Hadoop(二)Hive原理解析
一、Hive的起源
Hive起源于Facebook(一个美国的社交服务网络)。Facebook有着大量的数据,而Hadoop是一个开源的MapReduce实现,可以轻松处理大量的数据。但是MapReduce程序对于Java程序员来说比较容易写,但是对于其他语言使用者来说不太方便。此时Facebook最早地开始研发Hive,它让对Hadoop使用SQL查询(实际上SQL后台转化为了MapReduce)成为可能,那些非Java程序员也可以更方便地使用。hive最早的目的也就是为了分析处理海量的日志。
二、Hive是什么
Apache Hive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在Apache Hadoop之上,主要提供以下功能:它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制;查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如select * from XXX就不需要;在Hive0.11对类似select a,b from XXX的查询通过配置也可以不通过MapReduce来完成。
从上面的定义我们可以了解到,Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理;那么,我们如何来分析和管理那些数据呢?
Hive定义了一种类似SQL的查询语言,被称为HQL,对于熟悉SQL的用户可以直接利用Hive来查询数据。同时,这个语言也允许熟悉 MapReduce 开发者们开发自定义的mappers和reducers来处理内建的mappers和reducers无法完成的复杂的分析工作。Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:User Defined Functions(UDF)、User Defined Aggregation Functions(UDAF)、User Defined Table Generating Functions(UDTF)。
今天,Hive已经是一个成功的Apache项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。
当然,Hive和传统的关系型数据库有很大的区别,Hive将外部的任务解析成一个MapReduce可执行计划,而启动MapReduce是一个高延迟的一件事,每次提交任务和执行任务都需要消耗很多时间,这也就决定Hive只能处理一些高延迟的应用(如果你想处理低延迟的应用,你可以去考虑一下Hbase)。同时,由于设计的目标不一样,Hive目前还不支持事务;不能对表数据进行修改(不能更新、删除、插入;只能通过文件追加数据、重新导入数据);不能对列建立索引(但是Hive支持索引的建立,但是不能提高Hive的查询速度。如果你想提高Hive的查询速度,请学习Hive的分区、桶的应用)。
三、Hiver特点
- 它存储架构在一个数据库中并处理数据到HDFS。
- 它是专为OLAP设计。
- 它提供SQL类型语言查询叫HiveQL或HQL。
- 它是熟知,快速,可扩展和可扩展的。
四、Hive架构
下面的组件图描绘了Hive的结构:
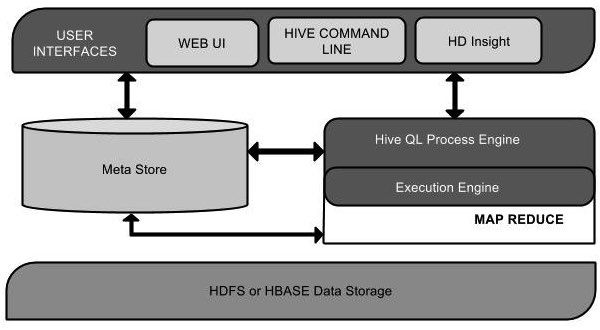
该组件图包含不同的单元。下表描述每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
五、Hive工作原理
下图描述了Hive 和Hadoop之间的工作流程。
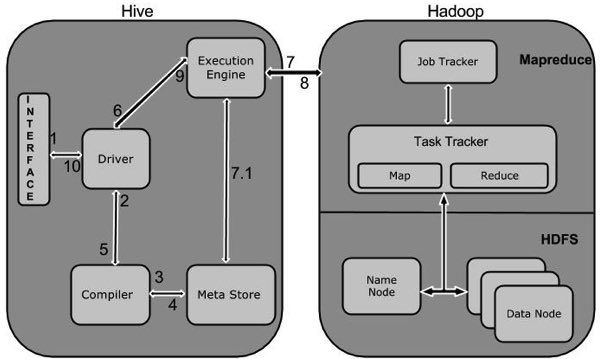
下表定义Hive和Hadoop框架的交互方式:
| Step No. | 操作 |
|---|---|
| 1 | Execute Query Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 | Get Plan 在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 |
| 3 | Get Metadata 编译器发送元数据请求到Metastore(任何数据库)。 |
| 4 | Send Metadata Metastore发送元数据,以编译器的响应。 |
| 5 | Send Plan 编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 | Execute Plan 驱动程序发送的执行计划到执行引擎。 |
| 7 | Execute Job 在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。 |
| 7.1 | Metadata Ops 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 8 | Fetch Result 执行引擎接收来自数据节点的结果。 |
| 9 | Send Results 执行引擎发送这些结果值给驱动程序。 |
| 10 | Send Results 驱动程序将结果发送给Hive接口。 |
六、Hive的适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
七、Hive中表的分类
- 内部表
- 外部表
- 分区表
- 桶表
内部表:什么是内部表需要对比外部表来看
•删表时数据和表一起删除
外部表:
•数据已经存在于HDFS
•外部表只是走一个过程,加载数据和创建表同时完成,不会移动到数据仓库目录中,仅仅是和数据建立了一个连接
•删表数据不会删除数据
内部表外部表区分:
在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而内部表表则不一样;在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
分区表:
•在Hive Select查询中,一般会扫描整个表内容,会消耗很多时间做没必要的工作。 分区表指的是在创建表时,指定partition的分区空间。扫描时可以只扫描某一个分区的数据
•分区表存储时分局所设立的分区分别存储数据(分区字段就是一个文件夹的标识)
桶表:
•对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说捅是更为细粒度的数据范困划分。
•桶表是对指定的分桶的列进行哈希运算,运算结果模(%)分桶的数量然后把数据根据运算结果分别放入这几个桶中
八、Hive与HBase的联系和区别
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
1、联系
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
2、区别
1). Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。Hive本身不存储数据,它完全依赖HDFS和MapReduce。这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能,并将SQL语句最终转换为MapReduce任务进行运行。 而HBase表是物理表,适合存放非结构化的数据。
2). Hive是基于MapReduce来处理数据,而MapReduce处理数据是基于行的模式;HBase处理数据是基于列的而不是基于行的模式,适合海量数据的随机访问。
3). HBase的表是疏松的存储的,因此用户可以给行定义各种不同的列;而Hive表是稠密型,即定义多少列,每一行有存储固定列数的数据。
4). Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,因此不能保证处理的低迟延问题;而HBase是近实时系统,支持实时查询。
5). Hive不提供row-level的更新,它适用于大量append-only数据集(如日志)的批任务处理。而基于HBase的查询,支持和row-level的更新。
6). Hive提供完整的SQL实现,通常被用来做一些基于历史数据的挖掘、分析。而HBase不适用与有join,多级索引,表关系复杂的应用场景。