正则表达式简单学习记录
为什么写本文?
为什么想起来要记录一下正则表达式(regular expression)呢? 这是因为随着玩linux时间的增加,越能体会到它的重要性,因为正则表达式是UNIX/LINUX工具使用和构建模型上的基础。花一些时间学习如何使用它们并且好好利用它们,你会不断地从各个层面得到充分的回报。举例来说,sed和awk俗称SHELL脚本中的瑞士军刀,而要充分发挥sed和awk的强大功能,你不可能不利用正则表达式,单纯这点玩linux的人就应该花些时间好好学习了解一下!例外,学习过编译原理的童鞋在词法分析那里也应该听说过正则表达式。
需要提醒新手的是,正则表达式和shell的通配符扩展完全是两码事,不可搞混淆了。关于bash的通配符,可以参阅这篇文章《bash之通配符》。
什么是正则表达式?
命令行处理纯文本时最常用到的两个基本操作包括:文本查找(text searching)-- 查找含有特定文本的行。伴随文本查找之后的往往是文本替换(text substitution) -- 更换查找到的文本。
OK,正则表达式就是为了这两个操作而生的 -- 所谓正则表达式就是一种特殊的表示方式,让你可以查找特定准则的文本。也就是说有了正则表达式之后,我们再也不用使用简单的固定字符串来进行文本查找了。
其实在中文语境里,「正则」这两个字有些令人让人发怵,总感觉晦涩难懂。其中在英文中,它就是regular expression,而regular有「规律的,规范的,定期的,合格的」意思,因此正则表达式也可以翻译成「有规律,有规范的表达式」。
正则表达式的组成元素
本质上,正则表达式由两个基本元素组成:分别为一般字符(ordinary characters)和特殊字符(special characters)。
所谓一般字符很好理解,就是它们没有任何特殊含义,代表的仅仅是自身,一般新手不用学习都会使用。
但是正则表达式强大就强大在它的特殊字符上,特殊字符不再代表它们自身,更多的用来代表可选(alternatives)、重复(repetitions)等含义,这就使得我们可以组合使用这些特殊字符来查找符合我们要求的文本。
在正则表达式中,习惯上把特殊字符称作元字符(metacharacters)。很明显,学习正则表达式,重点学习的就是这些元字符。
POSIX标准将正则表达式分为两类:基本正则表达式(BRE,Basic Regular Expression)和扩展正则表达式(ERE,Extended Regular Expression)。
你肯定会问,它们有什么区别吗? 其实区分它们很容易,那就是它们彼此之间在元字符上有些差异。
其实除了基本正则表达式和扩展正则表达式,还有一个叫PCRE(Perl Compatible Regular Expressions)的分支,它是Perl语言中的正则表达式,相对于BRE和ERE,它提供更多的元字符。关于正则表达式的历史可以参考文章《Regular Expressions – a brief history》。
我们这里只关注POSIX标准。
以下罗列出常用的元字符,可以仔细对比下BRE和ERE的细微差别。(具体可参考Wikipedia 链接)

再来一张两者的对比图如下:
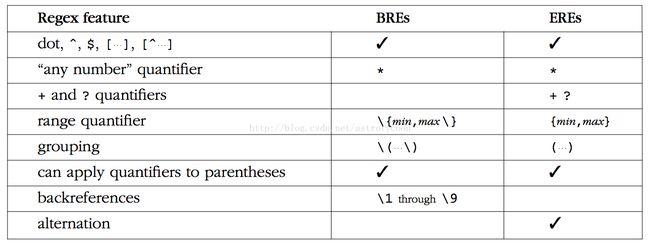
两者的不同总结如下:
(1)BRE不支持+,?和|。
(2)ERE不支持\1、\2 ... \9这样的后向引用。
那么是否意味着我们无法使用这些功能了呢?答案是否定的。这是因为我们现在使用的软件大都是GNU的工具,而GNU对这些功能都有所扩展,使得我们同样可以使用这些功能!这样我们在BRE中可以通过\+,\?和\|来使用ERE中的+,?和|。ERE中同样可以使用反向引用。可以具体参考各个工具的在线文档,很具有阅读价值(grep,sed,gawk)。
如何学习正则表达式?
不管学习什么,都要遵循先简单后复杂的过程,学习正则表达式也不例外。
根据我自身的学习经验,学习正则表达式的第一步是掌握如何匹配单个字符,接着是掌握如何匹配字符串,最后才是更复杂的功能。
伴随着这三个过程,我认为学习过程中,重点掌握放方括号表达式[],区间表达式{},以及分组()尤为关键,掌握了这三个括号,其他的都是一些特殊的元字符而已。
(1)匹配单个字符(matching single characters)
匹配单个字符的方法一共有4种:
① 一般字符(ordinary character)
一般字符代表的就是它们自身,这是最直接且易于理解的。
② 转义后的元字符(escaped metacharacter)
转义后的元字符代表的就是它们自身符号。因此\*匹配于字面上的*,\\匹配于字面上的反斜杠,还有\[匹配于左方括号。
③ .(点号)元字符
.(点号)意即“任一字符”。因此,a.c匹配于abc、aac以及aqc等。.*代表“匹配任一字符的任意长度”。
④ 方括号表达式[ ] (bracket expression)
方括号表达式,匹配方括号内的任一字符。对于方括号表达式需要重点掌握,以下是关于它的几点说明:
1)一个方括号表达式一次只能匹配单个字符,也就是说[abc]可以匹配于a,或者b,或者c中的一个,而不能一次匹配abc。
2)方括号内只有一个字符时,可以不用方括号,也就是说[a]和a是等价的,都代表完全匹配于a。
3)方括号内可以使用连字符“-”代表一定范围的符号,不过这个可能因为locale的不同而表现出不同的行为,因此不具最佳可移植性。可以通过设置LC_ALL为C来得到传统的字符排序。
4)字符“^”置于方括号里第一个字符则代表反向的含义。因此[^aeiou]指的就是小写元音字符以外的任何单个字符,例如:大写元音字母、所有辅音字母、数字、标点符号等。此外[^a]和^a的意思是完全不同的:[^a]指的是除字符a之外的所有单个字符,而^a指的是以字符a打头的任何字符串。
(2)单个表达式匹配多字符(matching multiple characters with one expression)
了解了如何匹配单个字符,那么匹配多个字符最简单的方法就是把它们一一罗列出来。所以正则表达式ab匹配于ab,而..(两个点号)匹配于任意两个字符。
不过,将这些字符全列出来只有在简短的正则表达式里才好用。如果需要匹配更复杂的字符串,依然用一一罗列出来的办法的话,你是不是觉得很愚蠢呢? 毋庸置疑啊。因此正则表达式就提供了重复的功能,用来更好地匹配字符串。
匹配多字符的方法一般有如下6种:
① ?
问号?用于匹配前面正则表达式0次或者1次。
② *
星号*用于匹配前面正则表达式0次或者多次。
③ +
加号+用于匹配前面正则表示1次或者多次。
④ {n}
用于匹配前面正则表达式正好n次。多了会截断,剩余的重复被选中。
⑤ {n, }
用于匹配前面正则表达式至少n次。不会截断,直到出现前面正则表达式以外的字符。
⑥ {n, m}
用于匹配前面正则表达式至少n次,至多m次。例如a{1,3}匹配aaaaa,第一次匹配的是aaa,第二次匹配的是aa,而不是单个的字符a,意思就是说:按max优先原则。
如果仔细观察,我们可以发现①②③其实也可以用区间表达式来表示,如下:
[备选字符集]{0,1}=>[备选字符集]?[备选字符集]{0, }=>[备选字符集]*[备选字符集]{1, }=>[备选字符集]+
因此,牢记区间表达式至关重要!
其他
了解了如何匹配单个字符和匹配字符串后,其他的就很好学习了,现总结如下:
(1)锚点匹配(anchoring)
什么是锚点匹配呢?名字好奇怪!这是因为锚点匹配和上述的字符匹配(不管是单字符匹配还是字符串匹配)不同,它不会匹配任何字符,仅仅匹配的是一个位置。
常见的锚点匹配元字符就是“^”和“$”,分表“锚定”一行的开始和结束。
(2)交替(alternation)
在正则表达式中,交替运算符是管道字符|。为什么要有交替功能呢?
通过上面的学习,我们了解到方括号表达式是在一个字符集合(a set of specified characters)中一次匹配一个字符,但是如果我们想在一个字符串集合(a set of strings or other regular expressions)中一次匹配一个字符串呢? 这时候交替功能就能派上用途了。例如:
read|write用于匹配read或者write。
true|falset用于匹配true或者false。
甚至可以使用多个交替运算符red|blank|yellow|green
(3)分组() (grouping)
那么为什么要有分组功能呢?在我看来,主要有两点作用:
① 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。
② 分组之后,可以通过后向引用(back references)简化表达式。
这里我们通过ERE的两个列子来简单讲解一下。先来看第一个作用,对于IP地址的匹配,可以使用如下正则表达式:
[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
但是仔细观察,我们发现,可以把\.[0-9]{1,3}看成一组,然后重复3次,如下:
[0-9]{1,3}(\.[0-9]{1,3}){3}
这样一来,简洁多了!
接着看后向引用的使用,html源码中有
很容易发现,有两个title,因此可以使用后向引用改写如下:
<(title)>.*
这样是不是简洁多了呢?
注意,在这里有必要强调一下:后向引用,引用的仅仅是匹配后的文本内容,而不是正则表达式本身!
例如:刚才的匹配IP地址的正则可不可以改写成如下形式呢?
([0-9]{1,3})(\.\1){3}
答案是:不行!实际测试你会发现,这个改写后的正则匹配的是4个数相同的IP地址,例如123.123.123.123。这说明,第一组匹配成功后,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是正则表达式。
分组还可以结合交替功能使用。比如有一个应用场景,需要从某处获取IP地址,但是不知道是IPv4还是IPv6地址,那么就可以使用([IPv4的规则]|[IPv6的规则])来匹配,而不用写两个正则表达式。
总结:
好了,本文总结的内容并非正则的全部内容,还有很多很多细节,需要用到时,可以去查看手册,GNU官方的关于grep,sed,gawk的文档里都有对正则表达式的简单介绍,需要时可以参阅!
最后,给大家推荐两个学习正则的很好的网站(https://regexper.com 和 https://regexr.com),结合它可以很直观的学习正则。
参考链接:
《Regular Expression, IEEE Std 1003.1-2017, Open Group》
《代码之美,正则之道》
《阿里程序员带你全面深入了解正则表达式》
《正则表达式30分钟入门教程》
《正则表达式“派别”简述》
《Linux/Unix工具与正则表达式的POSIX规范》
《正则表达式》
《正则表达式中的断言(assertions)》
《关于正则表达式的零宽断言》
《正则表达式分组、断言详解》
《Regular Expressions Tutorial Table of Contents》
《Master Regular Expressions Part 1: Introduction, History, Engines, Notation And Modes》
《Regular Expressions — The Last Guide》
《Learn Regex the Easy Way》
《Learn regex the easy way》(github)