目标检测算法评估
本文是对论文《Object count/Area Graphs for the Evaluation of Object Detection and Segmentation Algorithms》的部分理解翻译,用于学习对文本检测算法的评估!!!
目标检测和分割算法的评估
1. 摘要
目标检测算法的评估是一项non-trivial的任务:检测结果通常通过比较被检测目标的预测边界框和标注边界框来评估检测的好坏。通常使用的精确率和召回率度量是依据这两个矩形的重叠区域计算出来的。但是,这些方法有几个缺点:它们没有提供关于检测目标的正确的proportion和错误的alarms数量的直观信息,并且它们不能在多个图像上累积。此外,定量和定性评估经常混杂在一起,导致度量方式模糊。
在本文中,我们提出了解决这些问题的新方法。检测算法的性能直观地由性能曲线图来说明,该曲线图根据对检测质量的约束来呈现object level的精确率和召回率。为了比较不同的检测算法,从图中计算代表单个性能值。 测试数据集对检测性能的影响通过性能/通用性图来说明。评估方法可以应用于不同类型的目标检测算法。 它已经过不同的文本检测算法的测试,其中包括ICDAR 2003文本检测竞赛的参与者。
2.基本公式
精确度和召回率的方法被广泛使用,因为它们直观地传达了预测结果的质量,公式如下:

为了对方法性能的排序有一个单独值,将这两个度量线性组合,即为引入精确度和召回率的调和平均值。它的优点是强调了两个性能值中的最小值,公式如下:
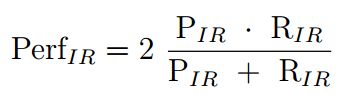
对于目标检测问题,召回率和精确率的测量不能被直接应用,因为一个目标是否被检测到并不是所谓的二分类问题。目标检测算法可以在不同的级别下进行评估。比如在像素级别的分类:
一旦获得了每个像素的分类决策结果,即我们知道每个像素是否属于该目标,此时就可以在像素级别上应用召回率和精确率的度量方式,公式如下:

或者,可以使用分类错误率来进行评估。
如果在像素级对目标检测性能进行评估,那么标注框必须非常精确,才能得到鲁棒性的度量结果。当然,这种情况很少发生,因为标注框主要是通过人类观察者进行标注的,人类虽然可以很容易地检测到一个物体,但很少能以像素的精度去定位目标。
3. 之前的工作
基于矩形标注的目标检测评估方案的目标是获取标注框的列表G和检测框的列表D,并测量两个列表之间的匹配质量,两个列表元素分别为Gi和Di。质量度量就是惩罚信息损失,即没有检测到目标或部分目标。
大多数算法是基于召回率和精确率测量的扩展,其在两个矩形Gi和Di的面积上以及在重叠区域的面积上计算:
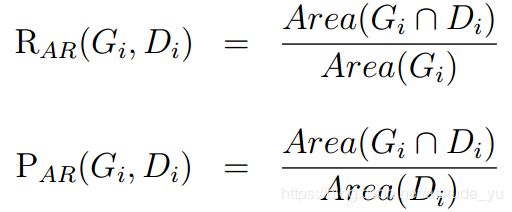
召回率说明已经正确检测到的标注框的比例;如果错误检测区域的面积增加,则精确率降低。我们分别称这些方法为“Area Recall”和“Area Precision”。
虽然计算这些图片的一对检测框和标注框很简单,但是对两个边界框列表的实际情况的扩展并不容易。现有的评估方法在处理两个边界框列表之间的对应关系有所不同,即它们是仅考虑单个匹配还是多个匹配,并且它们利用所有图片来生成一个最终的评价值。
一个简单的评估方案已经被应用在第七届国际文本分析和认证大会(ICDAR)2003文本定位竞赛中。计算公式如下:
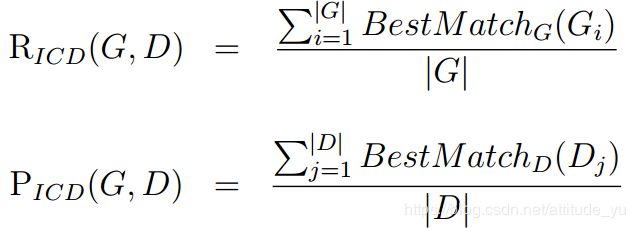
其中BestMatch(G)和BestMatch(D)是在其对应列表中最接近该矩形的匹配函数:
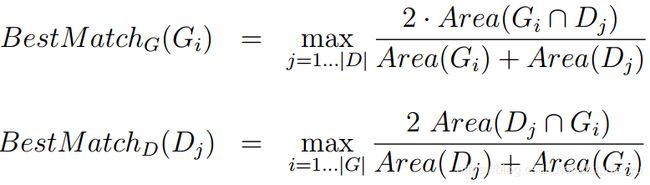
由匹配函数公式可知,如果矩形与对应列表中的另一个矩形完全匹配,则匹配函数的计算结果为1,否则它们的计算结果小于1。因此,式(1)给出的原始计算方法是式(6)给出的新方法的上限,如果相应矩形的重叠区域很小,则由式(6)给出的精确率和召回率就都很低。
以上的ICDAR评估方案的缺点是只考虑one-to-one匹配。然而,在实际中有时候一个标注框被预测“分裂”成多个检测框或者几个标注框被预测“合并”成单个检测框,如图所示:

Liang等人提出了一种文本结构提取算法用于评估。依据检测框和标注框的两个列表G和D,创建两个重叠矩阵σ和τ。建立两个矩阵,行表示Gi,列表示Dj,矩阵的值分别为Gi和Dj之间的area recall和area precision:
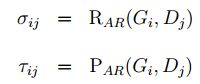
然后对两个矩阵中的值进行阈值化并将它们聚类为组,以此解决不同的匹配类型的问题。
4. 改进方案
只要只涉及两个矩形框:一个标注框和一个检测框,区域召回率和区域精度率就很容易理解。但是,对于多个图像或具有多个文本框的单个图像,这些组合度量的方案并不简单。这是以上所述现有评价方案的主要缺点:在计算评价过程时,将重叠信息的进行堆积计算使得结果较为模糊。例如,50%的召回可能意味着50%数量的标注框已经完全匹配,或者所有的标注框都已经找到,但每个标注框只有50%重叠,或者这两个极端之间的任何情况。因此,以上方法的召回和精确度量并不是很直观:无法确定检测到了多少文本矩形;检测质量不明显。
4.1 评估算法的要求内容
我们制定了一个解决这些问题的评估方案,它的设计以下列目标为指导:
1.该方法应该提供一个定量的评估:评估措施应该直观地判断有多少文本框被正确地检测到,多少错误的信息被检测到。
2.该方法应该提供一个定性的评估:给一个容易解释的检测质量结果。
3.它应该支持检测一对一匹配、一对多匹配、多对一匹配的情况。
4.评估方案必须可扩展到多个图像中且满足以上条件。
我们设计目标中最重要的约束条件是目标1和目标2。事实上,这两个目标是相关的:我们认为检测到的矩形数量取决于我们对单个矩形的质量结果要求。为此,我们提出一种将这两种度量相结合的自然方法:二维图,说明它们的相依性。更准确地说,在y轴上,绘制两种对我们最感兴趣的度量:目标计数。

4.2 匹配边界框
对于式(9)中给出的度量计算方式用于确定每个标注框Gi和每个检测框Di是否被正确检测到。为了考虑一对一匹配、一对多匹配和多对一匹配,引入Liang等人提的重叠矩阵σ和τ。
为了确定两个边界框列表之间的对应关系,对矩阵进行了分析。通常,索引为(i,j)的非零值元素表明标注框Gi与检测框Dj有重叠。然而,只有当重叠满足质量约束时,才能匹配这两个边界框,即area recall和area precision高于各自的约束,公式如下:
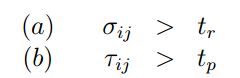
其中,tr属于[0,1],用于约束area recall;tp属于[0,1],用于约束area precision.