k近邻法的原理与实现
一、基本概念
k近邻法(k-nearest neighbor, k-NN)是一种基本分类与回归方法,由Cover和Hart于1968年提出。分类时,对于新的实例,根据与它最接近的k个训练实例的类别,通过多数表决等方式,进行预测。对于给定的训练集,当k值,距离度量和分类决策规则(统称三要素)确定后,基于k近邻法的模型就已经确定了。所以,它实际上利用训练集对特征向量空间进行划分,并没有显示的学习过程。k近邻法,符合我们基本的认知,即“物以类聚,人以群分”,一件事物的类别通常与它附近的事物具有相似性。
看一个最简单的例子,当k=1时,即新实例的类别由里它最近的训练实例的类别决定。更一般的,当k>1时,如图1:绿的圆点的类别可能会被预测为红色三角形代表的a类,也可能被预测为蓝色正方形代表的b类。当k=3时,预测为a类,因为红色三角形占2个;当k=5时,预测为b类,因为蓝色正方形占3个。因此,新实例预测的类别会因k值得不同而不同。当k值等于训练集实例的数目时,对于任何新的实例都会被预测为训练集中占多数的那个类别,模型达到最简化,丧失了大部分有用的信息。
(图1 k值的选择)
另外,距离度量除了常用的欧式距离(Euclidean distance),还可以使用曼哈顿距离(Manhattan distance)。更一般的可以用Lp距离(Lp distance)或闵式距离(Minkowski distance)。
二、算法实现:kd树
对于给定训练集,当上述三要素(k值、距离度量和分类决策规则)确定后,新实例的类别就已经确定了。实际上,根本不需要学习的过程,分类仅仅只是在训练集上进行搜索,找出最近的k个实例,通过投票法进行预测。一种最简单的实现是线性扫描(linear scan),即计算训练集中每个实例与新实例的距离,找到最近的k个实例。但是,当训练集很大时,这种算法的效率极其低下。这时,就需要我们用一种特殊的结构对数据集进行存储,以方便进行搜索。
(一)kd树的构造
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分。构造kd树相当于不断利用垂直于坐标轴的超平面将k维空间划分,构成一些列的k维超矩形区域。设想一个最简单的情况(当k=1时),kd树就退化为二叉搜索树,我们可以以O(logn)的时间复杂度查找数据。
构造kd树的方法如下:构造根节点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行划分,生成子节点。在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域划分为左右两个子区域(子结点);这时,实例被分到两个子区域。重复此过程直到子区域没有实例时终止。在此过程中,将实例保存在相应的结点上。
这里有两个需要注意的问题:a. 如何选定坐标轴(维度);b. 如何选定切分点。对于问题a,我们通常选择数据最为分散的维度,即方差最大的维度,有时为了简单也可以循环地选择维度(j(mod k) + 1,其中j为结点的深度)。对于问题b,我们可以选择中位数作为切分点,这样得到的kd树是平衡的,但搜索效率未必是最优的。
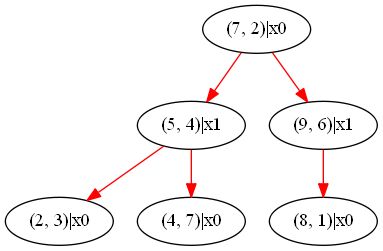
为了便于理解,下面结合实例进行讲述kd树的构造过程。给定一个二维空间的数据集:T = { (2, 3), (5, 4), (9, 6), (4, 7) ,(8, 1), (7, 2) }。根结点对应包含数据集T的矩形,选择x轴(采用循环选择维度的方法,因为根结点的深度为0,根据公式算出此时的维度为1,即x轴),6个数据点的x轴坐标的中位数为7(事实上5也可以,因为有偶数个数字,中位数本应为6,这里没有选6是由于结点必须选择一个存在的实例),以x=7将空间划分为左右两个子矩形({ (2, 3), (5, 4), (4, 7) }和{ (8, 1), (9, 6) });接着左矩形以y=4分为两个子矩形({ (2, 3) }和{ (4, 7) }),右矩形以y=6分为两个子矩形({ (8, 1) }和{})。如此递归,最后得到如图2-1所示的特征空间和如图2-2所示的kd树。
(图2-1 特征空间划分)
(图2-2 kd树示例)
(二)kd树的搜索
利用kd树搜索近邻可以省去对大部分数据点的搜索,从而减少搜索的计算量。为了简单起见,下面以最近邻为例讲述基本方法,k最近邻可以很容易地在此扩展。
给定一个目标点,搜索其最近邻。首先找到包含目标点的叶结点;然后从该叶结点出发,依次回退到父结点;不断查找于目标点最近邻的结点,当确定不可能存在更近的结点时终止。这样的搜索就被限制在空间的局部区域上,效率大为提高。
kd树的搜索方法如下:首先,从上往下搜索包含目标点的最小超矩形区域,并以此叶结点的实例点作为当前最近点。目标点的最近邻一定在以目标点为中心并通过当前最近点的超球体内部。然后返回当前结点的父结点,如果父结点的另一子结点的超矩形区域于超球体相交,移动到另一子结点,递归进行上述搜索过程;如果不相交,向上回退。当回退到根结点时,搜索结束。最后的“当前最近点”即为x的最近邻点。
同样结合实例讲述kd树的搜索过程。如下图2-3所示的特征空间划分和2-4所示的kd树,给定一个目标点S,求S的最近邻。首先在kd树中找到包含S的也结点D,以点D作为当前最近邻。真正最近邻一定在以点S为中心通过点D的圆的内部。由于与其对应的另一子结点F的区域与圆不相交,直接返回结点D的父结点B。此时对应的另一子结点C区域与圆相交,移动到C结点,重复搜索过程,找到新的最近邻点E。此时,真正的最近邻一定在以点S为中心通过点E的圆的内部。由于与其对应的另一子结点的G区域与圆不相交,直接返回点E的父结点C,再返回A结点。最后得到点E是点S的最近邻。
(三)python代码实现
代码运行环境:python 2.7 + pygraphviz 1.3.1 。其中,pygraphviz用于树形结构的可视化。详细代码如下:
from __future__ import division import math import pygraphviz as pgv class Node: def __init__(self, instance, split_dimension, l_child = None, r_child = None,): self.instance = instance # e.g. instance = (1, 2, 3) self.split_dimension = split_dimension # a number that decide the split dimension self.l_child = l_child # left child node self.r_child = r_child # right child node self.accessed = False # record whether the node is accessed """ The class KNN aims to realize the k-nearest neighbor algorithm. The main methods include constructKDTree and searchKDTree. Given a group of instances, the class can find k nearest nodes towards target. Otherwise, it also supports to print kd tree using printKDTree. """ class KNN: def __init__(self, instances, k): self.instances = instances self.k = k self.dimension = len(instances[0]) if instances != [] else 0 self.nearestNodes = []#(distance, node) self.root = None def printKDTree(self): G = pgv.AGraph(strict=True, directed=True) stack = [self.root] while stack != []: node = stack.pop() a = "%s|x%s" % (str(node.instance), str(node.split_dimension)) if node.l_child: stack.append(node.l_child) b = "%s|x%s" % (str(node.l_child.instance), str(node.l_child.split_dimension)) G.add_edge(a, b) if node.r_child: stack.append(node.r_child) b = "%s|x%s" % (str(node.r_child.instance), str(node.r_child.split_dimension)) G.add_edge(a, b) G.edge_attr['color'] = 'red' G.write("tree.dot") G.layout(prog='dot') G.draw('tree.png') def recursive_contruct(self, instances, depth): if instances == []: return None split_dimension = depth % self.dimension instances.sort(key = lambda x:x[split_dimension]) median = len(instances)//2 m_instance = instances[median] l_instances = instances[:median] r_instances = instances[median+1:] del instances[:] lchild = self.recursive_contruct(l_instances, depth + 1) rchild = self.recursive_contruct(r_instances, depth + 1) new_node = Node(m_instance, split_dimension, lchild, rchild) return new_node def constructKDTree(self): instances = self.instances[:] self.root = self.recursive_contruct(instances, 0)#### return self.root def reset(self): del self.nearestNodes[:] stack = [self.root] while stack != []: node = stack.pop() node.accessed = False if node.l_child: stack.append(node.l_child) if node.r_child: stack.append(node.r_child) def distances(self, a, b): distances = 0 for i in range(0, self.dimension): distances += (abs(a[i] - b[i])) ** 2 return math.sqrt(distances) def reachLeafPath(self, start, target): stack = [start] p = start # reach leaf node while p.l_child or p.r_child: if p.l_child and p.r_child: if target[p.split_dimension] <= p.instance[p.split_dimension]: p = p.l_child elif target[p.split_dimension] > p.instance[p.split_dimension]: p = p.r_child else: pass # what if equal ? else: p = p.l_child if p.l_child else p.r_child stack.append(p) return stack def updateNearestNodes(self, instance): cur_dis = self.distances(instance, target) i = 0 while i < len(self.nearestNodes): if cur_dis <= self.nearestNodes[i][0]: break i += 1 self.nearestNodes.insert(i, (cur_dis, instance)) if len(self.nearestNodes) > self.k: self.nearestNodes.pop() def searchKDTree(self, target): stack = self.reachLeafPath(self.root, target) print "The context of stack is: " for i in stack: print i.instance while True: cur_node = stack.pop() cur_node.accessed = True self.updateNearestNodes(cur_node.instance) print "Pop node %s"%str(cur_node.instance) print "The nearest node is: " print self.nearestNodes if stack == []: break father = stack[-1] if abs(father.instance[father.split_dimension] - target[father.split_dimension]) < self.nearestNodes[-1][0]: new_node = father.l_child if father.l_child != cur_node else father.r_child if not new_node.accessed: stack.extend(self.reachLeafPath(new_node, target)) print "Go to the neighbor %s" %str(new_node.instance) print "The context of stack is: " for i in stack: print i.instance self.reset() return self.nearestNodes # some examples instances = [(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)] #instances = [(2,4),(5,1.5),(3,6.5),(7,2.5),(6.5,4.5),(1,1),(1.5,7)] k = 1 target = (6.5,3.5) x = KNN(instances, k) x.constructKDTree() x.printKDTree() x.searchKDTree(target)三、有关问题
(一)时间复杂度
KNN算法包括两个步骤:构造kd树和搜索kd树。构造kd树相当于对所有实例进行了一次排序(O(NlogN)),这个过程只需进行一次。搜索kd树的平均时间复杂度是O(logN),前提是实例点随机分布。kd树更适用于训练实例树远大于空间维数时的k近邻搜索。当实例数接近空间维数时,它的效率就会下降,几乎接近于线性扫描。
(二)空间复杂度
无论是线性扫描还是k近邻搜索,空间复杂度都是O(N),因为都需要存储所有的实例。只不过KNN存储的结构比较特殊,可以把搜索控制在局部范围,以减少搜索带来的巨大开销。
(三)k值的选择
从上述的例子可以看出,k值的大小对预测结果影响很大:太小意味着模型过于复杂,容易发生过拟合;太大意味着模型过于简单,学习的近似误差会增大。通常,会采用交叉验证的方式选择合适的k值。