栈回溯技术及uClibc的堆实现原理
【摘要】
本文描述栈的作用、uClibc上堆的实现,利用栈回溯技术查找编程中经常发生的段错误问题,理解栈、堆的作用,通过几个例子分析越界访问导致的错误。
【关键词】
堆 栈 回溯 堆实现 栈作用
一、问题的提出
段错误、非法地址访问等问题导致程序崩溃的现象屡屡发生,如果能找到发生错误的函数,往往一眼就能看出BUG所在——对于这类比较简单的问题,比如使用空指针进行读写等,利用栈回溯技术可以很快定位。但是对于数组溢出、内存泄漏等问题导致的程序错误,往往隐藏很深,它们并不当场发作,即使我们一步一步跟踪到发生错误的语句时,也经常会让人觉得“这个地方根本不可能出错啊”——错误在很早以前就隐藏下来了,只不过是这个“不可能出错的语句”触发了它。了解栈的作用、堆的实现,可以让我们脑中对程序的运行、函数的调用、变量的操作有个感官的了解,对解决这类问题会有所帮助。
二、解决思路
了解了栈,就可以通过栈回溯技术分析程序的调用关系,从而得出程序出错的流程;了解了堆,就可以对各类动态分配、释放内存导致的错误有个指导思想。
(1)、栈的作用
一个程序包含代码段、数据段、BSS段、堆、栈;其中数据段用来中存储初始值不为0的全局数据,BSS段用来存储初始值为0的全局数据,堆用于动态内存分配,栈用于实现函数调用、存储局部变量。比如对于如下程序:
程序1 section.c
#include
#include
#include
int *g_pBuf;
int g_iCount= 10;
int main(intargc, char **argv)
{
char str[2];
g_pBuf = malloc(g_iCount);
printf("Address of main = 0x%08x\n", (unsigned int)main);
printf("Address of g_pBuf = 0x%08x\n", (unsignedint)&g_pBuf);
printf("Address of g_iCount = 0x%08x\n", (unsigned int)&g_iCount);
printf("Address of malloc buf = 0x%08x\n", (unsigned int)g_pBuf);
printf("Address of local buf str = 0x%08x\n", (unsigned int)str);
return 0;
} 使用如下命令编译得到可执行文件section,反汇编文件section.dis:
mips-uclibc-gcc -o section section.c –static
mips-uclibc-objdump -D section > section.dis
在T500上的linux环境下,这个程序的输出结果为:
Address of main =0x004000b0
Address of g_pBuf =0x100002d0
Address of g_iCount =0x10000000
Address of malloc buf =0x10002660
Address of local buf = 0x7fff7e50
00008d0c
0008acc0
00089078
其中main函数的地址为0x004000b0,它处于代码段中;全局变量g_pBuf位于BSS段;全局变量g_iCount位于数据段;使用malloc分配出来的内存地址为0x10002660,它位于堆中;局部变量str数组的开始地址为0x7fff7e50,位于栈中。它们的分布图示如下:
图1 程序各段示意图
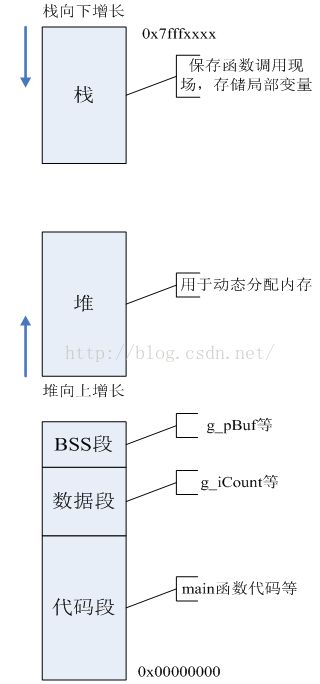
栈的作用有二:
① 保存调用者的环境——某些寄存器的值、返回地址
② 存储局部变量
现在通过一个简单的例子来说明栈的作用:
程序2 stack.c
#include
#include
#include
void A(inta);
void B(intb);
void C(intc);
void A(int a)
{
printf("%d: A call B\n", a);
B(2);
}
void B(int b)
{
printf("%d: B call C\n", b);
C(3);
}
void C(int c)
{
char *p = (char*)c;
*p = ‘A’;
printf("%d: function C\n", c);
}
int main(intargc, char **argv)
{
char a;
A(1);
C(&a);
return 0;
} 使用如下命令编译得到可执行文件stack,反汇编文件stack.dis:
mips-uclibc-gcc -o stack stack.c –static
mips-uclibc-objdump -D stack > stack .dis
此程序的调用关系为main > A > B > C,现在来看看栈如何变化:
注意:
1. 图中“SP (32) = RA_after_xxx”表示SP+32的地方存放函数xxx执行完后的返回地址
2. 栈中不仅仅存储返回地址,其它内容没标出来
图2 函数调用中栈的变化
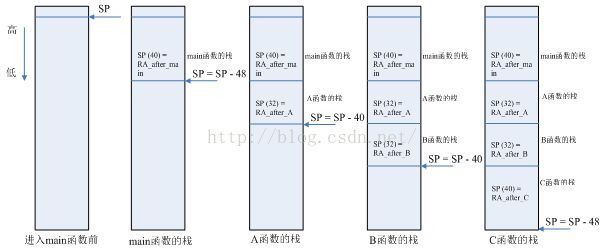
上图中,main、A、B、C四个函数的栈大小都是40字节,返回地址都存在栈偏移地址为32的地方。我们是如何知道这点的呢?需要阅读反汇编代码:
……
004000b0 :
4000b0: 3c1c0fc1 lui gp,0xfc1
4000b4: 279c8090 addiu gp,gp,-32624
4000b8: 0399e021 addu gp,gp,t9
4000bc: 27bdffd8 addiu sp,sp,-40
4000c0: afbc0010 sw gp,16(sp)
4000c4: afbf0020 sw ra,32(sp)
……
00400128 :
400128: 3c1c0fc1 lui gp,0xfc1
40012c: 279c8018 addiu gp,gp,-32744
400130: 0399e021 addu gp,gp,t9
400134: 27bdffd8 addiu sp,sp,-40
400138: afbc0010 sw gp,16(sp)
40013c: afbf0020 sw ra,32(sp)
……
004001a0
4001a0: 3c1c0fc0 lui gp,0xfc0 // gp全局指针,用来访问全局变量、函数
4001a4: 279c7fa0 addiu gp,gp,32672
4001a8: 0399e021 addu gp,gp,t9
4001ac: 27bdffd0 addiu sp,sp,-48 //栈指针减48,这48字节的空间就是函数C的栈
4001b0: afbc0010 sw gp,16(sp) // 在栈中保存gp
4001b4: afbf0028 sw ra,40(sp) //在栈中保存返回地址ra
4001b8: afbe0024 sw s8,36(sp) // 在栈中保存s8,此寄存器用来保存堆栈指针sp
4001bc: afbc0020 sw gp,32(sp) // 又保存一次gp,冗余
4001c0: 03a0f021 move s8,sp // s8=sp,可见s8会被修改,所以先在上面保存原值
4001c4: afc40030 sw a0,48(s8) // a0用于传递参数,对应C语言,就是参数int c
//把它保存在上一个函数的栈中
4001c8: 8fc20030 lw v0,48(s8) // v0=a0= int c
4001cc: 00000000 nop
4001d0: afc20018 sw v0,24(s8) // 局部变量p
4001d4: 8fc20018 lw v0,24(s8) //
4001d8: 24030041 li v1,65 // v1 = 65 = ‘A’
4001dc: a0430000 sb v1,0(v0) // 相当于*p = ‘A’
4001e0: 8f848018 lw a0,-32744(gp) // 下面3条指令得到
4001e4: 00000000 nop //printf的第一个参数“%d:function C\n”
4001e8: 24843230 addiu a0,a0,12848
4001ec: 8fc50030 lw a1,48(s8) // printf的第二个参数,显然就是int c
4001f0: 8f998110 lw t9,-32496(gp)
4001f4: 00000000 nop
4001f8: 0320f809 jalr t9 //t9为printf的地址,跳转执行
4001fc: 00000000 nop
400200: 8fdc0010 lw gp,16(s8) // 恢复gp
400204: 03c0e821 move sp,s8
400208: 8fbf0028 lw ra,40(sp) // 从栈中得到保存的返回地址
40020c: 8fbe0024 lw s8,36(sp) // 从栈中得到保存的s8
400210: 03e00008 jr ra // 跳转,返回(对于mips跳转指令,执行下一条指令后,才跳转)
400214: 27bd0030 addiu sp,sp,48 // sp加上48,恢复栈指针
……
00400218
400218: 3c1c0fc0 lui gp,0xfc0
40021c: 279c7f28 addiu gp,gp,32552
400220: 0399e021 addu gp,gp,t9
400224: 27bdffd0 addiu sp,sp,-48
400228: afbc0010 sw gp,16(sp)
40022c: afbf0028 sw ra,40(sp)
……
00008444 :
8444: e92d4800 push {fp, lr}
8448: e28db004 add fp, sp, #4
844c: e24dd008 sub sp, sp, #8
8450: e50b0008 str r0, [fp, #-8]
8454: e59f0014 ldr r0, [pc, #20] ; 8470
8458: e51b1008 ldr r1, [fp, #-8]
845c: ebffff9f bl 82e0 <_init+0x20>
8460: e3a00002 mov r0, #2
8464: eb000002 bl 8474
8468: e24bd004 sub sp, fp, #4
846c: e8bd8800 pop {fp, pc}
8470: 0000858c andeq r8, r0, ip, lsl #11
00008474 :
8474: e92d4800 push {fp, lr}
8478: e28db004 add fp, sp, #4
847c: e24dd008 sub sp, sp, #8
8480: e50b0008 str r0, [fp, #-8]
8484: e59f0014 ldr r0, [pc, #20] ; 84a0
8488: e51b1008 ldr r1, [fp, #-8]
848c: ebffff93 bl 82e0 <_init+0x20>
8490: e3a00003 mov r0, #3
8494: eb000002 bl 84a4
8498: e24bd004 sub sp, fp, #4
849c: e8bd8800 pop {fp, pc}
84a0: 0000859c muleq r0, ip, r5
000084a4 :
84a4: e92d4800 push {fp, lr}
84a8: e28db004 add fp, sp, #4
84ac: e24dd010 sub sp, sp, #16
84b0: e50b0010 str r0, [fp, #-16]
84b4: e51b3010 ldr r3, [fp, #-16]
84b8: e50b3008 str r3, [fp, #-8]
84bc: e51b3008 ldr r3, [fp, #-8]
84c0: e3a02041 mov r2, #65 ; 0x41
84c4: e5c32000 strb r2, [r3]
84c8: e59f000c ldr r0, [pc, #12] ; 84dc
84cc: e51b1010 ldr r1, [fp, #-16]
84d0: ebffff82 bl 82e0 <_init+0x20>
84d4: e24bd004 sub sp, fp, #4
84d8: e8bd8800 pop {fp, pc}
84dc: 000085ac andeq r8, r0, ip, lsr #11
000084e0 :
84e0: e92d4800 push {fp, lr}
84e4: e28db004 add fp, sp, #4
84e8: e24dd010 sub sp, sp, #16
84ec: e50b0010 str r0, [fp, #-16]
84f0: e50b1014 str r1, [fp, #-20]
84f4: e3a00001 mov r0, #1
84f8: ebffffd1 bl 8444
84fc: e24b3005 sub r3, fp, #5
8500: e1a00003 mov r0, r3
8504: ebffffe6 bl 84a4
8508: e3a03000 mov r3, #0
850c: e1a00003 mov r0, r3
8510: e24bd004 sub sp, fp, #4
8514: e8bd8800 pop {fp, pc}
上面红色的指令“addiu sp,sp,-40”表示将SP寄存器的值减去40,也就意味着栈向下移动40字节。指令“sw ra,32(sp)”表示将返回地址ra存放在地址(SP+32)的地方。
局部变量也是存储在栈中,当一个函数的局部变量越多,它的栈越大。
上面把函数C的反汇编代码全部罗列出来了,现在以函数C为例说明调用一个函数时,如何在栈中保存现场、如何存储局部变量;参数如何传递、函数退出时如何恢复调用者现场,然后返回。根据代码注释和图3很容易理解:
图3 函数进入、返回的栈变化

栈中保存着函数的返回地址、局部变量等,那么我们可以从这些返回地址来确定函数的调用关系、调用顺序。这就是下节介绍的栈回溯。
(2)、栈回溯
上面程序2的第23、24两行必然导致段错误而使得程序崩溃,linux内核当发现发生段错误时,会打印出栈信息。我们可以使用栈回溯的方法找到发生错误的原因。
运行结果stack程序,结果如下(注意:如果你是通过telnet来运行程序,可以使用dmesg命令看到这些栈信息):
/# ./stack
1:A call B
2:B call C
do_page_fault()#2: sending SIGSEGV to heap for illegal write access to
00000003(epc == 004001dc, ra == 00400188)
$0: 00000000 10006c0000000003 00000041 00000003 0000000c0000000c 00000000
$8: 00006c00 00000002 00000000 42203a32 19999999 0000000000000057 00000115
$16:00000000 7fff7eb4 7fff7ebc 00000001 10005dc4 00000001 10005dbc 10005d94
$24:00000001 004001a0 10008140 7fff7db8 7fff7db8 00400188
Hi: 00000002
Lo: 00000000
epc : 004001dc Not tainted
Status:00006c13
Cause: 3080000c
Processheap (pid: 70, stackpage=87876000)
Stack:
7fff7ebc 00000001 10008140 0040050c 10008140 0000000000000003 00000000
10008140 7fff7de8 00400188 00400170 0000000300000002 0000000c00000000
10008140 65642f00 10008140 7fff7e10 00400110 004000f8 00000002 00000001
7fff7ebc 00000005 10008140 00000000 100081407fff7e38 00400258 7fff7eb4
00000001 10008140 00400368 00000000 1000814000000000 00000000 00000000
10008140 7fff7c68 0040046c004003dc 00000001 7fff7eb4 00000000 00000000
10008140 00000000 10005dbc 10005da4 0000000010005dc4 10008140 004002dc
00000000 00000000 00000000 00000000 0000000000000000 00000001 7fff7f56
00000000 7fff7f60 7fff7f6a 7fff7f71 7fff7f7c 7fff7fde 7fff7fec 00000000
00000010 00000000 00000006 00001000 0000001100000064 00000003 00400034
00000004 00000020 00000005 00000003 0000000700000000 00000008 00000000
00000009 00400290 0000000b 00000000 0000000c 00000000 0000000d 00000000
0000000e 00000000 00000000 00000000 0000000000000000 00000000 6d2f0000
682f746e00706165 52455355 6f6f723d 4f480074 2f3d454d52455400 74763d4d
00323031 48544150 73752f3d 69622f72622f3a6e 2f3a6e69 2f727375 6e696273
62732f3a 2f3a6e69 2f746e6d 3a6e6962746e6d2f 6962732f 6d2f3a6e752f746e
732f72733a6e6962 7273752f 636f6c2f 732f6c613a6e6962 746e6d2f 7273752f
6e69622f 4853003a3d4c4c45 6e69622f0068732f 3d445750 6d2f002f682f746e
00706165 00000000
CallTrace:
Code:afc20018 8fc20018 24030041
Segmentationfault
上面的蓝色部分“epc ==004001dc, ra == 00400188”表示导致崩溃的指令的地址为0x004001dc,返回地址为0x00400188。不过返回地址我们不关注,因为在堆栈信息中也可以找到。根据崩溃指令的地址值,可以判断这条指令是在用户程序、内核还是可加载模块中:
1. 用户程序地址空间: 0x00000000~0x7FFFFFFF;
2. 内核地址空间: System.map文件中的_stext ~_etext,大概是0x80000000~0x80300000;
3. 可加载模块地址空间:0xC0000000~0xC0800000
由此可判断,发生崩溃的指令属于用户程序。
必须结合此程序的反汇编程序进行回溯:
将epc(0x004001dc)所在函数的部分反汇编代码摘录如下,以便分析:
004001a0
4001a0: 3c1c0fc0 lui gp,0xfc0
4001a4: 279c7fa0 addiu gp,gp,32672
4001a8: 0399e021 addu gp,gp,t9
4001ac: 27bdffd0 addiu sp,sp,-48
4001b0: afbc0010 sw gp,16(sp)
4001b4: afbf0028 sw ra,40(sp)
4001b8: afbe0024 sw s8,36(sp)
4001bc: afbc0020 sw gp,32(sp)
4001c0: 03a0f021 move s8,sp
4001c4: afc40030 sw a0,48(s8)
4001c8: 8fc20030 lw v0,48(s8)
4001cc: 00000000 nop
4001d0: afc20018 sw v0,24(s8)
4001d4: 8fc20018 lw v0,24(s8)
4001d8: 24030041 li v1,65
4001dc: a0430000 sb v1,0(v0) /*导致崩溃的指令 */
4001e0: 8f848018 lw a0,-32744(gp)
4001e4: 00000000 nop
4001e8: 24843230 addiu a0,a0,12848
。。。。。。
需要明确一点,上面栈信息中“Stack:”字样开始的内容,即是函数C及它的更高几级调用函数的栈内容。
下面对涉及的每个函数进行分析:
1. 函数C的栈:从函数C开头的指令“addiu sp,sp,-48”知道函数C的栈大小为48字节。即从“Stack:”字样开始的48字节:
7fff7ebc00000001 10008140 0040050c10008140 00000000 00000003 00000000
100081407fff7de8 00400188 00400170
返回地址
函数C在开始时,会将用到的静态寄存器、返回地址等,保存在堆栈中。我们关心的是返回地址。可以看到ra的保存指令“4001b4: afbf0028 sw ra,40(sp)”,表示返回地址保存在堆栈的偏移地址40处,数值为0x00400188。根据这个地址值,在stack.dis中可以再次找到这个地址处于函数B的范围内。
2. 函数B的栈:
摘录函数B开头几条指令如下:
00400128:
400128: 3c1c0fc1 lui gp,0xfc1
40012c: 279c8018 addiu gp,gp,-32744
400130: 0399e021 addu gp,gp,t9
400134: 27bdffd8 addiu sp,sp,-40
400138: afbc0010 sw gp,16(sp)
40013c: afbf0020 sw ra,32(sp)
400140: afbe001c sw s8,28(sp)
。。。。。。
由“400134: 27bdffd8 addiu sp,sp,-40”、“40013c: afbf0020 sw ra,32(sp)”可知函数B的栈大小为40字节,函数B执行完后的返回地址存储在其栈偏移地址32处。函数B栈的的数据紧挨着函数C的栈,取出罗列如下:
00000003 00000002 0000000c 00000000
10008140 65642f00 10008140 7fff7e10 00400110 004000f8
返回地址
从上面信息可以知道,函数B的返回地址为0x00400110,从stack.dis可知处于函数A的地址范围内。
3. 函数A的栈:
摘录函数A开头几条指令如下:
004000b0:
4000b0: 3c1c0fc1 lui gp,0xfc1
4000b4: 279c8090 addiu gp,gp,-32624
4000b8: 0399e021 addu gp,gp,t9
4000bc: 27bdffd8 addiu sp,sp,-40
4000c0: afbc0010 sw gp,16(sp)
4000c4: afbf0020 sw ra,32(sp)
4000c8: afbe001c sw s8,28(sp)
4000cc: afbc0018 sw gp,24(sp)
。。。。。。
由“4000bc: 27bdffd8 addiu sp,sp,-40”、“4000c4: afbf0020 sw ra,32(sp)”可知函数A的栈大小为40字节,函数A执行完后的返回地址存储在其栈偏移地址32处。函数A栈的的数据紧挨着函数B的栈,取出罗列如下:
00000002 00000001
7fff7ebc 00000005 10008140 00000000 100081407fff7e38 00400258 7fff7eb4
返回地址
从上面信息可以知道,函数A的返回地址为0x00400258,从stack.dis可知处于函数main的地址范围内。
至此,可以知道main调用A、A调用B、B再调用C时,在函数C中导致程序崩溃。现在认真看一下函数C:
21 void C(int c)
22 {
23 char *p = (char*)c;
24 *p = ‘A’;
25 printf("%d: function C\n", c);
26 }
这个函数太过简单,可以一眼就知道第23、24行代码有问题。但是如果函数C有上千行代码呢?除了睁大眼睛检查C代码外,我们还可以根据它的反汇编码来差错——内核打印出来的栈信息的前面还有些有用的信息:
do_page_fault()#2: sending SIGSEGV to heap for illegal write access to
00000003(epc == 004001dc, ra == 00400188)
$0 : 00000000 10006c0000000003 00000041 00000003 0000000c0000000c 00000000
$8 : 00006c0000000002 00000000 42203a3219999999 00000000 00000057 00000115
$16: 00000000 7fff7eb4 7fff7ebc 00000001 10005dc4 0000000110005dbc 10005d94
$24: 00000001 004001a0 10008140 7fff7db8 7fff7db8 00400188
Hi: 00000002
Lo: 00000000
epc : 004001dc Not tainted
Status:00006c13
Cause: 3080000c
Processheap (pid: 70, stackpage=87876000)
粉红色部分是程序崩溃时编号为0~31的所有寄存器的值,根据mips寄存器的使用约定,这些寄存器的编号、名字、功能如下表所示:
| 寄存器编号 |
助记符 |
用法 |
| 0 |
zero |
返回值永远为0 |
| 1 |
at |
用做汇编器的暂时变量 |
| 2-3 |
v0, v1 |
子函数调用返回结果 |
| 4-7 |
a0-a3 |
子函数调用的参数 |
| 8-15 24-25 |
t0-t7 t8-t9 |
暂时变量,子函数使用时不需要保存与恢复 |
| 16-23 |
s0-s7 |
子函数寄存器变量。子函数必须保存和恢复使用过的变量在函数返回之前,从而调用函数知道这些寄存器的值没有变化。 |
| 26-27 |
k0,k1 |
通常被中断或异常处理程序使用作为保存一些系统参数 |
| 28 |
gp |
全局指针。一些运行系统维护这个指针来更方便的存取“static“和”extern" 变量。 |
| 29 |
sp |
堆栈指针 |
| 30 |
s8/fp |
第9个寄存器变量。子函数可以用来做桢指针 |
| 31 |
ra |
子函数的返回地 |
表1 mips寄存器使用规则
现在回过头来看看函数C的反汇编码,从中找出出错的原因:
004001a0
4001a0: 3c1c0fc0 lui gp,0xfc0
4001a4: 279c7fa0 addiu gp,gp,32672
4001a8: 0399e021 addu gp,gp,t9
4001ac: 27bdffd0 addiu sp,sp,-48
4001b0: afbc0010 sw gp,16(sp)
4001b4: afbf0028 sw ra,40(sp)
4001b8: afbe0024 sw s8,36(sp)
4001bc: afbc0020 sw gp,32(sp)
4001c0: 03a0f021 move s8,sp
4001c4: afc40030 sw a0,48(s8) //a0为函数C的参数
4001c8: 8fc20030 lw v0,48(s8) //现在v0=参数
4001cc: 00000000 nop
4001d0: afc20018 sw v0,24(s8)
4001d4: 8fc20018 lw v0,24(s8)
4001d8: 24030041 li v1,65 // v1=65=’A’
4001dc: a0430000 sb v1,0(v0) //相当于*p=’A’
4001e0: 8f848018 lw a0,-32744(gp)
。。。。。。
出错的指令为“4001dc: a0430000 sb v1,0(v0)”,它将寄存器v1的值存到地址(v0+0)中,只存储1个字节。从上表可知:v1为3号寄存器,v0为2号寄存器,根据内核打印出来的寄存器值可知v1=0x00000041,v0=0x00000003,写地址为0x03,当然出错——这不是可写的地址。
阅读汇编代码是件困难的事情,没有其他办法时再用这方法吧。
(3)、uClibc的堆实现原理
当使用malloc、calloc等动态分配内存函数时,就要接触到堆——heap。了解了uClibc中堆的管理、实现机制,在解决由于数组越界、内存泄漏等导致的奇怪问题时可以增加一个思路。
一个程序需要更多的内存时,它可以向操作系统申请,linux系统以4KB的整数倍(第一次可能例外)向用户程序提供内存,用户程序将这部分内存称为“堆”,随着申请内存的增多,堆越来越大——如图1所示。uClibc封装了向系统申请内存、管理得到的内存等操作,向用户提供malloc、calloc、free、realloc等函数。
uClibc堆管理的本质在于:
1. 使用malloc()或者calloc()可以动态分配一段内存,并向用户返回一个内存地址,而实际上这个地址前面有8个字节的内部结构,用来记录分配的块长度以及一些标志。
2. 使用free或者realloc释放内存时,根据参数所示的地址得到前面8字节的内部结构,就可以知道不再使用的这段内存的大小。
这个结构的完整部分如下:
struct malloc_chunk {
size_t prev_size; /* Size of previous chunk (if free). */
size_t size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links – used only if free. */
struct malloc_chunk* bk;
};
prev_size是上一个块的大小,只在上一个块空闲的情况下才被填充。
size是当前块的大小,它包括prev_size和size成员的大小(8字节) ,它的最低位表示上一个块是否空闲:1——正在使用,0——空闲。
fd是双向链表的向前指针,指向下一个块。这个成员只在空闲块中使用。
bk是双向链表的向后指针,指向上一个块。这个成员只在空闲块中使用。
对于已分配的内存,除了分配用户指定大小的内存空间外,还在前面增加了malloc_chunk结构的前两个成员(8字节).。
下面以图来说明堆分配的过程:
图4 堆分配简图
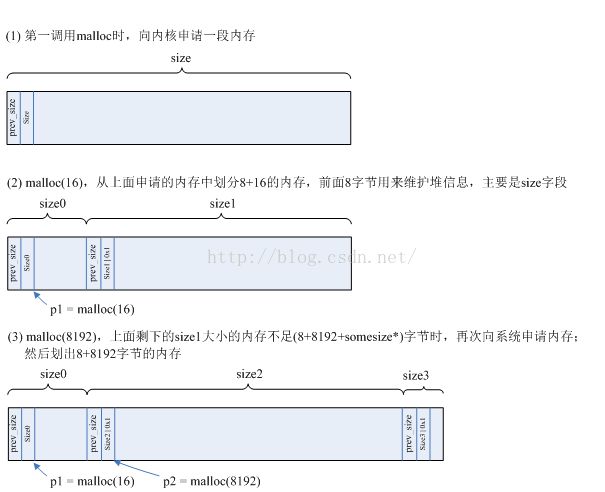
注意:
1. 上面的somesize是struct malloc_chunk的大小,即16字节,这是为了编程方便要求的——这不影响我们了解堆管理的本质
2. 图中的“size| 0x1”的最低位为1,表示前面一块内存已经分配出去,正在使用
free操作就是根据所传递的地址得到它前面8字节的内部结构,从而知道这块不再使用的内存的大小,最后将它放入空闲队列中。
为了提高性能、减少碎片等,堆的实现比较复杂——使用了大量的链表将不同大小范围的块链接在不同的队列,但是这些都没有背离上面说的本质,仅仅是一些技巧性的操作。下面用一个图来表示多次malloc、free后,uClibc中堆的管理结构,具体实现不再细说。注意一点,uClibc中仅仅维持着空闲的块,对于已经分配(malloc)出去的内存,仅当释放(free)后,才会链入某个队列中:
图5 某时刻堆中各空闲块在链表中的分布
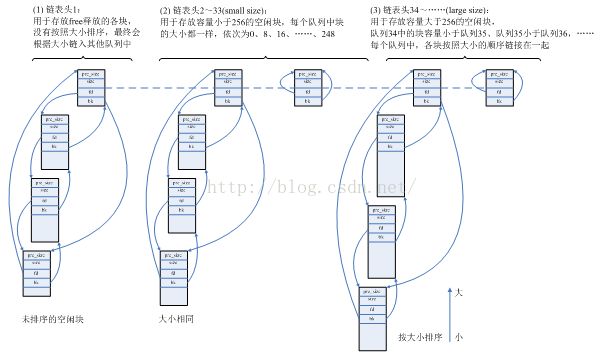
(4)、内存越界、内存泄漏
了解了栈的作用、堆的实现后,现在来看看两种情况的内存越界:
a) 局部变量数组越界
程序3 strcpy.c
01 #include
02 #include
03 #include
04
05 int main(intargc, char **argv)
06 {
07 char str[2];
08 if (argc < 2)
09 {
10 printf("Usage: %s
11 }
12 else
13 {
14 strcpy(str, argv[1]);
15 printf("Input string: %s\n",str);
16 }
17 return 0;
18 }
使用如下命令编译得到可执行文件strcpy,反汇编文件strcpy.dis:
mips-uclibc-gcc -o strcpy strcpy.c –static
mips-uclibc-objdump -D strcpy > strcpy.dis
当执行./ strcpy abcdefghijklmno时一切正常,
但是当字符串增加1位时./ strcpy abcdefghijklmnop,程序崩溃。
通过反汇编代码我们可以知道此程序中main函数的栈使用情况:
图6 strcpy.c中main函数的栈

执行“./strcpy abcdefghijklmno”时,“abcdefghijklmno”为15个字符,加上字符串结束符为16字节,将会把上图中从str[0]到s8的区域完全覆盖掉,但是返回地址ra仍保存完好。
执行“./ strcpy abcdefghijklmnop”时,增加了一个字符,将会破坏栈中保存的ra ,这导致main函数执行完后返回到错误的地址。
总之:局部变量越界将破坏栈,栈中保存的是上一个函数的执行现场、和当前函数的局部变量,所以造成的影响有可能在当前函数中体现,也可能在当前函数执行完后体现。
b) malloc的内存越界:
使用malloc得到的内存出现越界时,导致的错误更加隐蔽,例子如下:
程序4 heap_crack.c
01 #include
02 #include
03 #include
04
05 int main(intargc, char **argv)
06
07 char*p1 = NULL;
08 char*p2 = NULL;
09 int size;
10
11 p1 = malloc(16);
12
13 printf("p1[-4] = 0x%x, %d\n",*((unsigned int *)&p1[-4]), *((unsigned int *)&p1[-4]));
14 printf("p1[16] = 0x%x, %d\n",*((unsigned int *)&p1[16]), *((unsigned int *)&p1[16]));
15 printf("p1[20] = 0x%x, %d\n",*((unsigned int *)&p1[20]), *((unsigned int *)&p1[20]));
16
17 memset(p1, 0xff,24);
18
19 if (argc >= 2)
20 {
21 size = strtoul(argv[1], 0, 0);
22 }
23
24 if (!size)
25 {
26 size = 1024;
27 }
28
29 printf("malloc second buffer, size =%d\n", size);
30
31 p2 =malloc(size);
32
33 return 0;
34 }
使用如下命令编译得到可执行文件strcpy,反汇编文件strcpy.dis:
mips-uclibc-gcc -o heap_crack heap_crack.c –static
mips-uclibc-objdump -D heap_crack > heap_crack.dis
执行./ heap_crack 1024不会出错,得到如下结果:
p1[-4] = 0x19, 25
p1[16] = 0x0, 0
p1[20] = 0x19b1, 6577
malloc second buffer, size = 1024
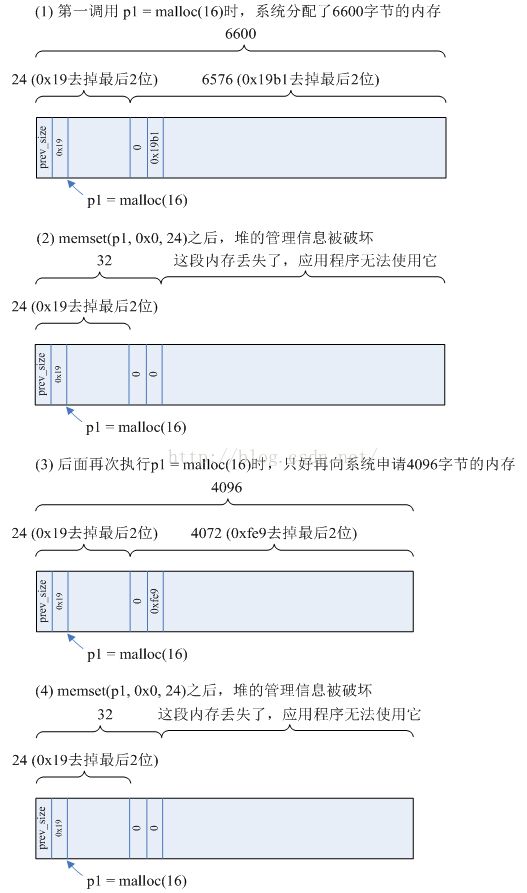
将第二次malloc的数值增大,比如./heap 7000,则程序崩溃,如果此时使用栈回溯方法分析,会发现崩溃的地方发生在malloc函数中——也许你会大喊“malloc怎么会出错?”,其实导致错误的原因在前面第17行“memset(p1, 0xff,24)”,它越界访问将堆的管理信息破坏了。过程如下图所示:
图7 heap_crack的堆
注意:上面的0x19、0x19b1的最后1位用于表示“前面的一块正在使用”;图中的“size”没有考虑字节的对齐,malloc内部会将size作一些对齐处理。
c) 内存泄漏:
内存泄漏经常发生的原因是当malloc得到的内存不再使用后,忘记使用free将它释放掉。但是内存越界也可能导致内存泄漏。
请看例子:
程序5 mem_leak.c
01 #include
02 #include
03 #include
04
05 int main(intargc, char **argv)
06 {
07 char *p1 = NULL;
08 int i;
09
10 for (i = 0; i < 10000; i++)
11 {
12 p1 = malloc(16);
13 memset(p1,0x0, 24);
14 }
15
16 while(1);
17
18 return 0;
19 }
使用如下命令编译得到可执行文件mem_leak,反汇编文件mem_leak.dis:
mips-uclibc-gcc -o mem_leak mem_leak.c –static
mips-uclibc-objdump -D mem_leak > mem_leak.dis
这个程序连续申请10000次16字节的内存,10000*16=160000,约为156K。如果我们的系统内存为128M,那么可以同时执行800多个这个程序。但是由于第13行的内存越界,使得每执行这个程序需要约40M的内存,在我们的系统中同时运行3个这个程序时导致系统崩溃。
memset(p1, 0x0, 24)会将堆中下一个块的大小改为0,使得再次malloc时无法从这个块中划分内存,只好向系统申请——申请的大小为4KB的整数倍(第一次除外)。这样,每次malloc(16),其实都是申请4KB的内存,内存很快就会耗尽。
具体过程如下图所示:
图8 堆越界导致的内存泄漏
三、实践情况
上层程序人员掌握栈回溯技术后,可以自行根据linux系统答应出来的栈找到程序崩溃原因,极大地提高了查找bug的效率;了解堆的实现原理后,对一部分不可思议的问题有了新思路。
四、效果评价
以前发生段错误、动态分配内存时导致程序崩溃等问题时,经常需要驱动人员分析堆栈协助调试,工作量极大并且效率低下。通过本文的学习,可以让程序员掌握一种新的调试手段,提高变成水平。
五、推广建议
本文适用于在linux系统上开发的程序,栈的分析方法基于misp架构的CPU,堆的原理是基于uClibc库。对于其他体系结构的CPU,此文也有借鉴作用。学习本文时,需要对汇编有一点了解,最好由底层开发人员对应用开发人员进行培训。
参考资料
1. 《see mipsrun book》,Dominic Sweetman
2. 《LINUX内核源代码情景分析》6.4节 信号,作者:毛德操,胡希明
3. uClibc0.9.26源代码
4. 《一种新的Heap区溢出技术分析》,作者:warning3