Voice Conversion 项目笔记(含从VCC 2016匿名比赛深挖的各前沿方法性能对比)
voice conversion 基本架构:
voice conversion 任务主要由两个步骤构成,特征提取与特征参数转换,对于这两个步骤,都有相应的常用的技术,这两个步骤中常用的技术各种排列组合,就产生了众多VC系统,以下做小汇总。
| STEP1:Feature extraction | STEP2:Feature conversion | ||
| Feature | Extraction toolkits | description | |
| LSF(Line Spectral Frequency) | STRAIGHT | STRAIGHT is an MATLAB Lib design for VC. | GMM/JDGMM |
| MGC(mel-generalized coeffi- cient ) |
STRAIGHT | DNN | |
| LF0(log f0) | AHOCODER | Ahocoder parameterizes speech waveforms into three different streams | RNN(BLSTM) |
| MCP(mel-spectgram) | AHOCODER | seq2seq/(with Attention) | |
| MVF(maximum voiced frequency) | AHOCODER | GRU | |
| DBN | VQ | ||
| Mixture of Factor Analyzer | |||
| parameter generation algorithm with global variance | HTS | HMM-based Speech Synthesis System |
其中,LF0为语音基频log变换,为主要的语音转换参数,是表征不同人,不同性别的最重要参数之一。
其他参数为语音的高阶分量,控制合成语音的细节。
衡量标准:
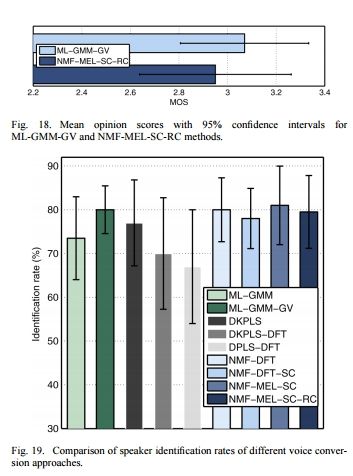
常用的两种:基于主观评分的MOS和基于Mel谱失真的MCD
MOS(
Mean Opinion Score) 主观评分 分值1-5 由受试者主观打分 一般有GMM方法的MOS分作为beseline,对于不同的测试可以考虑把GMM的分数对齐从而在不同的MOS测试中统一基准
打分基准:
4-5分 优秀(excelent) 很好,听的清楚,延迟很小,交流流畅
3-4分 良好(good) 稍差,听的清楚,延迟小,交流欠缺顺畅,有点杂音
2-3分 一般(fair) 还可以,听不太清,有一定延迟,可以交流
1-2分 差(poor) 勉强,听不太清,延迟较大,交流重复多次1分以下 很差(bad) 极差,听不懂,延迟大,交流不通畅
MCD(Mel-cepstral distortion)[dB] 越低越好
例:
seq2seq with LSTM:
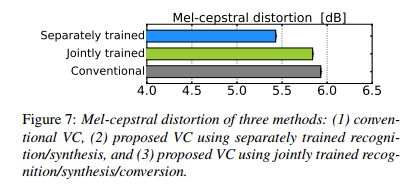
Variational Auto-encoder:
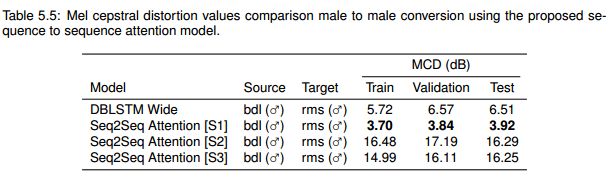
Deep sequence-to-sequence Attention Model :
VCC2016:
各组综合分数对比:

各组方案对比(红圈为MOS>2.5 similarity>60%的方案,紫色横线表示不会公开方法的组别)
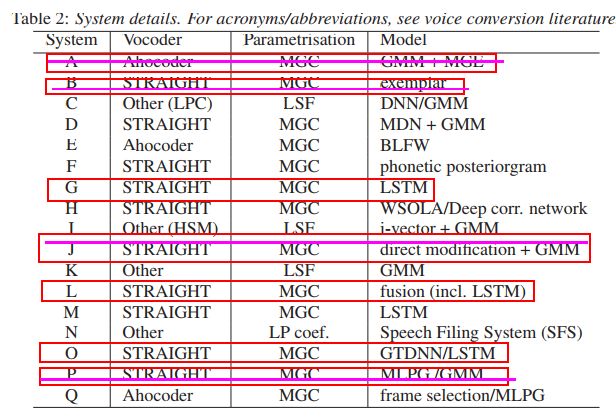
其中G,L,O 组
很多都采用了STRAIGHT工具包进行MGC特征的提取
转换方法上,常采用GMM或者LSTM方法
开源的组转换结果样例:
效果较好的:
略逊的:
各组的报告,包括使用的参数,工具包,及其方法:
各组来源:

现在可用的转换方法:
用不同的神经网络对不同参数进行转换
用AHOcoder进行特征提取:
LF0:LSTM
MVF:DNN
MCP:GRU
转换结果样例:(基于VCC2016 数据)
基于LSF LF0 UV的方法:
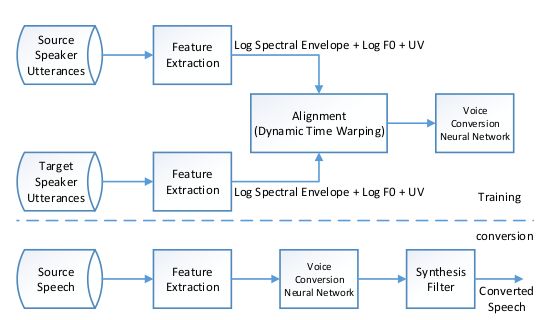
转换结果样例:
还在下载
基于GMM的转换:
利用SPTK提取MCEP参数,对MCEP参数用24阶GMM进行转换:
转换结果样例:
各机构的Demo:
Voice Conversion 方法,链接如下:
- LyreBird : https://lyrebird.ai/demo
- 微软:DNN VC
- 香港科技大学:BLSTM VC
- 印度OHSU:Joint AE VC
- 日本东京大学:GMM VC
- 法国tut:基于DKPL回归
- Voice Morphing:Voice Morphing
- Adobe VOCO:http://ieeexplore.ieee.org/abstract/document/7472761/
TTS方法,链接如下:
- ModelTalker :(采集语音以进行语音合成):https://www.modeltalker.org/
- 日本Kobayashi 实验室:Speaker-Independent HMM-Based Voice Conversion
- 爱丁堡大学:Listening test materials for “A study of speaker adaptation for DNN-based speech synthesis”
- TOKUDA and NANKAKU LABORATORY
- Princeton VOCO:http://gfx.cs.princeton.edu/pubs/Jin_2017_VTI/【5月11日发表】【10分钟音频内寻找最接近音素】
建议:
在VCC2016比赛中,效果较好的组在语音特征提取的环节都采用了STRAIGHT工具包,应对此进行进一步的探索
未开源及展示论文的方案可能由于经过cherry-picked的调参,复现可能有一定困难
开源的方案主要是都以LSTM作为主要模型,用于转换LF0,MCEP等特征
现有的转换方法中,以基于GMM的MCEP特征转换作为基准,利用LSTM转换LF0的这种方法性能较好,其MOS评分应在2-3分左右,普分辨率较低
可以用STRAIGHT替换AHOcoder进行特征提取,并使用LSTM进行LF0和MCEP的转换(尝试研究G组的方案)。
参考论文及其性能展示:
常用传统转换技术对比(不包括各类神经网络方法):
https://arxiv.org/pdf/1612.07523.pdf

IEEE(只看了一下,包括其中G组的方案):
Voice conversion using deep neural networks with speaker-independent pre-training
http://ieeexplore.ieee.org/document/7078543/
Dictionary update for NMF-based voice conversion using an encoder-decoder network
http://ieeexplore.ieee.org/document/7918382/
Text-independent voice conversion using deep neural network based phonetic level features
http://ieeexplore.ieee.org/document/7918382/
F0 transformation techniques for statistical voice conversion with direct waveform modification with spectral differential
http://ieeexplore.ieee.org/document/7846338/
Enhancing a glossectomy patient's speech via GMM-based voice conversion
http://ieeexplore.ieee.org/document/7820909/
Deep neural network based voice conversion with a large synthesized parallel corpus
http://ieeexplore.ieee.org/document/7820716/
SEQ2SEQ类:
https://arxiv.org/pdf/1704.02360.pdf
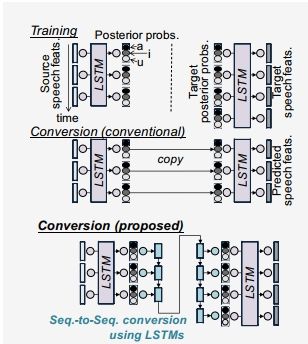
Voice Conversion Using Sequence-to-Sequence Learning of Context Posterior Probabilities
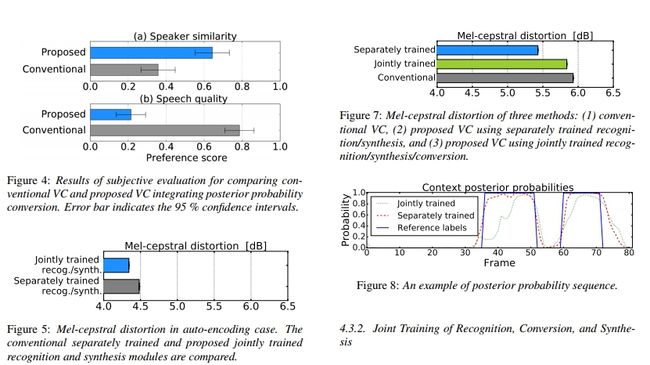
Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
https://arxiv.org/pdf/1704.00849.pdf

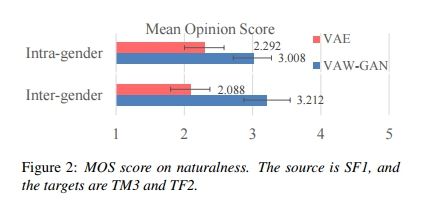
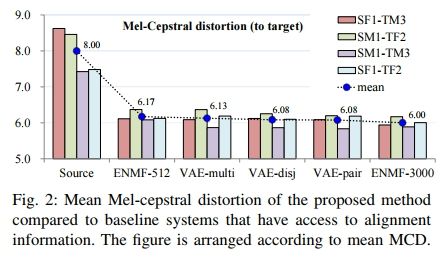
VAE:
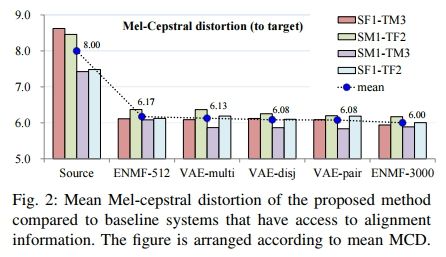
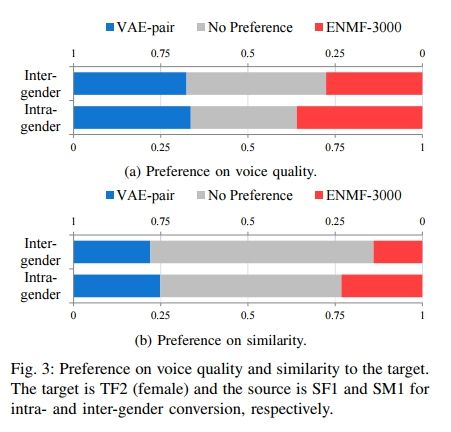
Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder
https://arxiv.org/pdf/1610.04019.pdf
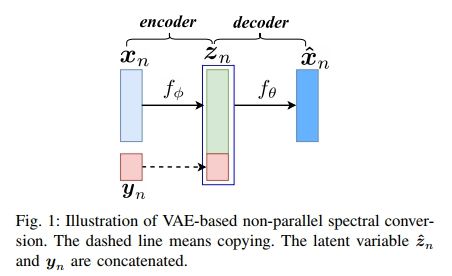
DNN:

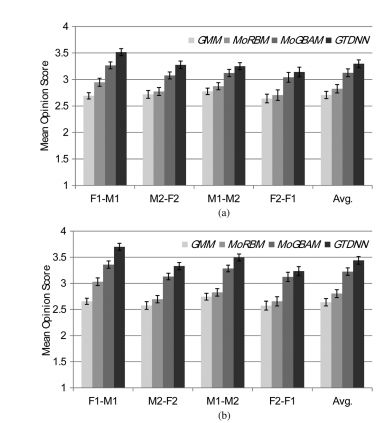

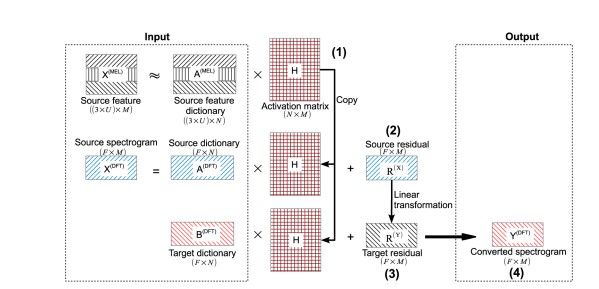

4 Proposed Framework: Deep sequence-to-sequence Attention Model
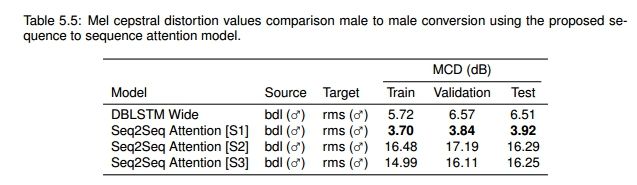
寻找对应组:
I组:NII National Institute of Informatics:
http://cs.joensuu.fi/pages/tkinnu/webpage/pdf/i-vector-VC_icassp2017.pdf
NON-PARALLEL VOICE CONVERSION USING I-VECTOR PLDA: TOWARDS UNIFYING SPEAKER VERIFICATION AND TRANSFORMATION

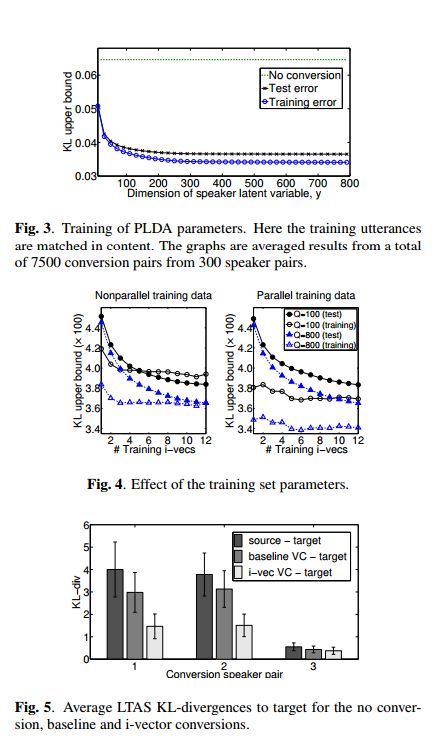
L组:西北工业大学,谢磊:
http://www.nwpu-aslp.org/lxie/papers/ssw9_PS1-4_Huang.pdf
An Automatic Voice Conversion Evaluation Strategy Based on Perceptual Background Noise Distortion and Speaker Similarity

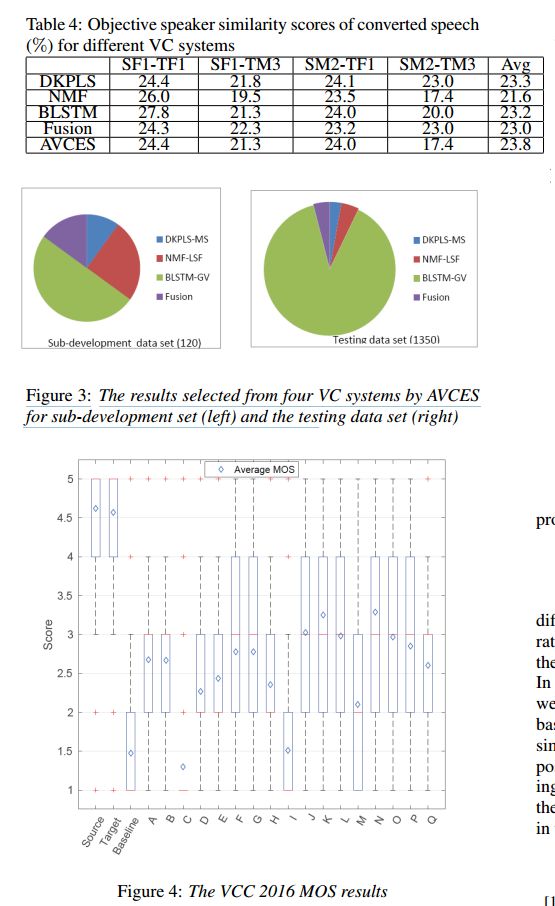
J组:NU-NAIST:
F0 transformation techniques for statistical voice conversion with direct waveform modification with spectral differential
http://ieeexplore.ieee.org/abstract/document/7846338/
C组:UTSC-NELLSILP:(jun du)
https://www.researchgate.net/publication/307889222_The_USTC_System_for_Voice_Conversion_Challenge_2016_Neural_Network_Based_Approaches_for_Spectrum_Aperiodicity_and_F0_Conversion
未知:University College London voice conversion challenge:
Hulk组【G组】:
Phone-aware LSTM-RNN for voice conversion
http://ieeexplore.ieee.org/abstract/document/7877819/
B组:Zhizheng WU:
CSTR The Centre for Speech Technology Research, The University of Edinburgh, UK
http://ieeexplore.ieee.org/abstract/document/7472761/
https://link.springer.com/article/10.1007/s11042-014-2180-2
F组:HCCL-CUHK Human-Computer Communications Laboratory
The Chinese University of Hong Kong, Hong Kong
http://www1.se.cuhk.edu.hk/~lfsun/ICME2016_Lifa_Sun.pdf
日本人的复现:
https://github.com/sesenosannko/ppg_vc
【一个用DNN的组(O(也有可能是C))】VoiceKontrol Center for Spoken Language Understanding (CSLU), Oregon Health & Science University, Portland, OR, USA
S.H. Mohammadi, A. Kain, Semi-supervised Training of a Voice Conversion Mapping Function using Joint-Autoencoder, Interspeech (To Appear), 2015.
S.H. Mohammadi, A. Kain, Voice Conversion Using Deep Neural Networks With Speaker-Independent Pre-Training, 2014 IEEE Spoken Language Technology Workshop (SLT), 2014.
复现:
https://github.com/shamidreza/dnnmapper
还没找到的:
1.
CASIA-NLPR-Taogroup National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, China
2.
Team Initiator Tsinghua University, Beijing, China
3.
AST Academia Sinica, Taipei, Taiwan
https://arxiv.org/pdf/1610.04019.pdf
https://github.com/JeremyCCHsu/vae4vc
github:
RNN:
https://github.com/Pooja-Donekal/Voice-Conversion
LSTM:(还不错)(F组)
https://github.com/sesenosannko/ppg_vc
Pitchlinear conversion:
https://github.com/cc786537662/VC
相位加速:
https://github.com/PJunhyuk/voice-conversion
DNN+mfcc(C/O组)
https://github.com/shamidreza/dnnmapper
STRAIGHT,F0,GMM
https://github.com/hiromu/VoiceConversion
GMM
https://github.com/r9y9/VoiceConversion.jl
VAE:
https://github.com/JeremyCCHsu/vae4vc
5月18日更新:
LyreBird的在ICLR 2017上的论文:
SAMPLERNN: AN UNCONDITIONAL END-TO-END
NEURAL AUDIO GENERATION MODEL
https://arxiv.org/pdf/1612.07837.pdf
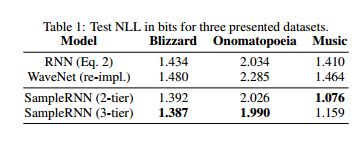
法语语音转换公司CandyVoice:
https://candyvoice.com/demos/voice-conversion
基于发声系统建模的发声系统建模器festvox:flite
http://www.festvox.org/transform/
Flite
TTS Demo:
http://tts.speech.cs.cmu.edu:8083/
princeton VOCO :
http://gfx.cs.princeton.edu/pubs/Jin_2017_VTI/
1.先用相同性别/年龄段的TTS进行发音
2.基于CUTE技术进行波形拟合和编辑——跟adobe VOCO师出同源
这就是VOCO,都是Zeyu Jin的东西
http://gfx.cs.princeton.edu/pubs/Jin_2016_CAC/CUTE-icassp_2016.pdf