MySQL慢查询平台架构方案
MySQL慢查询平台架构方案
方案1
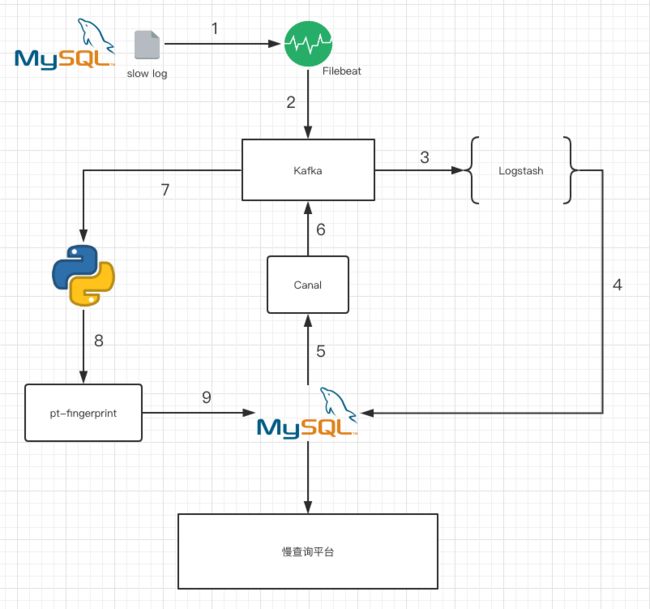
Filebeat读取slow log 到kafka , logstash从kafka消费后解析成出各个列, 然后写入MySQL, 但是这样的问题是查询语句是这样的
select * from A where id=1. 而我们需要去除谓词的SQL, 也就是select * from A where id=? 这样的, 这样才好对SQL进行聚合分析
于是用Canal拉binlog, 再写到kafka, 然后python消费, 获取id, sql文本, 使用pt-fingerprint去除谓词后再更新回去.
这个架构看起来蛮高大上 想了想还是复杂了些, 环节太多, 容易出问题.
- 优点: 慢查询准实时获取(但可能是伪需求)
- 缺点: 架构复制易出错, MySQL版本升级如果slow log格式发生变化, 维护logstash的grok会很麻烦
有人说为什么不用Filebeat ingest直接到ES, 这要图标用Kibana就好了. 我的考虑是:
1.还要做谓词去除
2.这样做出的图没法和我们业务的服务数关联, 业务人员查询就必须知道数据库的IP端口
详细方案可以参考下面的文档
https://www.jianshu.com/p/f3be9cce9b77
https://www.jianshu.com/p/3cf0e2a8d23d
方案2
[外链图片转存失败(img-qBV3kUb5-1563600598908)(https://raw.githubusercontent.com/Fanduzi/Fandb.github.io/master/images/mysql_slow_2.png)]
这个方案关键点在于将log_output参数设置为'FILE,TABLE', 那么MySQL会在mysql.slow_log表中记录慢查询信息
[外链图片转存失败(img-rh633z9k-1563600598909)(https://raw.githubusercontent.com/Fanduzi/Fandb.github.io/master/images/mysql_slow_3.png)]
而这不是正是方案1中我们费了半天劲用logstash想要达到的结果吗? 而mysql.slow_log又恰好是一个csv引擎的表
[外链图片转存失败(img-J3FwTc1t-1563600598931)(https://raw.githubusercontent.com/Fanduzi/Fandb.github.io/master/images/mysql_slow_4.png)]
根据官方文档描述, csv这个格式可以读,甚至可以写. 那它其实就是个文本啊, 我们用Filebeat读它呗.
这个架构构思巧妙, 我都佩服我自己了, 但是为啥业界没人用呢?
- 优点: 架构简单易实现, 日志实时获取
- 缺点: 需要测试,为啥没人用?可能有坑
方案3
老路子
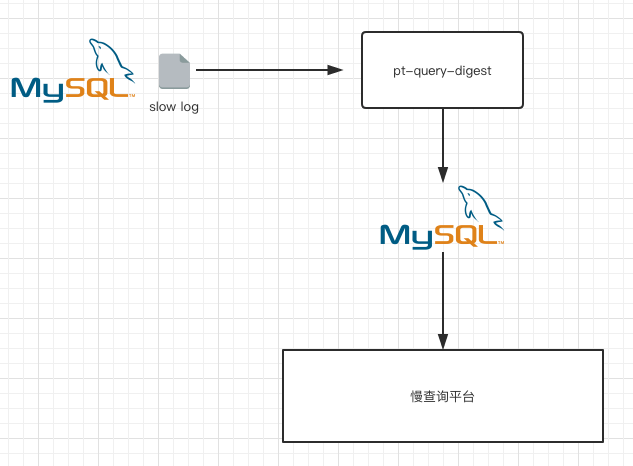
很简单的架构, 对技术水平要求很低, 初级DBA就可以实现的方案
原理是在每个MySQL服务器部署定时任务, 执行pt-query-digest
/bin/pt-query-digest --user=slow_query_w --password=$FUCK --review h=192.168.2.142,D=db_slow_query,t=t_${ha_group_name}_query_review --history h=192.168.2.142,D=db_slow_query,t=t_${ha_group_name}_query_review_history --no-report --limit=0% --filter=" \$event->{Bytes} = length(\$event->{arg}) and \$event->{hostname}=\"$HOSTNAME\"" $slow_log-`date +%Y%m%d`
pt-query-digest 会分析slow log, 将结果插入数据库
[外链图片转存失败(img-AcLevNYT-1563600598933)(https://raw.githubusercontent.com/Fanduzi/Fandb.github.io/master/images/mysql_slow_6.png)]
这个结果就是就包含了去除谓词的SQL
这个方案其实是比较老也比较简单经典的方案, Anemometer, Query-Digest-UI都是这么做的.
最开始讨论方案时, 其实我个人是由于不想重复老路子才没选这个方案
- 优点: 架构简单易于实现与维护
- 缺点: 实时性较差, 逼格低