XML解析之DOM解析详解
一、概念
xml文件多用于信息的描述,所以在得到一个xml文档之后按照xml中的元素取出对应的信息就是xml的解析。Xml解析有两种方式,一种是DOM解析,另一种是SAX解析,两种操作的方式如图。
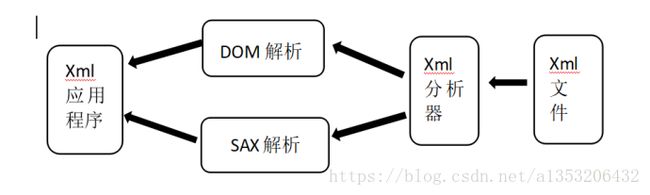
二、DOM解析
基于DOM解析的xml分析器是将其转换为一个对象模型的集合,用树这种数据结构对信息进行储存。通过DOM接口,应用程序可以在任何时候访问xml文档中的任何一部分数据,因此这种利用DOM接口访问的方式也被称为随机访问。
这种方式也有缺陷,因为DOM分析器将整个xml文件转换为了树存放在内存中,当文件结构较大或者数据较复杂的时候,这种方式对内存的要求就比较高,且对于结构复杂的树进行遍历也是一种非常耗时的操作。不过DOM所采用的树结构与xml存储信息的方式相吻合,同时其随机访问还可利用,所以DOM接口还是具有广泛的使用价值。
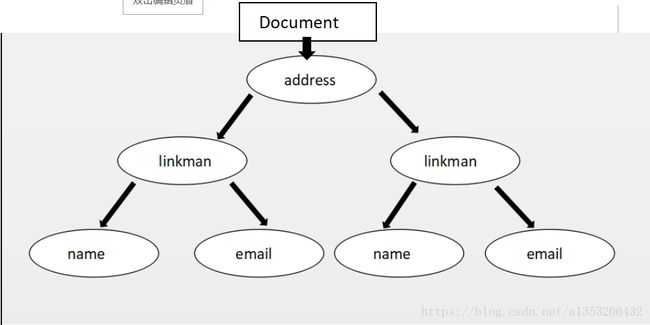
这里我们举个栗子来说明xml转换为树的数据结构。
Van_DarkHolme
[email protected]
Bili
[email protected]
将该xml转换为树的结构为:
DOM解析中有以下4个核心操作接口
Document:此接口代表了整个xml文档,表示为整个DOM的根,即为该树的入口,通过该接口可以访问xml中所有元素的内容。其常用方法如下。
(注:上述图中虽未画出,但是name和email的属性(van_darkhole,[email protected])也分别为一个节点)
Document常用方法
| public NodeList getElementByTagName(String tagname) |
取得指定节点名称的NodeList |
| Public Element createElement(String tagName) throws DOMException |
创建一个指定名称的节点 |
| Public Text createTextNode(String data) throws DOMException |
创建一个文本内容节点 |
| Element createElement(String tagName) throws DOMException |
创建一个节点元素 |
| Public Attr createAttribute(String name)throws DOMException |
创建一个属性 |
Node:此接口在整个DOM树中有着举足轻重的地位,DOM操作的核心接口都继承于Node(Document、Element、Attr)。在DOM树中,每一个Node接口代表了一个DOM树节点
Node接口常用方法
| Node appendChilid(Node newChild) throws DOMException |
在当前节点下增加下一个新节点 |
| Public NodeList getChildNodes() |
取得本节点下的全部子节点 |
| Public Node getFirstChild() |
取得该节点下的第一个子节点 |
| Public Node getLastChild() |
取得本节点下的最后一个子节点 |
| Public boolean hasChildNodes() |
判断是否还有其他节点 |
| String getNodeValue()throws DOMException |
获取节点内容 |
NodeList:此接口表示一个点的集合,一般用于有序关系的一组节点。
NodeList常用方法
| Public int getLength() |
取得NodeList中节点的个数 |
| Public Node item(int index) |
根据索引取得节点对象 |
NamedNodeMap:此接口表示一组节点和其唯一名称对应的一一关系,主要用于节点属性的表示
除了以上四个核心接口外,如果一个程序需要进行DOM解析操作,则需要按照如下步骤进行:
1. 建立DocumentBuilderFactor,用于获得DocumentBuilder对象:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
2. 建立DocumentBuidler:
DocumentBuilder builder = factory.newDocumentBuilder();
3. 建立Document对象,获取树的入口:
Document doc = builder.parse(“xml文件的相对路径或者绝对路径”);
4. 建立NodeList:
NodeList n1 = doc.getElementByTagName(“读取节点”);
5. 进行xml信息获取
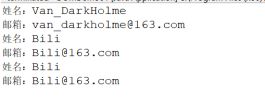
下面则根据上面的xml文件进行解析
public class DOMDemo01 {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException{
//建立DocumentBuilderFactor,用于获得DocumentBuilder对象:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.建立DocumentBuidler:
DocumentBuilder builder = factory.newDocumentBuilder();
//3.建立Document对象,获取树的入口:
Document doc = builder.parse("src//dom_demo_02.xml");
//4.建立NodeList:
NodeList node = doc.getElementsByTagName("linkman");
//5.进行xml信息获取
for(int i=0;i运行结果为:
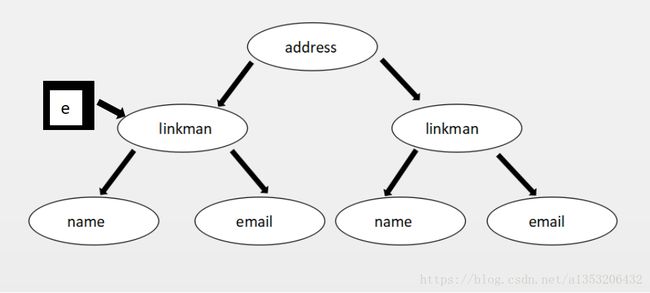
上述代码则从第四处开始分析:
通过doc.getElementByTagName(“linkman”)我们获得了一个NodeList,上述xml文件中包含了两个linkman的节点,所以这里NodeList中包含了两个Node(都是linkman节点),然后通过循环的方法来获取xml文件中的信息。
Element e = (Element)node.item(i)获得了linkman节点,即e这里指向了linkman
e.getElementTagName(“name”).item(0).getFirstChild().getNodeValue();
getElementTagName(“name”);获得了该linkman下的所有name节点(其实就1个);
Item(0);取第一个Name节点(就一个);
getFristChild();获取name节点下的文本节点,即内容van所在的节点(上面已经提到过,文本内容也是一个单独的节点,Document方法列表中的createTextNode()就是创建文本节点);
getNodeValue()获得文本节点的值:van_darkholme;