hadoop的单机版测试和集群节点的搭建
Hadoop技术原理:
Hdfs主要模块:NameNode、DataNode
Yarn主要模块:ResourceManager、NodeManager常用命令:
1)用hadoop fs 操作hdfs网盘,使用Uri的格式访问
2)使用start-dfs.sh启动hdfsHDFS主要模块及运行原理:
1)NameNode:
功能:是整个文件系统的管理节点。维护整个文件系统的文件目录树,文件/目录的元数据和
每个文件对应的数据块列表。接收用户的请求。
2)DataNode:
功能:是HA(高可用性)的一个解决方案,是备用镜像,但不支持热备系统环境:
RHEL6.5 selinux and iptables is disabled
Hadoop 、jdk、zookeeper 程序使用 nfs 共享同步配置文件软件版本:
hadoop-2.7.3.tar.gz zookeeper-3.4.9.tar.gz jdk-7u79-linux-x64.tar.gz
hbase-1.2.4-bin.tar.gzhadoop单机版测试
[root@server1 ~]# useradd -u 800 hadoop 建立用户
[root@server1 ~]# passwd hadoop 设置密码
[root@server1 ~]# su hadoop
[hadoop@server1 ~]$ pwd
/home/hadoop
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
hadoop的安装配置:
[hadoop@server1 ~]$ tar zxf jdk-7u79-linux-x64.tar.gz 解压
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk
jdk1.7.0_79/ jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.7.0_79/ java 制作软链接
[hadoop@server1 ~]$ pwd
/home/hadoop
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf hadoop-2.7.3.tar.gz 解压
[hadoop@server1 ~]$ ls
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
[hadoop@server1 ~]$ cd hadoop-2.7.3
[hadoop@server1 hadoop-2.7.3]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
[hadoop@server1 hadoop-2.7.3]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ ls
capacity-scheduler.xml kms-env.sh
configuration.xsl kms-log4j.properties
container-executor.cfg kms-site.xml
core-site.xml log4j.properties
hadoop-env.cmd mapred-env.cmd
hadoop-env.sh mapred-env.sh
hadoop-metrics2.properties mapred-queues.xml.template
hadoop-metrics.properties mapred-site.xml.template
hadoop-policy.xml slaves
hdfs-site.xml ssl-client.xml.example
httpfs-env.sh ssl-server.xml.example
httpfs-log4j.properties yarn-env.cmd
httpfs-signature.secret yarn-env.sh
httpfs-site.xml yarn-site.xml
kms-acls.xml
配置环境变量:
[hadoop@server1 hadoop]$ vim hadoop-env.sh
25 export JAVA_HOME=/home/hadoop/java
[hadoop@server1 hadoop]$ cd
[hadoop@server1 ~]$ vim .bash_profile
[hadoop@server1 ~]$ cat .bash_profile
10 PATH=$PATH:$HOME/bin:~/java/bin
[hadoop@server1 ~]$ source .bash_profile
配置成功可以调用java
[hadoop@server1 ~]$ java
[hadoop@server1 ~]$ javac
[hadoop@server1 ~]$ jps
6596 Jps
[hadoop@server1 ~]$ ls
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
[hadoop@server1 ~]$ cd hadoop-2.7.3
[hadoop@server1 hadoop-2.7.3]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
[hadoop@server1 hadoop-2.7.3]$ mkdir input
[hadoop@server1 hadoop-2.7.3]$ cp etc/hadoop/*.xml input/
[hadoop@server1 hadoop-2.7.3]$ ls input/
capacity-scheduler.xml hdfs-site.xml kms-site.xml
core-site.xml httpfs-site.xml yarn-site.xml
hadoop-policy.xml kms-acls.xml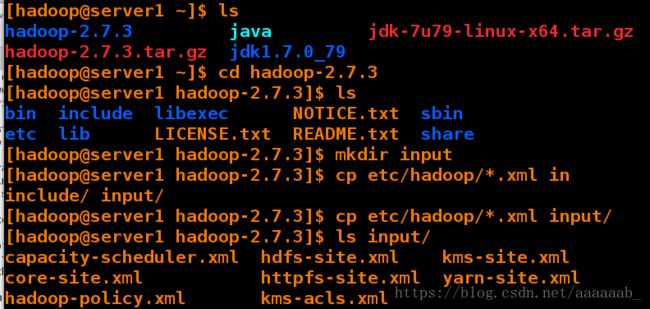
[hadoop@server1 hadoop-2.7.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+' 调用jar包
[hadoop@server1 hadoop-2.7.3]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat part-r-00000
1 dfsadmin
[hadoop@server1 output]$ cd
[hadoop@server1 ~]$ ls
hadoop-2.7.3 hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s hadoop-2.7.3 hadoop 制作软链接
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ ls
指定集群master端:
[hadoop@server1 hadoop]$ vim core-site.xml
[hadoop@server1 hadoop]$ cat core-site.xml | tail -n 7
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://172.25.38.1:9000value>
property>
configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ cat hdfs-site.xml | tail -n 6
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
[hadoop@server1 hadoop]$ cat slaves
localhost
[hadoop@server1 hadoop]$ vim slaves 单机版节点搭建所以server1主从都是写入自己的IP
[hadoop@server1 hadoop]$ cat slaves
172.25.38.1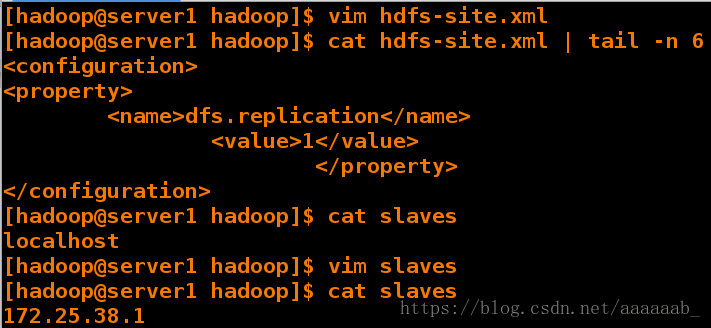
搭建集群节点的免密连接:
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ cd
[hadoop@server1 ~]$ cd .ssh/
[hadoop@server1 .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@server1 .ssh]$ cp id_rsa.pub authorized_keys
免密连接:
[hadoop@server1 .ssh]$ ssh 172.25.38.1
[hadoop@server1 ~]$ exit
logout
Connection to server1 closed.
[hadoop@server1 .ssh]$ ssh server1
[hadoop@server1 ~]$ exit
logout
Connection to server1 closed.
[hadoop@server1 .ssh]$ ssh localhost
[hadoop@server1 ~]$ exit
logout
Connection to localhost closed.
[hadoop@server1 .ssh]$ ssh 0.0.0.0
[hadoop@server1 ~]$ exit
logout
Connection to 0.0.0.0 closed.
[hadoop@server1 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt output sbin
etc input libexec NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ bin/hdfs namenode -format 初始化
启动datanode:
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
[hadoop@server1 hadoop]$ jps 使用显示java进程的工具进行查看进程
7256 SecondaryNameNode
7083 DataNode 启动
6990 NameNode
7375 Jps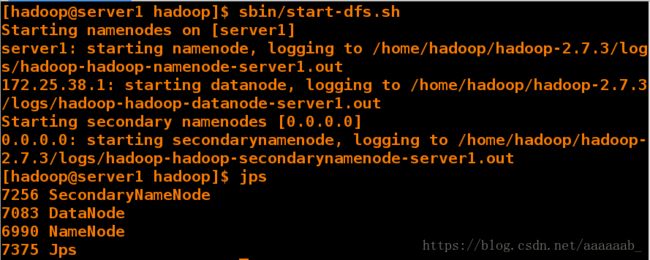
在网页可以访问:
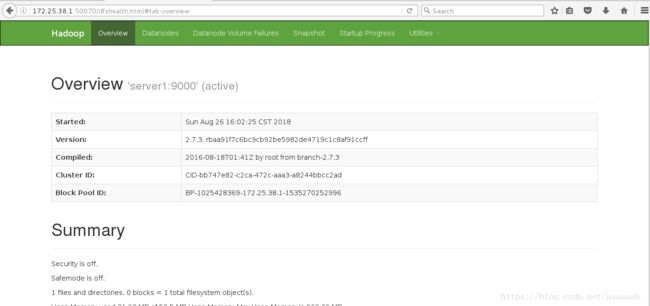
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input/
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-08-26 16:10 input
提交上去在网页查看input信息:

[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ jps
7889 Jps
7256 SecondaryNameNode
7083 DataNode
6990 NameNode
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh 停止hdfs服务
Stopping namenodes on [server1]
server1: stopping namenode
172.25.38.1: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
[hadoop@server1 hadoop]$ jps
8221 Jps
[hadoop@server1 hadoop]$ exit
exit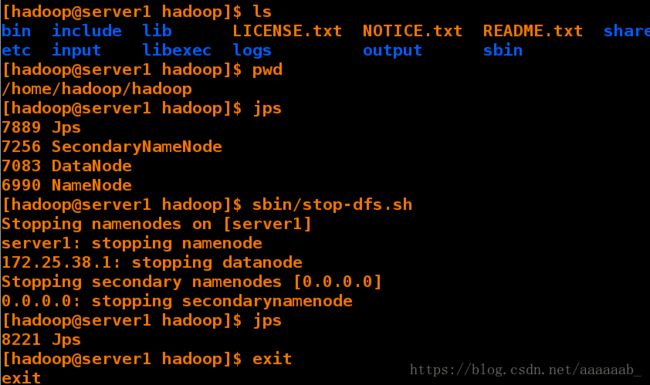
配置nfs文件系统搭建集群节点:
[root@server1 ~]# vim /etc/exports
[root@server1 ~]# cat /etc/exports
/home/hadoop *(rw,anonuid=800,anongid=800)
[root@server1 ~]# yum install nfs-utils -y
[root@server1 ~]# /etc/init.d/rpcbind start 依次启动不然nfs启动会报错
Starting rpcbind: [ OK ]
[root@server1 ~]# /etc/init.d/nfs start
Starting NFS services: [ OK ]
Starting NFS quotas: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
[root@server1 ~]# showmount -e 刷新
Export list for server1:
/home/hadoop *
挨个配置从节点:
[root@server2 ~]# ls
[root@server2 ~]# yum install -y nfs-utils 安装nfs
[root@server2 ~]# /etc/init.d/rpcbind start 依次启动服务
[root@server2 ~]# /etc/init.d/rpcbind status
rpcbind (pid 1457) is running...
[root@server2 ~]# useradd -u 800 hadoop 建立用户
[root@server2 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server2 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 直接挂载
[root@server2 ~]# ll -d /home/hadoop/
drwx------ 6 hadoop hadoop 4096 Aug 26 15:28 /home/hadoop/
[root@server2 ~]# su - hadoop
[hadoop@server2 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 可以看到数据表示主从节点信息同步
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server2 ~]$ jps
1560 Jps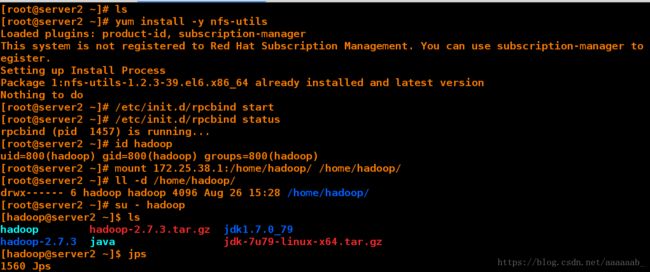
[root@server3 ~]# yum install nfs-utils -y
[root@server3 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server3 ~]# useradd -u 800 hadoop
[root@server3 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server3 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ls 主从节点同步
hadoop hadoop-2.7.3 hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
由于是挂载的方式所以可以免密连接:
[root@server1 ~]# ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ ssh 172.25.38.2
[hadoop@server2 ~]$ exit
logout
Connection to 172.25.38.2 closed.
[hadoop@server1 ~]$ ssh 172.25.38.3
[hadoop@server3 ~]$ exit
logout
Connection to 172.25.38.3 closed.
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ ls
[hadoop@server1 hadoop]$ vim hdfs-site.xml 将集群节点数改为2
[hadoop@server1 hadoop]$ vim slaves
[hadoop@server1 hadoop]$ cat slaves 添加从节点IP
172.25.38.2
172.25.38.3
[hadoop@server1 tmp]$ cd /tmp/
[hadoop@server1 tmp]$ ls
hsperfdata_logstash jna--1985354563 testfile yum.log
[hadoop@server1 tmp]$ cd
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ bin/hdfs namenode -format 初始化
主机打开namenode节点:
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
[hadoop@server1 hadoop]$ jps
9010 Jps
8901 SecondaryNameNode
8713 NameNode从节点可以看到datanode信息:
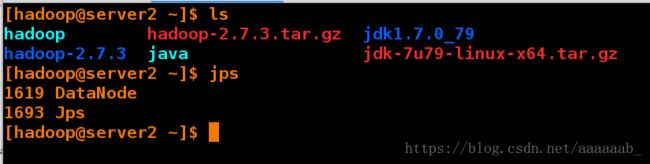
在主节点提交信息:
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output 调用jar包
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls output 查看输出
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2018-08-26 17:02 output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 9984 2018-08-26 17:02 output/part-r-00000
[hadoop@server1 hadoop]$ rm -fr output/在网页可以看到output信息:

[hadoop@server1 hadoop]$ bin/hdfs dfs -ls output
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2018-08-26 17:02 output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 9984 2018-08-26 17:02 output/part-r-00000
[hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/*
[hadoop@server1 hadoop]$
[hadoop@server1 hadoop]$ bin/hdfs dfs -get output 直接将输出导入到output里面
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat part-r-00000 查看信息一致
数据节点的添加和删除:
首先在网页查看节点信息有两个节点活着:
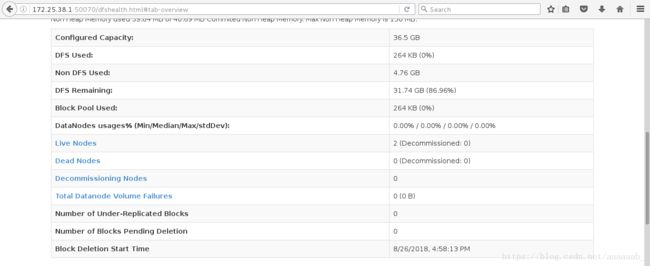
搭建server4进行节点的添加删除演示:
[root@server4 ~]# yum install -y nfs-utils 安装nfs服务
[root@server4 ~]# /etc/init.d/rpcbind start 开启服务
[root@server4 ~]# /etc/init.d/rpcbind status
rpcbind (pid 958) is running...
[root@server4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1041644 17120708 6% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
[root@server4 ~]# useradd -u 800 hadoop 建立用户
[root@server4 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server4 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 挂载
[root@server4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1041676 17120676 6% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 2982656 15179648 17% /home/hadoop
[root@server4 ~]# su - hadoop
[hadoop@server4 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server4 ~]$ cd hadoop/etc/hadoop/
[hadoop@server4 hadoop]$ vim slaves 添加server4节点信息
[hadoop@server4 hadoop]$ cat slaves
172.25.38.2
172.25.38.3
172.25.38.4
[hadoop@server4 hadoop]$ cd ..
[hadoop@server4 etc]$ cd ..
[hadoop@server4 hadoop]$ sbin/hadoop-daemon.sh start datanode 开启datanode节点服务
starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server4.out
[hadoop@server4 hadoop]$ jps 查看进程
1293 DataNode
1365 Jps
再次查看节点信息已经变为三个结点:


[hadoop@server1 output]$ cd ..
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=300 截取产生信息
300+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 6.70648 s, 46.9 MB/s
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -put bigfile 提交信息在网页查看可以看到bigfile的信息:

删除server3节点:
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim slaves
[hadoop@server1 hadoop]$ cat slaves 将server3节点删除
172.25.38.2
172.25.38.4
[hadoop@server1 hadoop]$ vim hosts-exclude 排除server3节点
[hadoop@server1 hadoop]$ cat hosts-exclude
172.25.38.3
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ cat hdfs-site.xml | tail -n 14
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.hosts.excludename>
<value>/home/hadoop/hadoop/etc/hadoop/hosts-excludevalue>
property>
configuration>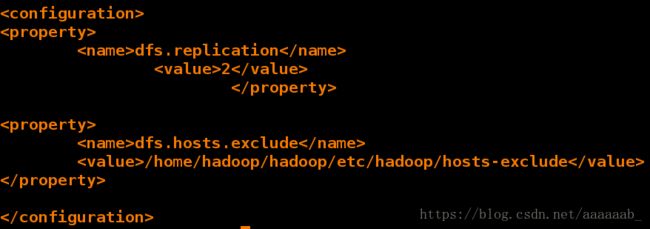
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ cd ..
[hadoop@server1 etc]$ cd ..
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -refreshNodes 刷新节点
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report 查看集群状态
Name: 172.25.38.3:50010 (server3)
Hostname: server3
Decommission Status : Decommission in progress
Configured Capacity: 19593555968 (18.25 GB)
DFS Used: 46637056 (44.48 MB)
Non DFS Used: 2524741632 (2.35 GB)
DFS Remaining: 17022177280 (15.85 GB)
DFS Used%: 0.24%
DFS Remaining%: 86.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Aug 26 18:13:36 CST 2018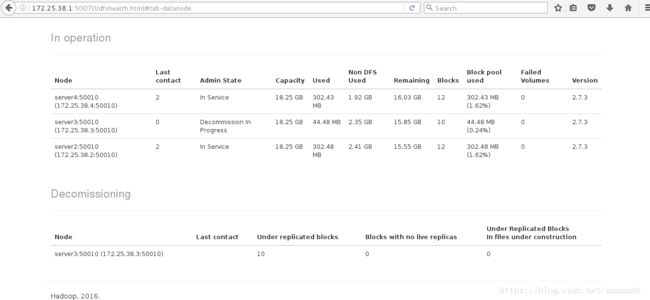
等待一会儿可以看到移动完成:

[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report 再次查看集群节点信息