DBeaver 5.3.1安装和使用
目录
一、下载和安装
二、连接
1. mysql连接
2. hive连接
3. clickhouse连接
4. elasticsearch连接
5. neo4j连接
6. phoenix连接
6.1 hbase与phoenix整合
6.2 启动
6.3 测试
6.4 连接
DBeaver是基于jdbc驱动的数据管理工具,支持丰富的数据库,如mysql、hive、clickhouse、elasticsearch、neo4j、phoenix、mongodb、postgresql、oracle等。
一、下载和安装
gitub下载地址DBeaver,采用tar安装。
cd /opt/modules
tar -zxf /opt/softwares/apache-phoenix-4.14.1-HBase-1.4-bin.tar.gz -C . #解压
mv apache-phoenix-4.14.1-HBase-1.4-bin/ phoenix-4.14.1 #重命名
./dbeaver #启动二、连接
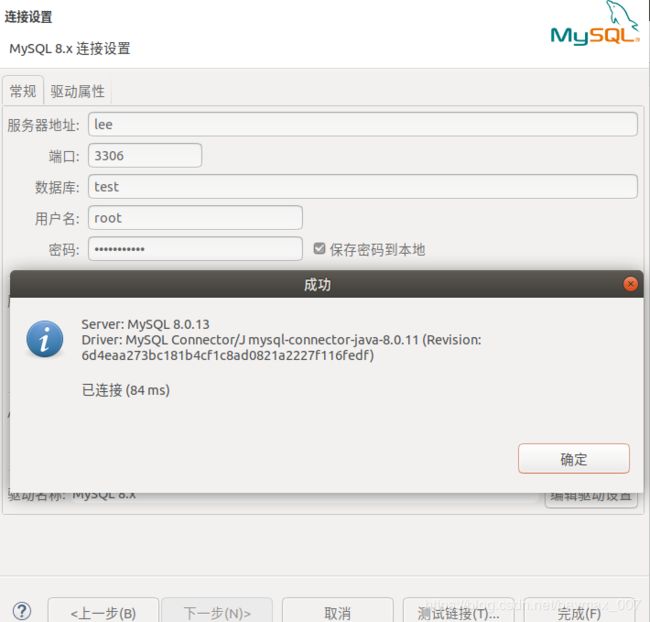
1. mysql连接
配置server IP、server port、database、user、 passwd,并更新驱动项。
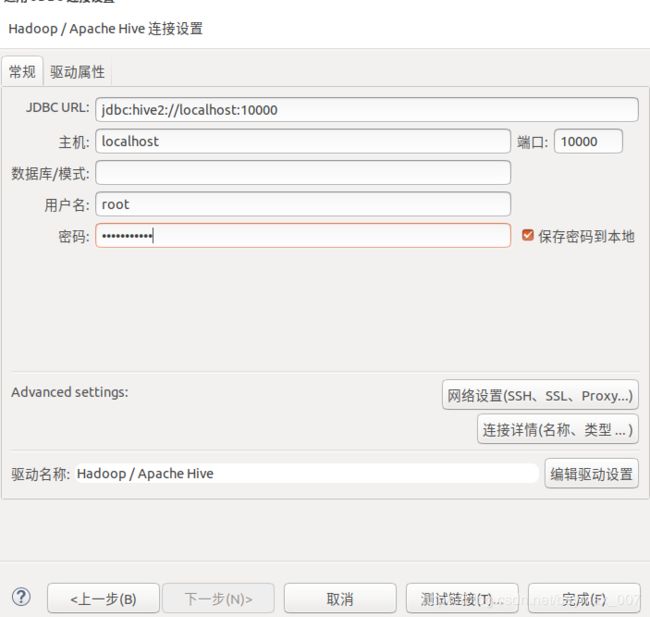
2. hive连接
启动hadoop
{HADOOP_HOME}/sbin/start-all.sh启动hive元数据
{HIVE_HMOE}/bin/hive --service metastore &启动hive thrift
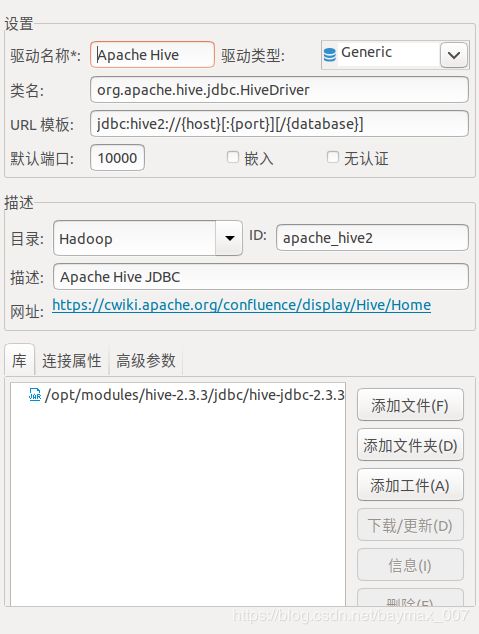
{HIVE_HOME}/bin/hive --service hiveserver2 &配置jdbc:hive2://lee:10000,根据hive版本加载依赖包,可以本地添加:${HIVE_HOME}/jdbc/hive-jdbc-2.3.3-standalone.jar
报错:org.apache.hadoop.ipc.RemoteException:User: lee is not allowed to impersonate root
通过httpfs协议访问rest接口,以root用户包装自己用户的方式操作HDFS
解决方案:
首先需要开启rest接口,在hdfs-site.xml文件中加入:
dfs.webhdfs.enabled
true
在core-site.xml添加如下属性,其中hadoop.proxyuser.root.groups中的root是用户,value里面的root是group
hadoop.proxyuser.lee.groups
*
Allow the superuser lee to impersonate any members of the group group1 and group2
hadoop.proxyuser.lee.hosts
lee
The superuser can connect only from host1 and host2 to impersonate a user
接着报错:
org.apache.hadoop.ipc.RemoteException:Permission denied: user=root, access=EXECUTE, inode="/tmp":lee:supergroup:drwx------
解决方案:
dfs.permissions
false
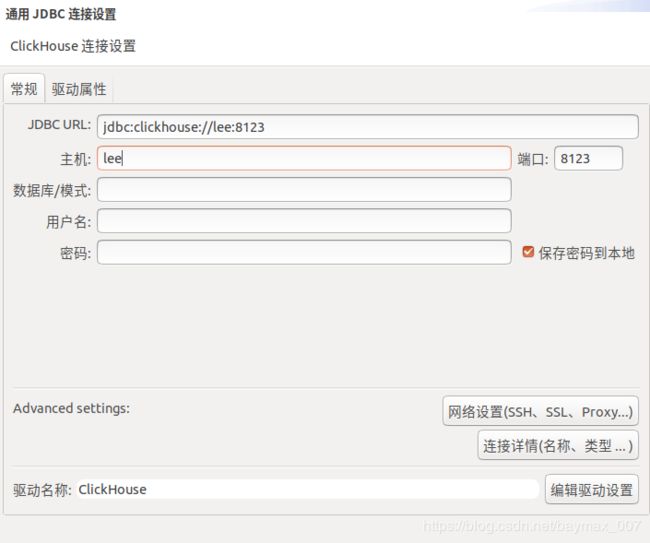
3. clickhouse连接
启动clickhouse
sudo servcie clickhouse-server start配置jdbc:clickhouse://lee:8123,用户名和密码不用填写(账户默认为default,密码为ha256sum的Hash值),更新驱动即可。
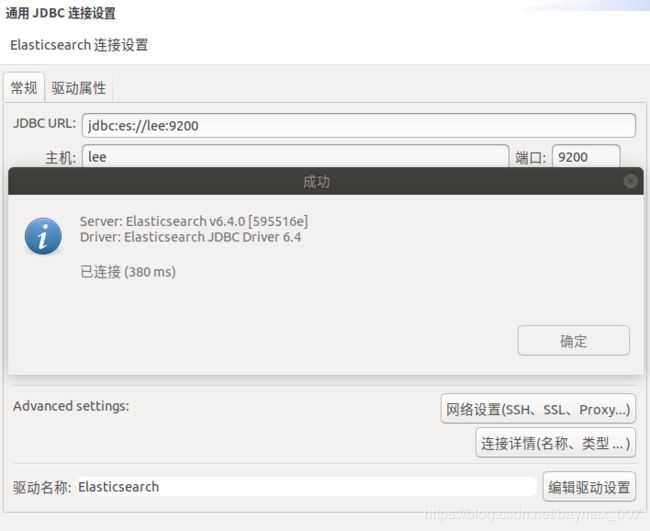
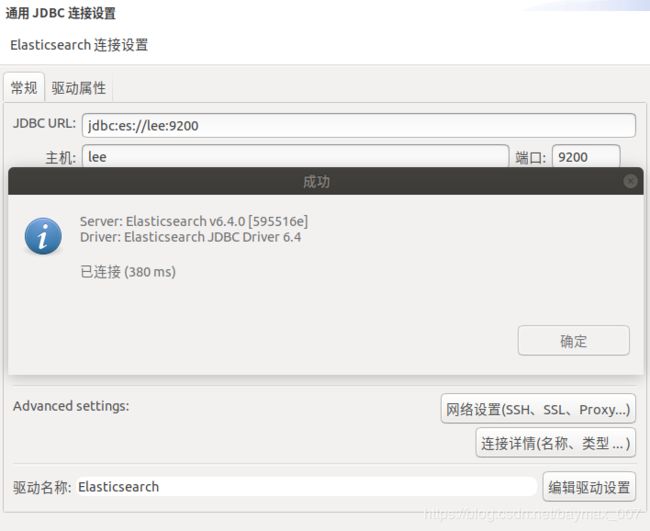
4. elasticsearch连接
启动es
{ELASTICSEARCH_HOME}/bin/elasticsearch -d启动head插件
cd elasticsearch-head
grunt server配置jdbc:es://lee:9200,更新驱动即可。
5. neo4j连接
启动neo4j
{NEO4J_HOME}/bin/neo4j start配置jdbc:neo4j:bolt://lee:7687,更新驱动即可。
6. phoenix连接
6.1 hbase与phoenix整合
首先解压缩
tar -zxvf apache-phoenix-4.14.1-HBase-1.4-bin.tar.gz -C /opt/modules/将phoenix-4.14.1-HBase-1.4-client.jar和phoenix-core-4.14.1-HBase-1.4.jar拷贝到hbase中lib文件夹下
cp phoenix-4.14.1-HBase-1.4-client.jar /opt/modules/hbase-1.4.6/lib/
cp phoenix-core-4.14.1-HBase-1.4.jar /opt/modules/hbase-1.4.6/lib/将hbase/conf目录下 hbase-site.xml 文件放到phoenix的bin目录下
cp conf/hbase-site.xml ../../phoenix-4.14.1/bin/6.2 启动
启动hdaoop
sbin/start-all.sh启动zookeeper
bin/zkServer.sh start启动hbase
bin/hbase shell在Phoenix文件夹下执行,指定zk的地址作为hbase的访问入口
bin/sqlline.py lee:2181注意:由于用的python 3.6.5,会有一些错误如下:
File "bin/sqlline.py", line 116, in
" --verbose=" + args.verbose + " --incremental=false --isolation=TRANSACTION_READ_COMMITTED " + sqlfile
TypeError: must be str, not bytes
解决方案
phoenix_util.py第68行return subprocess.Popen(command, shell=True, stdout=subprocess.PIPE).stdout.read()改为return subprocess.Popen(command, shell=True, stdout=subprocess.PIPE).stdout.read().decode()
6.3 测试
查看表
!tablehbase表映射到phoenix
create table "keyword1"(
rowkey varchar primary key,
"info"."app_id" varchar,
"info"."catalog_name" varchar,
"info"."keyword" varchar,
"info"."keyword_catalog_pv" varchar,
"info"."keyword_catalog_pv_rate" varchar
);使用sql查询
select * form keyword1 limit 5;注意:在hbase中是区分大小写的,在phoenix中不区分大小写,但是默认都是大写,加上双引号就是小写
hbase中的字段类型都是String类型,所以,phoenix中的映射表都得是 varchar类型为好
正确写法如下:
select * from "keyword1" limit 5;查询不到数据,经过阅读官方文档发现,phoenix 4.10 版本后,对列映射做了优化,采用一套新的机制,不在基于列名方式映射到 hbase。
解决方法:
1. 如果只做查询,强烈建议使用 phoenix 视图方式映射,删除视图不影响 hbase 源数据。
create view "keyword2"(
rowkey varchar primary key,
"info"."app_id" varchar,
"info"."catalog_name" varchar,
"info"."keyword" varchar,
"info"."keyword_catalog_pv" varchar,
"info"."keyword_catalog_pv_rate" varchar
);2. 必须要表映射,需要禁用列映射规则(会降低查询性能)
create table "keyword3"(
rowkey varchar primary key,
"info"."app_id" varchar,
"info"."catalog_name" varchar,
"info"."keyword" varchar,
"info"."keyword_catalog_pv" varchar,
"info"."keyword_catalog_pv_rate" varchar
)column_encoded_bytes=0;
6.4 连接
配置jdbc:phoenix:lee,更新驱动即可。
