其它一些商业编译器支持C99的大部分特性的时候,微软和Borland却似乎对此不感兴趣。
C11 标准
- 对齐处理操作符 alignof,函数 aligned_alloc(),以及 头文件
。见 7.15 节。 - _Noreturn 函数标记,类似于 gcc 的 attribute((noreturn))。例子:
_Noreturn void thrd_exit(int res); - _Generic 关键词,有点儿类似于 gcc 的 typeof。示例代码:
#include- 静态断言( static assertions),_Static_assert(),在解释 #if 和 #error 之后被处理。例子:
_Static_assert(FOO > 0, "FOO has a wrong value"); - 删除了 gets() 函数,C99中已经将此函数被标记为过时,推荐新的替代函数 gets_s()。
- 新的 fopen() 模式,(“…x”)。类似 POSIX 中的 O_CREAT|O_EXCL,在文件锁中比较常用。
- 匿名结构体/联合体,这个早已经在 gcc 中了,我们并不陌生,定义在 6.7.2.1 p13。
- 多线程支持,包括:_Thread_local,头文件
,里面包含线程的创建和管理函数(比如 thrd_create(),thrd_exit()),mutex (比如 mtx_lock(),mtx_unlock())等等,更多内容清参考 7.26 节。 - _Atomic类型修饰符和 头文件
,见 7.17 节。 - 带边界检查(Bounds-checking)的函数接口,定义了新的安全的函数,例如 fopen_s(),strcat_s() 等等。更多参考 Annex K。
- 改进的 Unicode 支持,新的头文件
等。实例代码:
#include- 新增 quick_exit() 函数,作为第三种终止程序的方式,当 exit() 失败时可以做最少的清理工作(deinitializition),具体见 7.22.4.7。
- 创建复数的宏, CMPLX(),见 7.3.9.3。
- 更多浮点数处理的宏 (More macros for querying the characteristics of floating point types, concerning subnormal floating point numbers and the number of decimal digits the type is able to store)。
- struct timespec 成为 time.h 的一部分,以及宏 TIME_UTC,函数 timespec_get()。
C和C++做程序的区别
- C是一个结构化语言,它的重点在于算法和数据结构。C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现过程(事务)控制)。
- C++,首要考虑的是如何构造一个对象模型,让这个模型能够契合与之对应的问题域,这样就可以通过获取对象的状态信息得到输出或实现过程(事务)控制。
所以C与C++的最大区别在于它们的用于解决问题的思想方法不一样。之所以说C++比C更先进,是因为“设计这个概念已经被融入到C++之中”。
参考
- 官方标准文档