从输入URL到页面展示,发生了什么?
引子
当我们在浏览器地址栏键入www.baidu.com时,以现在的网络速度,可能不到1s中,我们就能看见百度的首页,那么,从我们输入URL地址,一直到我们看到百度首页,中间到底发生了那些事情呢?
简述
简单来说,发生了三件事情
- 浏览器将请求发送到服务器
- 服务器根据请求返回对应的内容
- 浏览器将返回的内容解析成我们所见的页面
下面,详细来说说,发生的一些事情。
详细说明
浏览器发送请求到服务器
解析URL
第一部分发生的事情,浏览器将请求发送到服务器,当我们输入URL时,浏览器首先要解析URL,一个URL包含以下几个部分:
- 协议头:例如https,http等
- 主机域名或IP地址
- 文件路径
- 查询参数
- 片段标识符
例如http://www.moecai.com/blog/2018/11/HTTP%E4%B9%8B%E6%88%91%E8%A7%81.html#more这个地址,http就是协议头部分,www.moecai.com就是域名部分,blog/2018/11/HTTP%E4%B9%8B%E6%88%91%E8%A7%81.html就是访问的文件路径,当然现在很多页面都不是直接访问某个路径,而是访问某个API了,#more这一段就是片段标识符,可能比较陌生,其实也很常见,例如我们在MDN上查询某个API时,这些API都写在一页上,我们可以通过点击侧边的目录快速跳转到制定API的位置,这时就会有这个标识符,标明文档的某个位置。
DNS解析
URL解析后,浏览器知道了协议和地址,就要向指定的地址发送请求,可是大部分时候,地址都是一段域名,浏览器需要经过DNS解析,才能知道这个域名对应的IP地址是多少,然后成功发送请求,而这个解析过程,也分为多个步骤:
- 浏览器缓存
- 本地HOST
- 向DNS服务器查询
如果请求页面前浏览器有缓存,那么直接使用缓存,没有则使用主机指定的HOST,HOST也没有则向当地网络最近的DNS服务器发送请求,查出对应IP
HTTP请求
当知道协议和IP地址后,自然就要进行相应的请求了,这里以HTTP为例,发送一个HTTP请求,HTTP请求是应用层协议,它基于传输层协议TCP,这里就引入一个常见的三次握手操作:
- 客户端发送一个带有SYN标志的数据包(服务器,我想和你通信)
- 服务端响应,返回一个带有SYN/ACK标志的数据包(嗯,明白了,我收到了你的通信请求)
- 客户端返回一个ACK标志的数据包,握手结束(嗯,明白了)
然后就开始了正式通信,那么HTTP请求的数据具体是怎么发送的呢,这里用一张图说明以下吧:

到这里,服务端就接收到了浏览器发送的HTTP请求啦!
服务端根据请求返回对应的内容
假设我们的服务器使用的nginx进行代理提供服务,那么,当指定域名接受到请求的时候,nginx会查询自己配置文件的所有的server_name,判断是匹配的内容,还是拿上面那个URL地址来分析,http://www.moecai.com/blog/2018/11/HTTP%E4%B9%8B%E6%88%91%E8%A7%81.html#more,nginx配置文件中有一个server_name为moecai.com,root为/home/test/blog,那么就会访问到该目录下查找对应文件,找到对应文件就返回,没有找到对应文件就返回一个404错误。
这里由于我的博客是静态博客,所以没有进行后端的一些特殊处理,直接返回了静态文件,实际一般是
control将数据与对应视图组装起来,生成页面后返回给浏览器,后端我也不是非常了解,其中还有很多关于缓存、Cookie负载均衡等的很多内容,可以自行Google
浏览器解析返回的内容
服务器返回的页面无非由三部分组成,HTML+CSS+JS,那么浏览器是如何解析返回的内容的呢?(以下部分内容来自参考来源)
浏览器解析大概遵循以下几步:
- 解析HTML,构建DOM树
- 解析CSS,生成CSS规则树
- 将DOM树和CSS树合并,生成render树
- 布局render树(Layout/reflow),负责各元素尺寸、位置的计算
- 绘制render树(paint),绘制页面像素信息
- 浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上
HTML解析
假设有以下代码
Critical Path
Hello web performance students!

浏览器通过HTML规范,将这串代码转化成为指定的一个个分词,像是StartTag:html、StartTag:head……EndTag:html等等,然后通过词法分析,将这些分词转化为一个个对象,然后由于HTML标签定义了不同的标签关系,联系起来构建成一个DOM树,如下图:

CSS解析
CSS解析与HTML解析类似
body {
font-size: 16px
}
p {
font-weight: bold
}
span {
color: red
}
p span {
display: none
}
img {
float: right
}
CSSOM树:

构建渲染树
有了DOM树和CSS树后,浏览器将二者结合起来,生成render树,用于渲染:
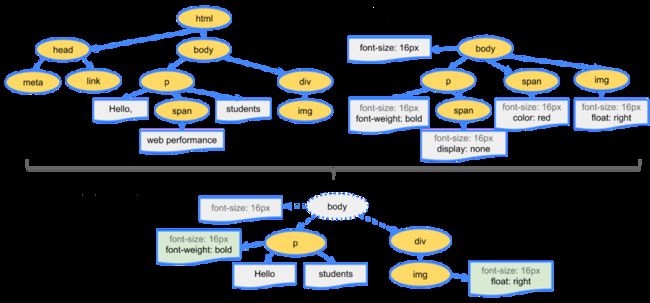
渲染需要进行四个步骤
- 计算CSS样式
- 构建渲染树
- 布局,定位各个DOM的坐标、大小等等
- 绘制,在页面中将图像绘制出来
如果JS动态修改了DOM或CSS,就会导致重新布局或渲染,而对DOM的修改会导致重构DOM树和渲染树,所以在JS优化中一般是尽可能少的改变DOM。
JS解析
JS的解析过程可以看作是JS代码的一个编译执行过程,这里以var a = 1,这段代码的编译执行来简述以下JS代码的编译执行,具体内容可以参考*《你不知道的JavaScript 上卷》*。
var a = 1,可能我们会认为这是一个声明操作,实际上,这段代码进行了两个操作,一个由编译器编译时进行,另一个由引擎执行时进行。
var a,当编译器遇到这段代码时,首先会询问当前作用域是否有一个为a变量,如果有,就会忽略该声明,如果没有,则在当前作用域声明一个新的变量,并命名为a。- 接下来便一起生成引擎所要执行的代码
a = 2,这是一个赋值操作,当引擎执行该代码时,会查询当前作用域是否有一个变量a,如果有,则执行赋值操作,如果没有,则会在外层作用域继续查找该变量,如果一直都没有找到该变量,就会抛出异常。
结果
经过这三个过程后,返回的文档就被解析渲染成了我们所见的页面,总结以下就是获取返回内容->HTML解析DOM树/CSS解析规则树->合并成render树->render树进行渲染;其中在HTML解析过程中可能会遇到JS内容,此时会进行JS解释编译执行操作,最后得到我们所见的页面。
小结
从输入URL到页面展示所发生的内容远远不止这些,实际上有很多点可以扩展,例如后端部分的服务器对请求的响应,JS解释执行的细节,浏览器渲染和解析的规则等等,感觉这个问题其实可以在学习或工作的各个阶段都拿出来分析整理以下,在不同的场景下它的侧重点也有很多不同。本文参考了很多网上的资料,限于个人水平,有些内容无法理解所以没有添加进来,具体参考链接会在下面放出。
参考链接
从输入URL到页面加载的过程?如何由一道题完善自己的前端知识体系!
浏览器的工作原理:新式网络浏览器幕后揭秘
参考书籍
你不知道的JavaScript(上卷)
计算机网络:自顶向下
图解HTTP
版权声明
本作品采用知识共享署名 4.0 国际许可协议进行许可