caffe-SSD修改.sh文件,训练自己的数据集
本文介绍目标检测中数据集的准备、转换以及使用ssd进行训练的整个过程。内容包括:
1,数据集的准备
1)图片的标注
2)制作VOC数据集
3)将VOC数据集转换成lmdb格式
2,如何使用ssd进行训练
3,使用ssd做测试
需要的环境:
win7,编译好的caffe ,python27, python PIL(Pillow)模块。
注意:在caffe编译中,工程convert_annoset、convert_imageset和ssd_detect都要进行编译,在后面的脚本中要用到.
1.1,图片的标注:
图片的标注使用BBox-Label-Tool工具,该工具使用python实现,支持多标签的标注。
下载地址:http://download.csdn.net/download/u010725283/10216939
使用方法:
(1) 在BBox-Label-Tool/Images目录下创建保存图片的目录, 目录以数字命名(BBox-Label-Tool/Images/1)
,
然后将待标注的图片copy到1这个目录下;
(2) 在BBox-Label-Tool目录下执行命令 python main.py
(3) 在工具界面上, Image Dir 框中输入需要标记的目录名(比如 1), 然后点击load按钮, 工具自动将Images/1目录下的图片加载进来;
需要说明一下, 如果目录中的图片已经标注过,点击load时不会被重新加载进来.
(4) 该工具支持多类别标注, 画bounding boxs框标定之前,需要先选定类别,然后再画框.
(5) 一张图片标注完后, 点击Next>>按钮, 标注下一张图片, 图片label成功后,会在BBox-Label-Tool/Labels对应的目录下生成与图片文件名对应的label文件.
1.2,制作VOC数据集
caffe训练使用LMDB格式的数据,ssd框架中提供了voc数据格式转换成LMDB格式的脚本。所以实践中先将BBox-Label-Tool标注的数据转换成voc数据格式,然后再转换成LMDB格式。
VOC数据格式:
(1)Annotations中保存的是xml格式的label信息
如下:
(2)ImageSet目录下的Main目录里存放的是用于表示 训练的图片集和测试的图片集,如下:

(3)JPEGImages目录下存放所有图片集。
(4)label目录下保存的是BBox-Label-Tool工具标注好的bounding box坐标文件,该目录下的文件就是待转换的label标签文件。
(5)将Label转换成VOC数据格式
BBox-Label-Tool工具标注好的bounding box坐标文件转换成VOC数据格式的形式.
具体的转换过程包括了两个步骤:
1:将BBox-Label-Tool下的txt格式保存的bounding box信息转换成VOC数据格式下以xml方式表示;
2:生成用于训练的数据集和用于测试的数据集。
用python实现了上述两个步骤的换转。
createXml.py 完成txt到xml的转换; 执行脚本./createXml.py
1.3,VOC数据转换成LMDB数据
SSD提供了VOC数据到LMDB数据的转换脚本 data/VOC0712/create_list.sh 和 /data/VOC0712/create_data.sh,这两个脚本是完全针对VOC0712目录下的数据进行的转换。在windows下使用create_data.bat和get_image_size.bat文件用于数据格式的转换。
具体的步骤如下:
(1) 在%CAFFE_ROOT%/data/VOCdevkit目录下创建VAP目录,该目录中存放自己转换完成的VOC数据集;
(2) %CAFFE_ROOT%/examples目录下创建VOC目录;
(3) %CAFFE_ROOT%/data目录下创建VAP目录,同时将data/VOC0712下的create_data.bat create_list.sh, labelmap_voc.prototxt这三个文件copy到%CAFFE_ROOT%/data/VAP目录下
(4)对上面两个.bat和create_list.sh文件进行修改,修改的主要内容主要是一些路径信息:
create_list.sh文件修改如下:
#!/bin/bash
root_dir=F:/caffe/caffe-ssd-microsoft/data/VOCdevkit
sub_dir=ImageSets/Main
bash_dir=” (cd" ( c d " (dirname “${BASH_SOURCE[0]}”)” && pwd)”
echo $HOME
for dataset in trainval test
do
dst_file= bashdir/ b a s h d i r / dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in
VAP
do
if [[ dataset == "test" && dataset == "test" && name == “VOC2012” ]]
then
continue
fi
echo “Create list for name n a m e dataset…”
dataset_file= rootdir/ r o o t d i r / name/ subdir/ s u b d i r / dataset.txt
img_file= bashdir/ b a s h d i r / dataset”_img.txt”
cp datasetfile d a t a s e t f i l e img_file
sed -i “s/^/ name\/JPEGImages\//g" n a m e \/ J P E G I m a g e s \/ / g " img_file
sed -i “s/ /.bmp/g" / . b m p / g " img_file
label_file= bashdir/ b a s h d i r / dataset”_label.txt”
cp datasetfile d a t a s e t f i l e label_file
sed -i “s/^/ name\/Annotations\//g" n a m e \/ A n n o t a t i o n s \/ / g " label_file
sed -i “s/ /.xml/g" / . x m l / g " label_file
paste -d’ ’ imgfile i m g f i l e label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == “test” ]
then
F:/caffe/caffe-ssd-microsoft/Build/x64/Release/get_image_size
rootdir r o o t d i r dst_file bashdir/ b a s h d i r / dataset”_name_size.txt”
fi
# Shuffle trainval file.
if [ $dataset == “trainval” ]
then
rand_file=$dst_file.random
cat dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > rand_file
mv randfile r a n d f i l e dst_file
fi
done
create_data.bat文件修改如下:
@Echo off
Echo caffe create_annoset Batch
set root_dir=
F:\caffe\caffe-ssd-microsoft
cd %root_dir%
set redo=1
set test_train_dir=
data\VAP
set data_root_dir
=data\VOCdevkit
set mapfile=
F:\caffe\caffe-ssd-microsoft\data\VAP\labelmap_voc.prototxt
set anno_type=detection
set db=lmdb
set min_dim=0
set max_dim=0
set width=0
set height=0
set “extra_cmd=–encode-type=jpg –encoded”
if %redo%==1 (
set “extra_cmd=%extra_cmd% –redo”
)
for %%s in (trainval test) do (
echo Creating %%s lmdb…
python2 %root_dir%\scripts\create_annoset.py ^
–anno-type=%anno_type% ^
–label-map-file=%mapfile% ^
–min-dim=%min_dim% ^
–max-dim=%max_dim% ^
–resize-width=%width% ^
–resize-height=%height% ^
–check-label %extra_cmd% ^
%data_root_dir% ^
%test_train_dir%\%%s.txt ^
%test_train_dir%\%%s_%db%
)
pause
注意:以上文件的修改,都是对路径的修改,相对简单。
完成上面步骤的修改后,可以开始LMDB数据数据的制作,在%CAFFE_ROOT%目录下分别运行:
1) ./data/indoor/create_list.sh
注意:
在windows下运行.sh文件可以选择cygwin工具.
这一步生成了两个文件,test.txt 和trainval.txt
2)create_data.bat
命令执行完毕后,可以在%CAFFE_ROOT%/data/VAP目录下查看转换完成的LMDB数据数据。如下:

2使用caffe-ssd进行训练
网络的训练需要相关的prototxt和预训练好的caffemodel
1)复制%cafferoot%\examples\ssd目录下的ssd_pascal.py为ssd_pascal_VAP.py,修改如下几点:



修改好后,运行脚本可得到solver.prototxt,test.prototxt,trainval.prototxt和deploy.prototxt四个文件。
- 准备好VGG_VOC0712_SSD_300x300_iter_20000.caffemodel(在文档所在目录可以找到)
- 将solver.prototxt,test.prototxt,trainval.prototxt,deploy.prototxt和VGG_VOC0712_SSD_300x300_iter_20000.caffemodel放到目录:%cafferoot%\models\VGGNet\VOC0712\SSD_300x300
4)在caffe根目录新建train_ssd_my.bat
内容如下:
.\Build\x64\Release\caffe.exe train –solver=models/VGGNet/VOC0712/SSD_300x300/solver.prototxt –weights=models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_20000.caffemodel
Pause
双击运行即开始ssd的训练过程。
3.使用ssd进行测试。
测试需要的文件包括deploy.prototxt,VGG_scenetext_SSD_300x300_iter_60000.caffemodel
测试需要的图片路径;
在caffe根目录下新建ssd_detect.bat,内容如下:
F:\caffe\caffe-ssd-microsoft\Build\x64\Release\ssd_detect.exe -confidence_threshold=0.5 F:\caffe\caffe-ssd-microsoft\examples\ssd\models\VGGNet\VOC0712\SSD_300x300\deploy.prototxt F:\caffe\caffe-ssd-microsoft\models\VGGNet\VOC0712\SSD_300\VGG_scenetext_SSD_300x300_iter_60000.caffemodel F:\caffe\caffe-ssd-microsoft\data\demo\test.txt
pause
另,可参见另外一篇文章:http://www.xue63.com/toutiaojy/20171230G0BQC800.html ,注意:具体路径需要设置成自己的。
问题总结:(所有问题都是没有使用正确的test.ptototxt和train.prototxt文件,以及caffemodel模型)
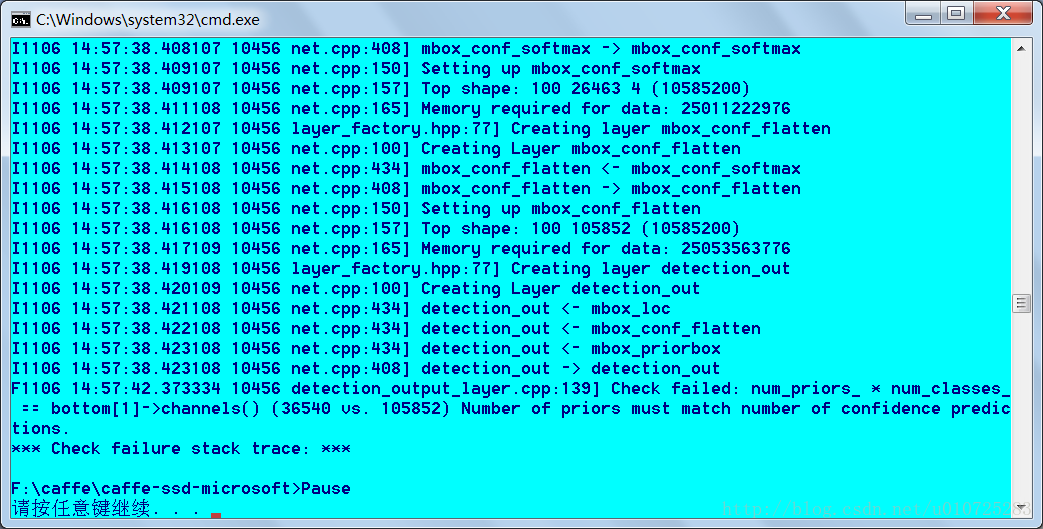
1,报错Check failed: num_priors_ * num_classes_ == bottom[1]->channels() (36540
vs.
105852
) .
问题理解,出现这种问题的原因一般通过修改test.prototxt中的num_classes即可,计算出对应的num_classes。num_classes一般是要分类的数量+1,+1是背景类。注意:将train.prototxt和test.prototxt中的num_classes全部都修改。也可以修改ssd_pascal.py中的num_classes来生成对应的trian和test文件。
1
,报错Check failed: label < num_classes (5 vs. 5)
打开train_tv_logo.prototxt搜索num_classes改为9(8classes+1)
2
,报错Check failed: num_priors_ * num_classes_ == bottom[1]->channels() (62136 vs. 34520) .
理解:在multibox_loss_layer里,有Number of priors must match number of confidence predictions这一句话,查到 http://blog.csdn.net/u012235274/article/details/52212077
里面:
预测loction bottom[0] dimension is [N*C*1*1],confidence bottom[1] dimension is [N*C*1*1]
//priors bottom[2] dimension is [N*1*2*W], gound truth bottom[3] dimension is [N*1*H*8]
修改:train_tv_logo.prototxt1148行num_output=36和另外三个,36=4*9,4是一个cell里面的priorbox数目,9是8class+背景class
3
,报错:Cannot copy param 0 weights from layer
‘
fire8_norm_mbox_conf
’
; shape mismatch. Source param shape is 20 512 3 3 (92160); target param shape is 36 512 3 3 (165888). To learn this layer
’
s parameters from scratch rather than copying from a saved net, rename the layer.
在train.sh里最后一行去掉-weights $WEIGHT
4,
正常训练,loss一直保持在6.9左右不下降
初始化有问题
5
,test-train时候警告:Missing true_pos for label:
6,
改变flip=true后:Check failed: num_priors_ * loc_classes_ * 4 == bottom[0]->channels() (41424 vs. 27616) Number of priors must match number of location predictions
需要把4个mbox_loc层的numoutput从16改成24(4*4->6*4)(test和train都要改)
7
,Check failed: num_priors_ * num_classes_ == bottom[1]->channels() (51780 vs. 34520) Number of priors must match number of confidence predictions.
需要把4个mbox_conf层的numoutput从20改成30(4*5->6*5)(test和train都要改)
8
,Check failed: 0 == bottom[0]->count() % explicit_count (0 vs. 2) bottom count (80430) must be divisible by the product of the specified dimensions (4)
test
里面reshape里面的4改成5(test要改,train没有)
9,
checked failed
: num_test_image_ <= names_.size() (4952 vs. 117)
原因及解决方法:ssd_pascal.py文件中num_test_image参数没有修改,将其修改为实际的117,同时还要修改的参数为num_classes