MySQL · 引擎特性 · InnoDB 崩溃恢复过程
一 序
之前整理了 InnoDB redo log 和 undo log 的相关知识,本文整理 InnoDB 在崩溃恢复时的主要流程。在《MYSQL运维内参》第11章是穿插着讲,在redo log跟undo log.总体上还是taobao.mysql 介绍的全面,本文主要以taobao.mysql为主。
Crash Recovery流程
innobase_init 源码在innobase/handler/ha_innodb.cc
-->innobase_start_or_create_for_mysql 源码在innobase/srv/srv0start.cc
本文代码分析基于 MySQL 5.7.18 版本,函数入口为 innobase_start_or_create_for_mysql,这是一个非常长的函数,本文只涉及和崩溃恢复相关的代码。这个图可以对比书上的流程来帮助理解,因为牵扯功能点多,容易混乱。
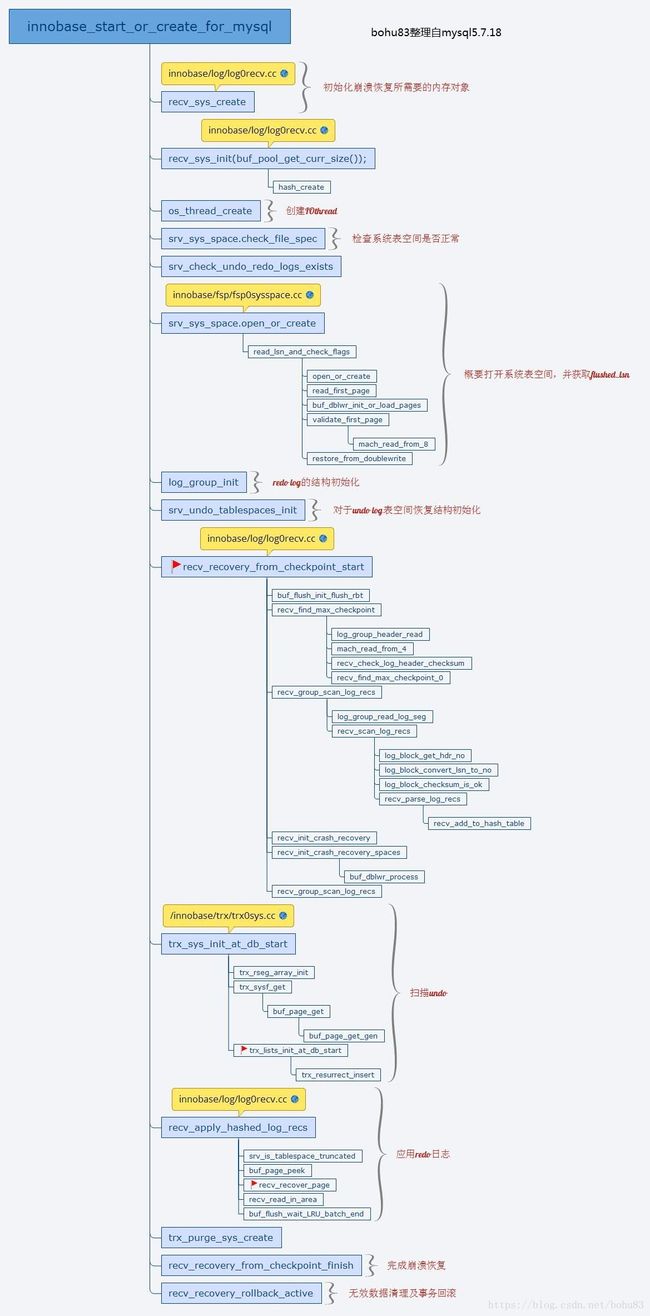
二 初始化崩溃恢复
首先初始化崩溃恢复所需要的内存对象:
recv_sys_create();
recv_sys_init(buf_pool_get_curr_size());
当InnoDB正常shutdown,在flush redo log 和脏页后,会做一次完全同步的checkpoint,并将checkpoint的LSN写到ibdata的第一个page中(fil_write_flushed_lsn)。
在重启实例时,会打开系统表空间ibdata,并读取存储在其中的LSN:
err = srv_sys_space.open_or_create(
false, &sum_of_new_sizes, &flushed_lsn);
上述调用将从ibdata中读取的LSN存储到变量flushed_lsn中,表示上次shutdown时的checkpoint点,在后面做崩溃恢复时会用到。另外这里也会将double write buffer内存储的page载入到内存中(buf_dblwr_init_or_load_pages),如果ibdata的第一个page损坏了,就从dblwr中恢复出来。
三 进入redo崩溃恢复开始逻辑
入口函数:
err = recv_recovery_from_checkpoint_start(flushed_lsn);
传递的参数flushed_lsn即为从ibdata第一个page读取的LSN,主要包含以下几步:
Step 1: 为每个buffer pool instance创建一棵红黑树,指向buffer_pool_t::flush_rbt,主要用于加速插入flush list (buf_flush_init_flush_rbt); Step 2: 读取存储在第一个redo log文件头的CHECKPOINT LSN,并根据该LSN定位到redo日志文件中对应的位置,从该checkpoint点开始扫描。以下代码为recv_find_max_checkpoint之后的调用recv_group_scan_log_recs
/* Look for MLOG_CHECKPOINT. */
recv_group_scan_log_recs(group, &contiguous_lsn, false);
/* The first scan should not have stored or applied any records. */
ut_ad(recv_sys->n_addrs == 0);
ut_ad(!recv_sys->found_corrupt_fs);
if (recv_sys->found_corrupt_log && !srv_force_recovery) {
log_mutex_exit();
return(DB_ERROR);
}
if (recv_sys->mlog_checkpoint_lsn == 0) {
if (!srv_read_only_mode
&& group->scanned_lsn != checkpoint_lsn) {
ib::error() << "Ignoring the redo log due to missing"
" MLOG_CHECKPOINT between the checkpoint "
<< checkpoint_lsn << " and the end "
<< group->scanned_lsn << ".";
if (srv_force_recovery < SRV_FORCE_NO_LOG_REDO) {
log_mutex_exit();
return(DB_ERROR);
}
}
group->scanned_lsn = checkpoint_lsn;
rescan = false;
} else {
contiguous_lsn = checkpoint_lsn;
rescan = recv_group_scan_log_recs(
group, &contiguous_lsn, false);
if ((recv_sys->found_corrupt_log && !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
}
/* NOTE: we always do a 'recovery' at startup, but only if
there is something wrong we will print a message to the
user about recovery: */
if (checkpoint_lsn != flush_lsn) {
if (checkpoint_lsn + SIZE_OF_MLOG_CHECKPOINT < flush_lsn) {
ib::warn() << " Are you sure you are using the"
" right ib_logfiles to start up the database?"
" Log sequence number in the ib_logfiles is "
<< checkpoint_lsn << ", less than the"
" log sequence number in the first system"
" tablespace file header, " << flush_lsn << ".";
}
if (!recv_needed_recovery) {
ib::info() << "The log sequence number " << flush_lsn
<< " in the system tablespace does not match"
" the log sequence number " << checkpoint_lsn
<< " in the ib_logfiles!";
if (srv_read_only_mode) {
ib::error() << "Can't initiate database"
" recovery, running in read-only-mode.";
log_mutex_exit();
return(DB_READ_ONLY);
}
recv_init_crash_recovery();
}
}
log_sys->lsn = recv_sys->recovered_lsn;
if (recv_needed_recovery) {
err = recv_init_crash_recovery_spaces();
if (err != DB_SUCCESS) {
log_mutex_exit();
return(err);
}
if (rescan) {
contiguous_lsn = checkpoint_lsn;
recv_group_scan_log_recs(group, &contiguous_lsn, true);
if ((recv_sys->found_corrupt_log
&& !srv_force_recovery)
|| recv_sys->found_corrupt_fs) {
log_mutex_exit();
return(DB_ERROR);
}
}
} else {
ut_ad(!rescan || recv_sys->n_addrs == 0);
}
在这里会调用三次recv_group_scan_log_recs扫描redo log文件:
1. 第一次的目的是找到MLOG_CHECKPOINT日志
MLOG_CHECKPOINT 日志中记录了CHECKPOINT LSN,当该日志中记录的LSN和日志头中记录的CHECKPOINT LSN相同时,表示找到了符合的MLOG_CHECKPOINT LSN,将扫描到的LSN号记录到 recv_sys->mlog_checkpoint_lsn 中。(在5.6版本里没有这一次扫描)
MLOG_CHECKPOINT在WL#7142中被引入,其目的是为了简化 InnoDB 崩溃恢复的逻辑,根据WL#7142的描述,包含几点改进:
- 避免崩溃恢复时读取每个ibd的第一个page来确认其space id;
- 无需检查$datadir/*.isl,新的日志类型记录了文件全路径,并消除了isl文件和实际ibd目录的不一致可能带来的问题;
- 自动忽略那些还没有导入到InnoDB的ibd文件(例如在执行IMPORT TABLESPACE时crash);
- 引入了新的日志类型MLOG_FILE_DELETE来跟踪ibd文件的删除操作。
2. 第二次扫描,再次从checkpoint点开始重复扫描,存储日志对象
日志解析后的对象类型为recv_t,包含日志类型、长度、数据、开始和结束LSN。日志对象的存储使用hash结构,根据 space id 和 page no 计算hash值,相同页上的变更作为链表节点链在一起,大概结构可以表示为:
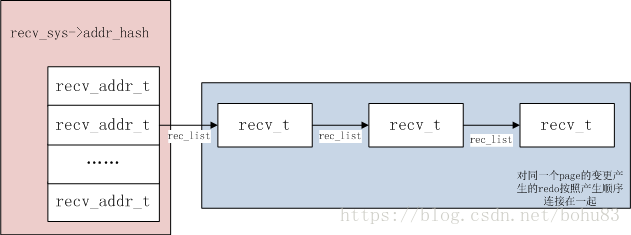
扫描的过程中,会基于MLOG_FILE_NAME 和MLOG_FILE_DELETE 这样的redo日志记录来构建recv_spaces,存储space id到文件信息的映射(fil_name_parse –> fil_name_process),这些文件可能需要进行崩溃恢复。(实际上第一次扫描时,也会向recv_spaces中插入数据,但只到MLOG_CHECKPOINT日志记录为止)
Tips:在一次checkpoint后第一次修改某个表的数据时,总是先写一条MLOG_FILE_NAME 日志记录;通过该类型的日志可以跟踪一次CHECKPOINT后修改过的表空间,避免打开全部表。 在第二次扫描时,总会判断将要修改的表空间是否在
recv_spaces中,如果不存在,则认为产生列严重的错误,拒绝启动(recv_parse_or_apply_log_rec_body)
默认情况下,Redo log以一批64KB(RECV_SCAN_SIZE)为单位读入到log_sys->buf中,然后调用函数recv_scan_log_recs处理日志块。这里会判断到日志块的有效性:是否是完整写入的、日志块checksum是否正确, 另外也会根据一些标记位来做判断:
- 在每次写入redo log时,总会将写入的起始block头的flush bit设置为true,表示一次写入的起始位置,因此在重启扫描日志时,也会根据flush bit来推进扫描的LSN点;
- 每次写redo时,还会在每个block上记录下一个checkpoint no(每次做checkpoint都会递增),由于日志文件是循环使用的,因此需要根据checkpoint no判断是否读到了老旧的redo日志。
对于合法的日志,会拷贝到缓冲区recv_sys->buf中,调用函数recv_parse_log_recs解析日志记录。 这里会根据不同的日志类型分别进行处理,并尝试进行apply,堆栈为:
recv_parse_log_recs
--> recv_parse_log_rec
--> recv_parse_or_apply_log_rec_body
如果想理解InnoDB如何基于不同的日志类型进行崩溃恢复的,非常有必要细读函数recv_parse_or_apply_log_rec_body,这里是redo日志apply的入口。
例如如果解析到的日志类型为MLOG_UNDO_HDR_CREATE,就会从日志中解析出事务ID,为其重建undo log头(trx_undo_parse_page_header);如果是一条插入操作标识(MLOG_REC_INSERT 或者 MLOG_COMP_REC_INSERT),就需要从中解析出索引信息(mlog_parse_index)和记录信息(page_cur_parse_insert_rec);或者解析一条IN-PLACE UPDATE (MLOG_REC_UPDATE_IN_PLACE)日志,则调用函数btr_cur_parse_update_in_place。第二次扫描只会应用MLOG_FILE_*类型的日志,记录到recv_spaces中,对于其他类型的日志在解析后存储到哈希对象里。
3. 如果第二次扫描hash表空间不足,无法全部存储到hash表中,则发起第三次扫描,清空hash,重新从checkpoint点开始扫描。
hash对象的空间最大一般为buffer pool size - 512个page大小。
第三次扫描不会尝试一起全部存储到hash里,而是一旦发现hash不够了,就立刻apply redo日志。但是…如果总的日志需要存储的hash空间略大于可用的最大空间,那么一次额外的扫描开销还是非常明显的。
简而言之,第一次扫描找到正确的MLOG_CHECKPOINT位置;第二次扫描解析 redo 日志并存储到hash中;如果hash空间不够用,则再来一轮重新开始,解析一批,应用一批。
看下对应的源码:
recv_group_scan_log_recs(
log_group_t* group,
lsn_t* contiguous_lsn,
bool last_phase)
{
DBUG_ENTER("recv_group_scan_log_recs");
DBUG_ASSERT(!last_phase || recv_sys->mlog_checkpoint_lsn > 0);
mutex_enter(&recv_sys->mutex);
recv_sys->len = 0;
recv_sys->recovered_offset = 0;
recv_sys->n_addrs = 0;
recv_sys_empty_hash();
srv_start_lsn = *contiguous_lsn;
recv_sys->parse_start_lsn = *contiguous_lsn;
recv_sys->scanned_lsn = *contiguous_lsn;
recv_sys->recovered_lsn = *contiguous_lsn;
recv_sys->scanned_checkpoint_no = 0;
recv_previous_parsed_rec_type = MLOG_SINGLE_REC_FLAG;
recv_previous_parsed_rec_offset = 0;
recv_previous_parsed_rec_is_multi = 0;
ut_ad(recv_max_page_lsn == 0);
ut_ad(last_phase || !recv_writer_thread_active);
mutex_exit(&recv_sys->mutex);
lsn_t checkpoint_lsn = *contiguous_lsn;
lsn_t start_lsn;
lsn_t end_lsn;
// 在此会根据三个不同的阶段调用不同的变量
// 1. 如果还没有扫描到MLOG_CHECKPOINT,则为STORE_NO
// 2. 第二次扫描则为STORE_YES
// 3. 第三次扫描则为STORE_IF_EXISTS
store_t store_to_hash = recv_sys->mlog_checkpoint_lsn == 0
? STORE_NO : (last_phase ? STORE_IF_EXISTS : STORE_YES);
ulint available_mem = UNIV_PAGE_SIZE
* (buf_pool_get_n_pages()
- (recv_n_pool_free_frames * srv_buf_pool_instances));
end_lsn = *contiguous_lsn = ut_uint64_align_down(
*contiguous_lsn, OS_FILE_LOG_BLOCK_SIZE);
do {
if (last_phase && store_to_hash == STORE_NO) {
store_to_hash = STORE_IF_EXISTS;
/* We must not allow change buffer
merge here, because it would generate
redo log records before we have
finished the redo log scan. */
recv_apply_hashed_log_recs(FALSE);
}
start_lsn = end_lsn; //下一个分片,从上一个分片结束位置开始
end_lsn += RECV_SCAN_SIZE;//RECV_SCAN_SIZE 64K,innodb与lsn增长同步,表示2M日志量
//从磁盘中读取数据,lsn偏移位置读取2M
log_group_read_log_seg(
log_sys->buf, group, start_lsn, end_lsn);
// 从缓存中读取日志,并解析,当hash表满时则直接执行
//recv_scan_log_recs 会检查日志已经分析完毕,redo就算基本完成
} while (!recv_scan_log_recs(
available_mem, &store_to_hash, log_sys->buf,
RECV_SCAN_SIZE,
checkpoint_lsn,
start_lsn, contiguous_lsn, &group->scanned_lsn));
if (recv_sys->found_corrupt_log || recv_sys->found_corrupt_fs) {
DBUG_RETURN(false);
}
DBUG_PRINT("ib_log", ("%s " LSN_PF
" completed for log group " ULINTPF,
last_phase ? "rescan" : "scan",
group->scanned_lsn, group->id));
DBUG_RETURN(store_to_hash == STORE_NO);
}上面的代码可以看出,recv_group_scan_log_recs主要是从lsn位置开始,日志分片处理,每个分片2M大小。INNODB如何做分片的,有函数recv_scan_log_recs实现。
recv_scan_log_recs(
/*===============*/
ulint available_memory,/*!< in: we let the hash table of recs
to grow to this size, at the maximum */
store_t* store_to_hash, /*!< in,out: whether the records should be
stored to the hash table; this is reset
if just debug checking is needed, or
when the available_memory runs out */
const byte* buf, /*!< in: buffer containing a log
segment or garbage */
ulint len, /*!< in: buffer length */
lsn_t checkpoint_lsn, /*!< in: latest checkpoint LSN */
lsn_t start_lsn, /*!< in: buffer start lsn */
lsn_t* contiguous_lsn, /*!< in/out: it is known that all log
groups contain contiguous log data up
to this lsn */
lsn_t* group_scanned_lsn)/*!< out: scanning succeeded up to
this lsn */
{
const byte* log_block = buf;
ulint no;
lsn_t scanned_lsn = start_lsn;
bool finished = false;
ulint data_len;
bool more_data = false;
bool apply = recv_sys->mlog_checkpoint_lsn != 0;
ulint recv_parsing_buf_size = RECV_PARSING_BUF_SIZE;
ut_ad(start_lsn % OS_FILE_LOG_BLOCK_SIZE == 0);
ut_ad(len % OS_FILE_LOG_BLOCK_SIZE == 0);
ut_ad(len >= OS_FILE_LOG_BLOCK_SIZE);
do {
ut_ad(!finished);
no = log_block_get_hdr_no(log_block);
ulint expected_no = log_block_convert_lsn_to_no(scanned_lsn);
if (no != expected_no) {
/* Garbage or an incompletely written log block.
We will not report any error, because this can
happen when InnoDB was killed while it was
writing redo log. We simply treat this as an
abrupt end of the redo log. */
finished = true;
break;
}
if (!log_block_checksum_is_ok(log_block)) {
ib::error() << "Log block " << no <<
" at lsn " << scanned_lsn << " has valid"
" header, but checksum field contains "
<< log_block_get_checksum(log_block)
<< ", should be "
<< log_block_calc_checksum(log_block);
/* Garbage or an incompletely written log block.
This could be the result of killing the server
while it was writing this log block. We treat
this as an abrupt end of the redo log. */
finished = true;
break;
}
if (log_block_get_flush_bit(log_block)) {
/* This block was a start of a log flush operation:
we know that the previous flush operation must have
been completed for all log groups before this block
can have been flushed to any of the groups. Therefore,
we know that log data is contiguous up to scanned_lsn
in all non-corrupt log groups. */
if (scanned_lsn > *contiguous_lsn) {
*contiguous_lsn = scanned_lsn;
}
}
//读取当前块中存储的数据量,一个块大小默认是log_block 512字节
data_len = log_block_get_data_len(log_block);
//是否结束
if (scanned_lsn + data_len > recv_sys->scanned_lsn
&& log_block_get_checkpoint_no(log_block)
< recv_sys->scanned_checkpoint_no
&& (recv_sys->scanned_checkpoint_no
- log_block_get_checkpoint_no(log_block)
> 0x80000000UL)) {
/* Garbage from a log buffer flush which was made
before the most recent database recovery */
finished = true;
break;
}
if (!recv_sys->parse_start_lsn
&& (log_block_get_first_rec_group(log_block) > 0)) {
/* We found a point from which to start the parsing
of log records */
recv_sys->parse_start_lsn = scanned_lsn
+ log_block_get_first_rec_group(log_block);
recv_sys->scanned_lsn = recv_sys->parse_start_lsn;
recv_sys->recovered_lsn = recv_sys->parse_start_lsn;
}
scanned_lsn += data_len;
//当前块有数据,处理当前块
if (scanned_lsn > recv_sys->scanned_lsn) {
/* We have found more entries. If this scan is
of startup type, we must initiate crash recovery
environment before parsing these log records. */
#ifndef UNIV_HOTBACKUP
if (!recv_needed_recovery) {
if (!srv_read_only_mode) {
ib::info() << "Log scan progressed"
" past the checkpoint lsn "
<< recv_sys->scanned_lsn;
recv_init_crash_recovery();
} else {
ib::warn() << "Recovery skipped,"
" --innodb-read-only set!";
return(true);
}
}
#endif /* !UNIV_HOTBACKUP */
/* We were able to find more log data: add it to the
parsing buffer if parse_start_lsn is already
non-zero */
DBUG_EXECUTE_IF(
"reduce_recv_parsing_buf",
recv_parsing_buf_size
= (70 * 1024);
);
if (recv_sys->len + 4 * OS_FILE_LOG_BLOCK_SIZE
>= recv_parsing_buf_size) {
ib::error() << "Log parsing buffer overflow."
" Recovery may have failed!";
recv_sys->found_corrupt_log = true;
#ifndef UNIV_HOTBACKUP
if (!srv_force_recovery) {
ib::error()
<< "Set innodb_force_recovery"
" to ignore this error.";
return(true);
}
#endif /* !UNIV_HOTBACKUP */
} else if (!recv_sys->found_corrupt_log) {
//把当前块真正日志数据拿出来,放到recv_sys缓存去
more_data = recv_sys_add_to_parsing_buf(
log_block, scanned_lsn);
}
//更新scanned_lsn,表示已经扫描到这里
recv_sys->scanned_lsn = scanned_lsn;
recv_sys->scanned_checkpoint_no
= log_block_get_checkpoint_no(log_block);
}
//日志快不足512,表示redo日志扫描已经结束,已经到了日志结束的位置
if (data_len < OS_FILE_LOG_BLOCK_SIZE) {
/* Log data for this group ends here */
finished = true;
break;
} else {
//没结束则扫下一个块
log_block += OS_FILE_LOG_BLOCK_SIZE;
}
} while (log_block < buf + len);
*group_scanned_lsn = scanned_lsn;
if (recv_needed_recovery
|| (recv_is_from_backup && !recv_is_making_a_backup)) {
recv_scan_print_counter++;
if (finished || (recv_scan_print_counter % 80 == 0)) {
ib::info() << "Doing recovery: scanned up to"
" log sequence number " << scanned_lsn;
}
}
//上面已经将当前块或者之前块日志放入recv_sys缓存了,下面是对这部分数据进行处理,调用recv_parse_log_recs
if (more_data && !recv_sys->found_corrupt_log) {
/* Try to parse more log records */
if (recv_parse_log_recs(checkpoint_lsn,
*store_to_hash, apply)) {
ut_ad(recv_sys->found_corrupt_log
|| recv_sys->found_corrupt_fs
|| recv_sys->mlog_checkpoint_lsn
== recv_sys->recovered_lsn);
return(true);
}
//这里判断占用空间与可用空间,是否存到hash_table
if (*store_to_hash != STORE_NO
&& mem_heap_get_size(recv_sys->heap) > available_memory) {
*store_to_hash = STORE_NO;
}
//处理掉一部分日志后,缓冲区一版会有部分剩余不完整的日志,这部分日志需要读取更多日志
//拼接后继续处理
if (recv_sys->recovered_offset > recv_parsing_buf_size / 4) {
/* Move parsing buffer data to the buffer start */
recv_sys_justify_left_parsing_buf();
}
}
return(finished);
}上面代码可知,INNODB管理日志文件,就是连续的日志内容以块为单位来存储,加上头尾连续第存储。使用的时候,又把日志以块为单位读进来,去掉头尾拼接在一起,进一步做分析处理。下面我们就看看recv_parse_log_recs如何处理的
recv_parse_log_recs(
lsn_t checkpoint_lsn,
store_t store,
bool apply)
{
byte* ptr;
byte* end_ptr;
bool single_rec;
ulint len;
lsn_t new_recovered_lsn;
lsn_t old_lsn;
mlog_id_t type;
ulint space;
ulint page_no;
byte* body;
ut_ad(log_mutex_own());
ut_ad(recv_sys->parse_start_lsn != 0);
loop:
ptr = recv_sys->buf + recv_sys->recovered_offset;
end_ptr = recv_sys->buf + recv_sys->len;
if (ptr == end_ptr) {
return(false);
}
switch (*ptr) {
case MLOG_CHECKPOINT:
#ifdef UNIV_LOG_LSN_DEBUG
case MLOG_LSN:
#endif /* UNIV_LOG_LSN_DEBUG */
case MLOG_DUMMY_RECORD:
single_rec = true;
break;
default:
single_rec = !!(*ptr & MLOG_SINGLE_REC_FLAG);
}
if (single_rec) {
/* The mtr did not modify multiple pages */
old_lsn = recv_sys->recovered_lsn;
/* Try to parse a log record, fetching its type, space id,
page no, and a pointer to the body of the log record */
len = recv_parse_log_rec(&type, ptr, end_ptr, &space,
&page_no, apply, &body);
if (len == 0) {
return(false);
}
if (recv_sys->found_corrupt_log) {
recv_report_corrupt_log(
ptr, type, space, page_no);
return(true);
}
if (recv_sys->found_corrupt_fs) {
return(true);
}
new_recovered_lsn = recv_calc_lsn_on_data_add(old_lsn, len);
if (new_recovered_lsn > recv_sys->scanned_lsn) {
/* The log record filled a log block, and we require
that also the next log block should have been scanned
in */
return(false);
}
recv_previous_parsed_rec_type = type;
recv_previous_parsed_rec_offset = recv_sys->recovered_offset;
recv_previous_parsed_rec_is_multi = 0;
recv_sys->recovered_offset += len;
recv_sys->recovered_lsn = new_recovered_lsn;
switch (type) {
lsn_t lsn;
case MLOG_DUMMY_RECORD:
/* Do nothing */
break;
case MLOG_CHECKPOINT:
#if SIZE_OF_MLOG_CHECKPOINT != 1 + 8
# error SIZE_OF_MLOG_CHECKPOINT != 1 + 8
#endif
lsn = mach_read_from_8(ptr + 1);
DBUG_PRINT("ib_log",
("MLOG_CHECKPOINT(" LSN_PF ") %s at "
LSN_PF,
lsn,
lsn != checkpoint_lsn ? "ignored"
: recv_sys->mlog_checkpoint_lsn
? "reread" : "read",
recv_sys->recovered_lsn));
if (lsn == checkpoint_lsn) {
if (recv_sys->mlog_checkpoint_lsn) {
/* At recv_reset_logs() we may
write a duplicate MLOG_CHECKPOINT
for the same checkpoint LSN. Thus
recv_sys->mlog_checkpoint_lsn
can differ from the current LSN. */
ut_ad(recv_sys->mlog_checkpoint_lsn
<= recv_sys->recovered_lsn);
break;
}
recv_sys->mlog_checkpoint_lsn
= recv_sys->recovered_lsn;
#ifndef UNIV_HOTBACKUP
return(true);
#endif /* !UNIV_HOTBACKUP */
}
break;
case MLOG_FILE_NAME:
case MLOG_FILE_DELETE:
case MLOG_FILE_CREATE2:
case MLOG_FILE_RENAME2:
case MLOG_TRUNCATE:
/* These were already handled by
recv_parse_log_rec() and
recv_parse_or_apply_log_rec_body(). */
break;
#ifdef UNIV_LOG_LSN_DEBUG
case MLOG_LSN:
/* Do not add these records to the hash table.
The page number and space id fields are misused
for something else. */
break;
#endif /* UNIV_LOG_LSN_DEBUG */
default:
switch (store) {
case STORE_NO:
break;
case STORE_IF_EXISTS:
if (fil_space_get_flags(space)
== ULINT_UNDEFINED) {
break;
}
/* fall through */
case STORE_YES:
recv_add_to_hash_table(
type, space, page_no, body,
ptr + len, old_lsn,
recv_sys->recovered_lsn);
}
/* fall through */
case MLOG_INDEX_LOAD:
DBUG_PRINT("ib_log",
("scan " LSN_PF ": log rec %s"
" len " ULINTPF
" page " ULINTPF ":" ULINTPF,
old_lsn, get_mlog_string(type),
len, space, page_no));
}
} else {
/* Check that all the records associated with the single mtr
are included within the buffer */
ulint total_len = 0;
ulint n_recs = 0;
bool only_mlog_file = true;
ulint mlog_rec_len = 0;
for (;;) {
len = recv_parse_log_rec(
&type, ptr, end_ptr, &space, &page_no,
false, &body);
if (len == 0) {
return(false);
}
if (recv_sys->found_corrupt_log
|| type == MLOG_CHECKPOINT
|| (*ptr & MLOG_SINGLE_REC_FLAG)) {
recv_sys->found_corrupt_log = true;
recv_report_corrupt_log(
ptr, type, space, page_no);
return(true);
}
if (recv_sys->found_corrupt_fs) {
return(true);
}
recv_previous_parsed_rec_type = type;
recv_previous_parsed_rec_offset
= recv_sys->recovered_offset + total_len;
recv_previous_parsed_rec_is_multi = 1;
/* MLOG_FILE_NAME redo log records doesn't make changes
to persistent data. If only MLOG_FILE_NAME redo
log record exists then reset the parsing buffer pointer
by changing recovered_lsn and recovered_offset. */
if (type != MLOG_FILE_NAME && only_mlog_file == true) {
only_mlog_file = false;
}
if (only_mlog_file) {
new_recovered_lsn = recv_calc_lsn_on_data_add(
recv_sys->recovered_lsn, len);
mlog_rec_len += len;
recv_sys->recovered_offset += len;
recv_sys->recovered_lsn = new_recovered_lsn;
}
total_len += len;
n_recs++;
ptr += len;
if (type == MLOG_MULTI_REC_END) {
DBUG_PRINT("ib_log",
("scan " LSN_PF
": multi-log end"
" total_len " ULINTPF
" n=" ULINTPF,
recv_sys->recovered_lsn,
total_len, n_recs));
total_len -= mlog_rec_len;
break;
}
DBUG_PRINT("ib_log",
("scan " LSN_PF ": multi-log rec %s"
" len " ULINTPF
" page " ULINTPF ":" ULINTPF,
recv_sys->recovered_lsn,
get_mlog_string(type), len, space, page_no));
}
new_recovered_lsn = recv_calc_lsn_on_data_add(
recv_sys->recovered_lsn, total_len);
if (new_recovered_lsn > recv_sys->scanned_lsn) {
/* The log record filled a log block, and we require
that also the next log block should have been scanned
in */
return(false);
}
/* Add all the records to the hash table */
ptr = recv_sys->buf + recv_sys->recovered_offset;
for (;;) {
old_lsn = recv_sys->recovered_lsn;
/* This will apply MLOG_FILE_ records. We
had to skip them in the first scan, because we
did not know if the mini-transaction was
completely recovered (until MLOG_MULTI_REC_END). */
len = recv_parse_log_rec(
&type, ptr, end_ptr, &space, &page_no,
apply, &body);
if (recv_sys->found_corrupt_log
&& !recv_report_corrupt_log(
ptr, type, space, page_no)) {
return(true);
}
if (recv_sys->found_corrupt_fs) {
return(true);
}
ut_a(len != 0);
ut_a(!(*ptr & MLOG_SINGLE_REC_FLAG));
recv_sys->recovered_offset += len;
recv_sys->recovered_lsn
= recv_calc_lsn_on_data_add(old_lsn, len);
switch (type) {
case MLOG_MULTI_REC_END:
/* Found the end mark for the records */
goto loop;
#ifdef UNIV_LOG_LSN_DEBUG
case MLOG_LSN:
/* Do not add these records to the hash table.
The page number and space id fields are misused
for something else. */
break;
#endif /* UNIV_LOG_LSN_DEBUG */
case MLOG_FILE_NAME:
case MLOG_FILE_DELETE:
case MLOG_FILE_CREATE2:
case MLOG_FILE_RENAME2:
case MLOG_INDEX_LOAD:
case MLOG_TRUNCATE:
/* These were already handled by
recv_parse_log_rec() and
recv_parse_or_apply_log_rec_body(). */
break;
default:
switch (store) {
case STORE_NO:
break;
case STORE_IF_EXISTS:
if (fil_space_get_flags(space)
== ULINT_UNDEFINED) {
break;
}
/* fall through */
case STORE_YES:
recv_add_to_hash_table(
type, space, page_no,
body, ptr + len,
old_lsn,
new_recovered_lsn);
}
}
ptr += len;
}
}
goto loop;
}这里主要逻辑是区分了single_rec(特殊情况,mtr只有一条日志,如初始化页面或者创建页面等情况),常见的是一个MTR里面有多条记录,需要一条条去分析处理。主要是把分析出日志记录recv_parse_log_rec(&type, ptr, end_ptr, &space, &page_no, false, &body);类型,表空间id,页面号,日志内容。把日志记录加入到hash表中,调用recv_add_to_hash_table。
recv_add_to_hash_table(
/*===================*/
mlog_id_t type, /*!< in: log record type */
ulint space, /*!< in: space id */
ulint page_no, /*!< in: page number */
byte* body, /*!< in: log record body */
byte* rec_end, /*!< in: log record end */
lsn_t start_lsn, /*!< in: start lsn of the mtr */
lsn_t end_lsn) /*!< in: end lsn of the mtr */
{
recv_t* recv;
ulint len;
recv_data_t* recv_data;
recv_data_t** prev_field;
recv_addr_t* recv_addr;
ut_ad(type != MLOG_FILE_DELETE);
ut_ad(type != MLOG_FILE_CREATE2);
ut_ad(type != MLOG_FILE_RENAME2);
ut_ad(type != MLOG_FILE_NAME);
ut_ad(type != MLOG_DUMMY_RECORD);
ut_ad(type != MLOG_CHECKPOINT);
ut_ad(type != MLOG_INDEX_LOAD);
ut_ad(type != MLOG_TRUNCATE);
len = rec_end - body;
recv = static_cast(
mem_heap_alloc(recv_sys->heap, sizeof(recv_t)));
recv->type = type;
recv->len = rec_end - body;
recv->start_lsn = start_lsn;
recv->end_lsn = end_lsn;
recv_addr = recv_get_fil_addr_struct(space, page_no);
if (recv_addr == NULL) {
recv_addr = static_cast(
mem_heap_alloc(recv_sys->heap, sizeof(recv_addr_t)));
recv_addr->space = space;
recv_addr->page_no = page_no;
recv_addr->state = RECV_NOT_PROCESSED;
UT_LIST_INIT(recv_addr->rec_list, &recv_t::rec_list);
HASH_INSERT(recv_addr_t, addr_hash, recv_sys->addr_hash,
recv_fold(space, page_no), recv_addr);
recv_sys->n_addrs++;
#if 0
fprintf(stderr, "Inserting log rec for space %lu, page %lu\n",
space, page_no);
#endif
}
UT_LIST_ADD_LAST(recv_addr->rec_list, recv);
prev_field = &(recv->data);
/* Store the log record body in chunks of less than UNIV_PAGE_SIZE:
recv_sys->heap grows into the buffer pool, and bigger chunks could not
be allocated */
while (rec_end > body) {
len = rec_end - body;
if (len > RECV_DATA_BLOCK_SIZE) {
len = RECV_DATA_BLOCK_SIZE;
}
recv_data = static_cast(
mem_heap_alloc(recv_sys->heap,
sizeof(recv_data_t) + len));
*prev_field = recv_data;
memcpy(recv_data + 1, body, len);
prev_field = &(recv_data->next);
body += len;
}
*prev_field = NULL;
} 从上面代码可知,每一条记录都有一个类型为recv_t结构来存储,成员结构及赋值可以从代码看到。其中很重要的一点就是recv_fold(space, page_no),HASH表的键值是space,page_no的组合值。后面的代码是吧日志的body写入结构体的data。就是说INnodb把每一个日志记录分开之后,存储到了以表空间跟页面号为键值的HASH表中,相同的页面肯定是存在一起的,并且同一个页面的日志是以先后顺序挂在在对应的hash节点的,从而保证了redo操作的有序性。
到这里,函数recv_group_scan_log_recs就结束了,redo日志已经获取并解析到hash表,至于apply对应的函数recv_apply_hashed_log_recs我们下面再看。接下来调用函数recv_init_crash_recovery_spaces对涉及的表空间进行初始化处理:
-
首先会打印两条我们非常熟悉的日志信息:
[Note] InnoDB: Database was not shutdown normally! [Note] InnoDB: Starting crash recovery. -
如果
recv_spaces中的表空间未被删除,且ibd文件存在时,则表明这是个普通的文件操作,将该table space加入到fil_system->named_spaces链表上(fil_names_dirty),后续可能会对这些表做redo apply操作; -
对于已经被删除的表空间,我们可以忽略日志apply,将对应表的space id在
recv_sys->addr_hash上的记录项设置为RECV_DISCARDED; -
调用函数
buf_dblwr_process(),该函数会检查所有记录在double write buffer中的page,其对应的数据文件页是否完好,如果损坏了,则直接从dblwr中恢复; -
最后创建一个临时的后台线程,线程函数为
recv_writer_thread,这个线程和page cleaner线程配合使用,它会去通知page cleaner线程去flush崩溃恢复产生的脏页,直到recv_sys中存储的redo记录都被应用完成并彻底释放掉(recv_sys->heap == NULL)
好了,至此recv_recovery_from_checkpoint_start函数结束了,再看trx_sys_init_at_db_start。
四 初始化事务子系统(trx_sys_init_at_db_start)
这里会涉及到读入undo相关的系统页数据,在崩溃恢复状态下,所有的page都要先进行日志apply后,才能被调用者使用,
当实例从崩溃中恢复时,需要将活跃的事务从undo中提取出来,对于ACTIVE状态的事务直接回滚,对于Prepare状态的事务,如果该事务对应的binlog已经记录,则提交,否则回滚事务。
实现的流程也比较简单,首先先做redo (recv_recovery_from_checkpoint_start),undo是受redo 保护的,因此可以从redo中恢复(临时表undo除外,临时表undo是不记录redo的)。
在redo日志应用完成后,初始化完成数据词典子系统(dict_boot),随后开始初始化事务子系统(trx_sys_init_at_db_start),undo 段的初始化即在这一步完成。
在初始化undo段时(trx_sys_init_at_db_start -> trx_rseg_array_init -> ... -> trx_undo_lists_init),会根据每个回滚段page中的slot是否被使用来恢复对应的undo log,读取其状态信息和类型等信息,创建内存结构,并存放到每个回滚段的undo list上。
当初始化完成undo内存对象后,就要据此来恢复崩溃前的事务链表了(trx_lists_init_at_db_start),根据每个回滚段的insert_undo_list来恢复插入操作的事务(trx_resurrect_insert),根据update_undo_list来恢复更新事务(tex_resurrect_update),如果既存在插入又存在更新,则只恢复一个事务对象。另外除了恢复事务对象外,还要恢复表锁及读写事务链表,从而恢复到崩溃之前的事务场景。
当从Undo恢复崩溃前活跃的事务对象后,会去开启一个后台线程来做事务回滚和清理操作(recv_recovery_rollback_active -> trx_rollback_or_clean_all_recovered),对于处于ACTIVE状态的事务直接回滚,对于既不ACTIVE也非PREPARE状态的事务,直接则认为其是提交的,直接释放事务对象。但完成这一步后,理论上事务链表上只存在PREPARE状态的事务。
随后很快我们进入XA Recover阶段,MySQL使用内部XA,即通过Binlog和InnoDB做XA恢复。在初始化完成引擎后,Server层会开始扫描最后一个Binlog文件,搜集其中记录的XID(MYSQL_BIN_LOG::recover),然后和InnoDB层的事务XID做对比。如果XID已经存在于binlog中了,对应的事务需要提交;否则需要回滚事务。
这里源码待补充。
五 应用redo日志(recv_apply_hashed_log_recs)
根据之前搜集到recv_sys->addr_hash中的日志记录,依次将page读入内存,并对每个page进行崩溃恢复操作(recv_recover_page_func):
-
已经被删除的表空间,直接跳过其对应的日志记录;
-
在读入需要恢复的文件页时,会主动尝试采用预读的方式多读点page (
recv_read_in_area),搜集最多连续32个(RECV_READ_AHEAD_AREA)需要做恢复的page no,然后发送异步读请求。 page 读入buffer pool时,会主动做崩溃恢复逻辑; -
只有LSN大于数据页上LSN的日志才会被apply; 忽略被truncate的表的redo日志;
-
在恢复数据页的过程中不产生新的redo 日志;
-
在完成修复page后,需要将脏页加入到buffer pool的flush list上;由于innodb需要保证flush list的有序性,而崩溃恢复过程中修改page的LSN是基于redo 的LSN而不是全局的LSN,无法保证有序性;InnoDB另外维护了一颗红黑树来维持有序性,每次插入到flush list前,查找红黑树找到合适的插入位置,然后加入到flush list上。(
buf_flush_recv_note_modification)
六 完成崩溃恢复(recv_recovery_from_checkpoint_finish)
在完成所有redo日志apply后,基本的崩溃恢复也完成了,此时可以释放资源,等待recv writer线程退出 (崩溃恢复产生的脏页已经被清理掉),释放红黑树,回滚所有数据词典操作产生的非prepare状态的事务 (trx_rollback_or_clean_recovered)
七 无效数据清理及事务回滚:
调用函数recv_recovery_rollback_active完成下述工作:
- 删除临时创建的索引,例如在DDL创建索引时crash时的残留临时索引(
row_merge_drop_temp_indexes()); - 清理InnoDB临时表 (
row_mysql_drop_temp_tables); - 清理全文索引的无效的辅助表(
fts_drop_orphaned_tables()); - 创建后台线程,线程函数为
trx_rollback_or_clean_all_recovered,和在recv_recovery_from_checkpoint_finish中的调用不同,该后台线程会回滚所有不处于prepare状态的事务。
至此InnoDB层的崩溃恢复算是告一段落,只剩下处于prepare状态的事务还有待处理,而这一部分需要和Server层的binlog联合来进行崩溃恢复。
************************************************************************
八 Binlog/InnoDB XA Recover
回到Server层,在初始化完了各个存储引擎后,如果binlog打开了,我们就可以通过binlog来进行XA恢复:
- 首先扫描最后一个binlog文件,找到其中所有的XID事件,并将其中的XID记录到一个hash结构中(
MYSQL_BIN_LOG::recover); - 然后对每个引擎调用接口函数
xarecover_handlerton, 拿到每个事务引擎中处于prepare状态的事务xid,如果这个xid存在于binlog中,则提交;否则回滚事务。
很显然,如果我们弱化配置的持久性(innodb_flush_log_at_trx_commit != 1 或者 sync_binlog != 1), 宕机可能导致两种丢数据的场景:
- 引擎层提交了,但binlog没写入,备库丢事务;
- 引擎层没有prepare,但binlog写入了,主库丢事务。
即使我们将参数设置成innodb_flush_log_at_trx_commit =1 和 sync_binlog = 1,也还会面临这样一种情况:主库crash时还有binlog没传递到备库,如果我们直接提升备库为主库,同样会导致主备不一致,老主库必须根据新主库重做,才能恢复到一致的状态。针对这种场景,我们可以通过开启semisync的方式来解决,一种可行的方案描述如下:
- 设置双1强持久化配置;
- 我们将semisync的超时时间设到极大值,同时使用semisync AFTER_SYNC模式,即用户线程在写入binlog后,引擎层提交前等待备库ACK;
- 基于步骤1的配置,我们可以保证在主库crash时,所有老主库比备库多出来的事务都处于prepare状态;
- 备库完全apply日志后,记下其执行到的relay log对应的位点,然后将备库提升为新主库;
- 将老主库的最后一个binlog进行截断,截断的位点即为步骤3记录的位点;
- 启动老主库,那些已经传递到备库的事务都会提交掉,未传递到备库的binlog都会回滚掉。
知识点很多,需要再学习
参考:
http://mysql.taobao.org/monthly/2015/06/01/
http://mysql.taobao.org/monthly/2015/04/01/