android源码分析-------LinkedHashMap,HashMap
这篇文章是LurCache源码分析的后续,如果想看LurCache源码分析,请转上一篇:《 避免OOM系列之(二)-------LruCache使用以及源码详细解析》。
我们先来看下继承关系:

我们看到LinkedHashMap 继承HashMap ,HashMap继承AbstractMap,如果你查看AbstractMap源码会发现,AbstractMap实现了Map,所有我们就从Map开始分析:
Map:
//map接口功能类
public interface Map {
//单个元素,接口功能类
public static interface Entry {
//是否相等
public boolean equals(Object object);
//获取key
public K getKey();
//获取value
public V getValue();
//获取哈希值
public int hashCode();
//设置值
public V setValue(V object);
};
//清空
public void clear();
//是否包含key
public boolean containsKey(Object key);
//是否包含这个值
public boolean containsValue(Object value);
//获取map中的元素结合(最核心的方法)
public Set> entrySet();
//是否相等
public boolean equals(Object object);
//获取元素
public V get(Object key);
//获取哈希code
public int hashCode();
//判断是否为空
public boolean isEmpty();
//获取key的集合(核心)
public Set keySet();
//存放元素
public V put(K key, V value);
//存放元素结合
public void putAll(Map map);
//移除元素
public V remove(Object key);
//当前大小
public int size();
//获取当前值得集合(核心)
public Collection values();
}
可以看到Map,其实就是功能接口,只要关注Entry<K,V>,entrySet(),values(),keySet()的实现就可以了,剩下的只是一些常用的方法。
AbstractMap:
虽然
AbstractMap,实现了Map一部分方法和类,但是在HashMap中都已经被重写了,所有不需要关注。HashMap
是我们分析的核心。
HashMap(重点):
public class HashMap extends AbstractMap implements Cloneable, Serializable {
//数组最小元素个数
private static final int MINIMUM_CAPACITY = 4;
//数组最大元素个数(2的30次方)
private static final int MAXIMUM_CAPACITY = 1 << 30;
//空数组,初始化元素个数(2)
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
//当元素个数到达(3/4)数量是,扩展
static final float DEFAULT_LOAD_FACTOR = .75F;
//核心数组(table)
transient HashMapEntry[] table;
//key值为NULL的元素
transient HashMapEntry entryForNullKey;
//数组元素的个数
transient int size;
//元素修改的次数(包括添加修改删除更新)
transient int modCount;
//这三个字段,只有被用的时候才参数
//key集合
private transient Set keySet;
//元素集合
private transient Set> entrySet;
//值集合
private transient Collection values;
//capacity,必须是2的整数倍,
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry[] tab = (HashMapEntry[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
//如果capacity不是2的整数倍,就将他转成比capacity小的,2的整数倍值
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
//扩大数组元素个数
makeTable(capacity);
}
上面是HashMap中主要的字段,和构造函数。从字段中可以看出
HashMap真正存储数据的是table,那我们先来分析table:
首先table是一个数组,那么数据结构就是这样:

那么元素又是什么呢?HashMapEntry,让我们来看下
HashMapEntry源码:
//实现了Map.Entry接口
static class HashMapEntry implements Entry {
//key
final K key;
//value
V value;
//哈希值
final int hash;
//指向下一个元素
HashMapEntry next;
HashMapEntry(K key, V value, int hash, HashMapEntry next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry e = (Entry) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}
我们看源码发现,
其实就是一个单向链表(元素),那map是怎么来存储元素的呢?
我们来看下put方法:
//添加元素
@Override public V put(K key, V value) {
//如果key为空,就将元素添加到entryForNullKey
if (key == null) {
return putValueForNullKey(value);
}
//得到key的hashcode
int hash = secondaryHash(key);
HashMapEntry[] tab = table;
//根据hash值计算出数组下标
int index = hash & (tab.length - 1);
//遍历元素,如果有这个元素,就直接返回
for (HashMapEntry e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
//如果元素的个数大于容量的3/4 .就扩展一倍容量,并且得到新的下标好
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
//添加新的元素,如果对应下标有元素,就将新的元素添加到这个元素的后面,形成单向链表
addNewEntry(key, value, hash, index);
return null;
}可以看到,table中的元素其实就是单向链表,那么现在的table数据结构就是:
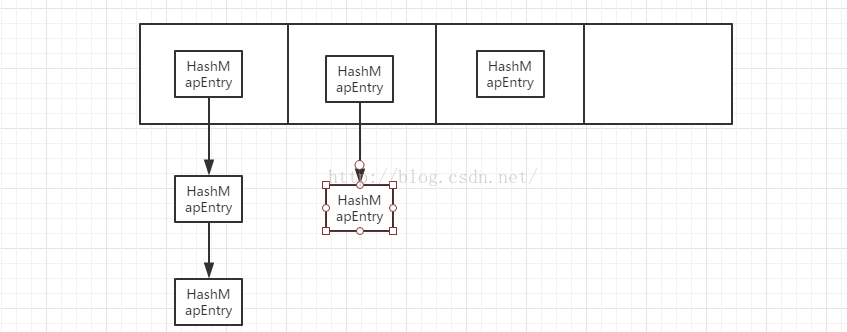
我们已经得到了HashMap的数据结构,就是数组和单向链表构成,这个被称作“散列“。
HashMap查找元素时使用的是hash,这个大家可能很不理解,为什么要使用hash,主要的原因是快,不需要遍历来查找元素,
只需要key的hash,和表的长度,据可以得到下标,直接一步定位。
分析keySet,entrySet,values,这几个字段是遍历时使用,下面通过源码来看下值得由来:
//获取元素集合
public Set> entrySet() {
Set> es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
}
//获取key集合
@Override public Set keySet() {
Set ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet());
}
//获取value集合
@Override public Collection values() {
Collection vs = values;
return (vs != null) ? vs : (values = new Values());
}
可以看出,迭代数据时,得到的是EntrySet,KeySet,Values三个对象,我们继续看源码:
//得到table中的所有元素,
private abstract class HashIterator {
int nextIndex;
HashMapEntry nextEntry = entryForNullKey;
HashMapEntry lastEntryReturned;
int expectedModCount = modCount;
HashIterator() {
if (nextEntry == null) {
HashMapEntry[] tab = table;
HashMapEntry next = null;
while (next == null && nextIndex < tab.length) {
next = tab[nextIndex++];
}
nextEntry = next;
}
}
public boolean hasNext() {
return nextEntry != null;
}
//得到table中的所有元素
HashMapEntry nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == null)
throw new NoSuchElementException();
HashMapEntry entryToReturn = nextEntry;
HashMapEntry[] tab = table;
HashMapEntry next = entryToReturn.next;
while (next == null && nextIndex < tab.length) {
next = tab[nextIndex++];
}
nextEntry = next;
return lastEntryReturned = entryToReturn;
}
public void remove() {
if (lastEntryReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
HashMap.this.remove(lastEntryReturned.key);
lastEntryReturned = null;
expectedModCount = modCount;
}
}
//key迭代器类
private final class KeyIterator extends HashIterator
implements Iterator {
public K next() { return nextEntry().key; }
}
//value迭代器类
private final class ValueIterator extends HashIterator
implements Iterator {
public V next() { return nextEntry().value; }
}
//元素迭代器类
private final class EntryIterator extends HashIterator
implements Iterator> {
public Entry next() { return nextEntry(); }
}
//得到迭代器的方法
Iterator newKeyIterator() { return new KeyIterator(); }
Iterator newValueIterator() { return new ValueIterator(); }
Iterator> newEntryIterator() { return new EntryIterator(); }
//key集合的类
private final class KeySet extends AbstractSet {
//迭代器实现
public Iterator iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
int oldSize = size;
HashMap.this.remove(o);
return size != oldSize;
}
public void clear() {
HashMap.this.clear();
}
}
//value集合的类
private final class Values extends AbstractCollection {
//迭代器实现
public Iterator iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
//元素集合的类
private final class EntrySet extends AbstractSet> {
//迭代器实现
public Iterator> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry) o;
return containsMapping(e.getKey(), e.getValue());
}
public boolean remove(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry)o;
return removeMapping(e.getKey(), e.getValue());
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public void clear() {
HashMap.this.clear();
}
}
我们看到,这三个类只是将我们的table中元素封装到set,Collection中,来实现对hashmap元素的迭代。还是一些
获取数据,删除数据,清空,拷贝等常用方法,不在介绍,如果明白上面图中的数据结构,那么代码就很简单了。
接下来我们看下,lrucache中使用的LinkedHashMap,看看它是怎么排序的?怎么快速找到元素的?
LinkedHashMap:
//头节点(双向链表)
transient LinkedEntry header;
//是否按照最近访问排序
private final boolean accessOrder;
public LinkedHashMap(
int initialCapacity, float loadFactor, boolean accessOrder) {
//初始化hashmap
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
}
//双向链表节点
static class LinkedEntry extends HashMapEntry {
//指向next元素
LinkedEntry nxt;
//指向前面元素
LinkedEntry prv;
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
LinkedEntry(K key, V value, int hash, HashMapEntry next,
LinkedEntry nxt, LinkedEntry prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}
可以看到
LinkedHashMap本质上就是双向链表,结构如下:

//添加新的元素
@Override void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry header = this.header;
//获取最老的元素
LinkedEntry eldest = header.nxt;
//
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
//添加新元素,将header->pre指向新的元素
LinkedEntry oldTail = header.prv;
LinkedEntry newTail = new LinkedEntry(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
}
//添加key 为null的元素,并且添加到链表中
@Override void addNewEntryForNullKey(V value) {
LinkedEntry header = this.header;
// Remove eldest entry if instructed to do so.
LinkedEntry eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
// Create new entry, link it on to list, and put it into table
LinkedEntry oldTail = header.prv;
LinkedEntry newTail = new LinkedEntry(
null, value, 0, null, header, oldTail);
entryForNullKey = oldTail.nxt = header.prv = newTail;
}
@Override HashMapEntry constructorNewEntry(
K key, V value, int hash, HashMapEntry next) {
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
LinkedEntry newTail
= new LinkedEntry(key, value, hash, next, header, oldTail);
return oldTail.nxt = header.prv = newTail;
}
//获取元素
@Override public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
// Replace with Collections.secondaryHash when the VM is fast enough (http://b/8290590).
int hash = secondaryHash(key);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
}
return null;
}
//将head ->pre指向最新操作的元素
private void makeTail(LinkedEntry e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}
//移除后,将引用全部去掉
@Override void postRemove(HashMapEntry e) {
LinkedEntry le = (LinkedEntry) e;
le.prv.nxt = le.nxt;
le.nxt.prv = le.prv;
le.nxt = le.prv = null; // Help the GC (for performance)
}
//是否包括value
@Override public boolean containsValue(Object value) {
if (value == null) {
for (LinkedEntry header = this.header, e = header.nxt;
e != header; e = e.nxt) {
if (e.value == null) {
return true;
}
}
return false;
}
// value is non-null
for (LinkedEntry header = this.header, e = header.nxt;
e != header; e = e.nxt) {
if (value.equals(e.value)) {
return true;
}
}
return false;
}
//清空,然后将引用去掉
public void clear() {
super.clear();
// Clear all links to help GC
LinkedEntry header = this.header;
for (LinkedEntry e = header.nxt; e != header; ) {
LinkedEntry nxt = e.nxt;
e.nxt = e.prv = null;
e = nxt;
}
header.nxt = header.prv = header;
}
我们现在在来分析下节点数据
LinkedHashMap:
1.LinkedEntry是继承HashMapEntry,并且还是添加到hashmap的tab中,
2.
LinkedHashMap对添加元素,获取元素,删除元素,清空,进行了重写,目的是双向链表的链表建立和去除,保证元素的引用及时改变,帮助
GC回收。
3。
每次添加,修改,获取元素时,都将header->pre指向被操作的元素,这样就保证了排序
LinkedHashMap的结构图:
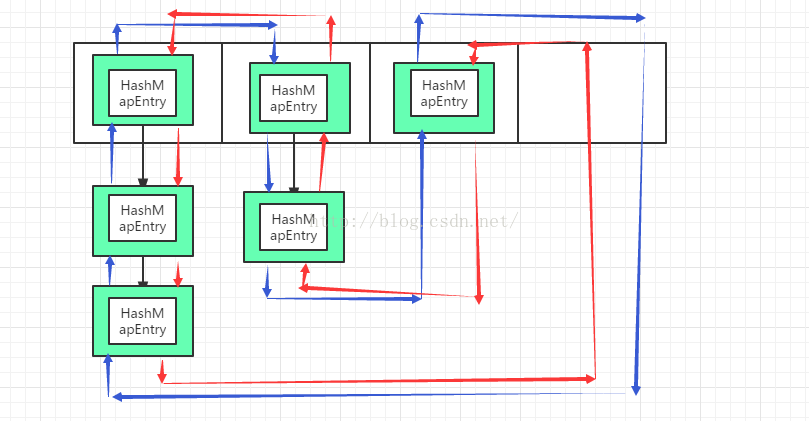
今天就到这里吧,谢谢。