聚簇索引和非聚簇索引区别
聚簇索引和非聚簇索引区别
MySQL的聚簇索引是指Innodb引擎的特性,MySIAM并没有,如果需要该索引,只要将索引指定为主键(primary key)就可以了。
聚集(clustered)索引,也称聚簇索引。聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。Innodb引擎的聚簇索引实际上存放了B+树索引和数据行。所以由于无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。 在Innodb引擎下,有主键时,根据主键创建聚簇索引;没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引,如果以上两个都不满足,那Innodb自己创建一个虚拟的聚集索引。
优点:
1.数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快。
2.聚簇索引对于主键的排序查找和范围查找速度非常快。
缺点:
1.插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
2.更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
3.二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
非聚集索引,也称非聚簇索引(有时也叫二级索引)。除了聚簇索引以外的索引,统称为非聚簇索引。
在聚簇索引之上创建的索引称之为辅助索引,**辅助索引访问数据总是需要二次查找。**辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
Innodb辅助索引的叶子节点并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了相应行数据的聚簇索引键。辅助索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个辅助索引。
讲完了定义,下面,我们可以看一下MYSQL中MYISAM和INNODB两种引擎的索引结构。
首先看MYISAM的,因为MYISAM里并没有聚簇索引,所以MYISAM的索引都是非聚簇索引的!
首先创建表
CREATE TABLE layout_test(
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
数据在MyISAM中是这样分布的。在行的旁边显示了行号,从0开始递增。
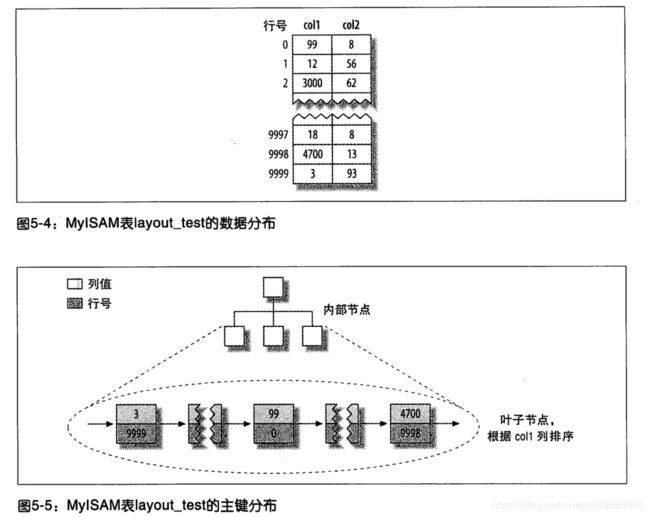
那col2列上的索引又是怎样呢?答案是它跟其他索引没有什么区别。

下面看InnoDB的数据分布。由于InnoDB支持聚簇索引,所以使用非常不同的方式存储同样的数据。如图所示:
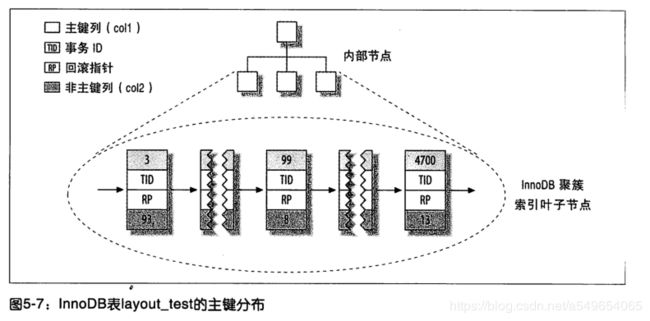
一眼看上去可能跟MyISAM的非聚簇索引没有什么区别。其实不然,聚簇索引的每一个叶子节点都包含了主键值、事务ID、用于事务和MVVC的回滚指针以及所有剩余列(这个例子中是col2)。
可能看完了上面,还有点混乱。再看一个例子。
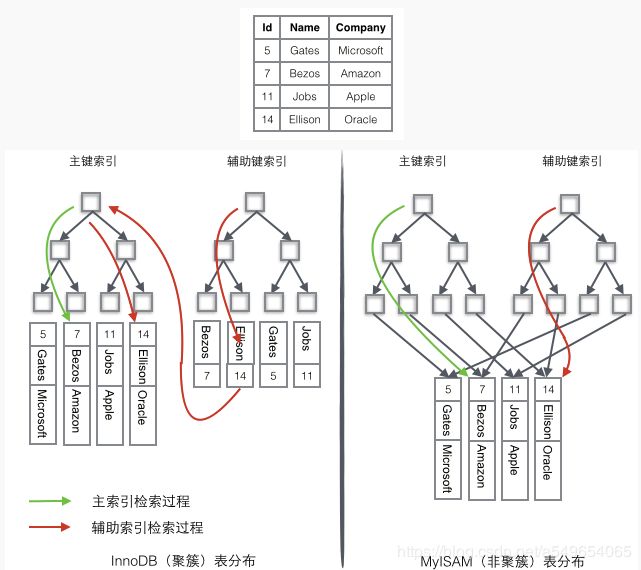
上面的图中属于聚簇索引的只有左边的主键索引,其他的都是非聚簇索引。
InnoDB的的二级索引(辅助键索引)的叶子节点存放的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键。简单地说,聚簇索引直接能搜索叶节点的时候就能搜索到数据,而非聚簇索引搜索到叶节点还得再去根据指针找到相应的数据,显然,聚簇索引比较快。
聚簇索引和非聚簇索引的区别:
聚簇索引一个表只能有一个,非聚簇索引一个表可以有多个。
聚簇索引的叶子节点存放的是主键值和数据行,一般为表的主键(主索引),支持覆盖索引。
非聚簇索引的叶子节点存放的是主键值或指向数据行的指针,因此在使用辅助索引进行查找时,需要先查找到主键值,然后在通过主索引进行查找。
参考博客:https://www.xuejiayuan.net/blog/9b93a02df0da42b4b06074b01ef46a21