hadoop的三大核心组件之HDFS和YARN
Hadoop的三大核心组件之HDFS和YARN
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
(1)HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode/SecondaryNameNode。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(3)MapReduce:它其实是一个应用程序开发包。
一、HDFS
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。架构如下图:
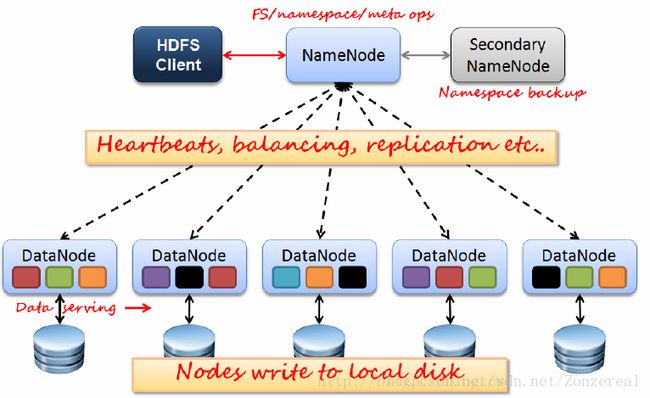
A、NameNode
NameNode管理着文件系统的命名空间,维护着文件系统树,它不存储真实数据,存储元数据(MetaData)[元数据(FileName、副本数、每一个副本所在的位置...)],NameNode保存在内存中。
元数据信息通过以下文件和过程持久化到磁盘中。
a、fsimage--对元数据定期进行镜像
b、edits--存放一定时间内对HDFS的操作记录
c、checkpoint---检查点
Namenode在内存中保存着整个文件系统的名字空间和文件数据块映射(Blockmap)的映像。这个关键的元数据结构设计得很紧凑,因而一个有4G内存的Namenode足够支撑大量的文件和目录。当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用在内存中的FsImage上,并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。这个过程称为一个检查点(checkpoint)。在当前实现中,检查点只发生在Namenode启动时,在不久的将来将实现支持周期性的检查点。
B、DataNode---存储节点,真正存放数据的节点,用于保存数据,保存在磁盘上(在HDFS上保存的数据副本数默认是3个,这个副本数量是可以设置的)。基本单位是块(block),默认128M。
Block块的概念
先不看HDFS的Block,每台机器都有磁盘,机器上的所有持久化数据都是存储在磁盘上的。磁盘是通过块来管理数据的,一个块的数据是该磁盘一次能够读写的最小单位,一般是512个字节,而建立在磁盘之上的文件系统也有块的概念,通常是磁盘块的整数倍,例如几kb。
HDFS作为文件系统,一样有块的概念,对于分布式文件系统,使用文件块将会带来这些好处:
1.一个文件的大小不限制于集群中任意机器的磁盘大小
2.因为块的大小是固定的,相对比不确定大小的文件,块更容易进行管理和计算
3.块同样方便进行备份操作,以提高数据容错性和系统的可靠性
为什么HDFS的块大小会比文件系统的块大那么多呢?
操作数据时,需要先从磁盘上找到指定的数据块然后进行传输,而这就包含两个动作:
1)数据块寻址:找到该数据块的起始位置
2)数据传输:读取数据
也就是说,操作数据所花费的时间是由以上两个步骤一起决定的,步骤1所花费的时间一般比步骤2要少很多,那么当操作的数据块越多,寻址所花费的时间在总时间中就越小的可以忽略不计。所以块设置的大,可以最小化磁盘的寻址开销。但是HDFS的Block块也不能设置的太大,会影响到map任务的启动数,并行度降低,任务的执行数据将会变慢。
★名词扩展:心跳机制、宕机、安全模式(zzy至理名言--“自己看网上都有”)
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
C、SecondaryNameNode---辅助节点,用于同步元数据信息。辅助NameNode对fsimage和edits进行合并(冷备份),下面用SNN代替
NameNode 的元数据信息先往 edits 文件中写,当 edits 文件达到一定的阈值(3600 秒或大小到 64M)的时候,会开启合并的流程。合并流程如下:
①当开始合并的时候,SNN 会把 edits 和 fsimage 拷贝到自己服务器所在内存中,开始合并,合并生成一个名为 fsimage.ckpt 的文件。
②将 fsimage.ckpt 文件拷贝到 NameNode 上,成功后,再删除原有的 fsimage,并将 fsimage.ckpt文件重命名为 fsimage。
③当 SNN 将 edits 和 fsimage 拷贝走之后,NameNode 会立刻生成一个 edits.new 文件,用于记录新来的元数据,当合并完成之后,原有的 edits 文件才会被删除,并将 edits.new 文件重命名为 edits 文件,开启下一轮流程。
二、YARN
A、ResourceManager
B、NodeManager
◆MapReduce 在 YARN 上的执行流程:
①client 提交 job,首先找 ResourceManager(ApplicationsManager)分配资源,同时将 jar 包默认拷贝10 份到 hdfs。
②ResourceManager 指 定 一 个 NodeManager 开 启 一 个 container , 在 Container 中 运 行 一 个ApplicationMaster 来管理这个应用程序。
③ApplicationMaster 会计算此个应用所需资源,向 ResourceManager(ResourceScheduler)申请资源。
④ResourceManager 会分配资源,在 NodeManager上开启不同的 container,在container中来运行 map任务或者 reduce 任务
⑤当所有的 task 都执行完了,ApplicationMaster会将结果反馈给客户端,所有工作执行完成之后,ApplicationMaster 就会自行关闭。
⑥如果某个 map 任务或者 reduce 任务失败,ApplicationMaster会重新申请新的 container 来执行这个task。