【论文翻译】Orthographic Feature Transform for Monocular 3D Object Detection
标题:《Orthographic Feature Transform for Monocular 3D Object Detection》
作者:Thomas Roddick, Alex Kendall ,Roberto Cipolla
机构:University of Cambridge
时间:2018.11.20
Abstract
这项工作中,作者认为在三维世界中的推理能力是3D目标检测任务的一个基本要素。为此,作者引入了正交特征变换,通过将基于图像的特征映射到正交3D空间,实现了对图像域的转义。这使得我们能够在一个尺度一致且对象之间的距离有意义的域中对场景的空间配置进行整体推理。我们将该变换应用于端到端的深度学习架构中的一部分,并在KITTI 3D数据集上实现了SOTA的性能。
1.Introduction
作者提出了新颖的3D目标检测算法,该算法采用单目RGB图像作为输入,产生高质量的3D边界框,在KITTI benchmark上取得了SOTA的性能。
透视投影是指单个物体的尺度随距离相机的远近而发生较大的变化;它的外观会随着视角的不同而发生巨大的变化;而且在3D世界中的距离无法直接推断得到。一种常用的距离表述方式是采用正交的鸟视图(俯视视角),这在基于LiDAR的方法中较为常见。在这种表述下,尺度是均匀的,外观在很大程度上是独立于视角的;物体之间的距离是有意义的。作者的主要观点是:尽可能在这个正交空间中进行推理,而不是直接在基于像素的图像域中进行。这种观点对于作者提出系统的成功至关重要。
作者提出正交特征变换(OFT):一种可微变换,它将从透视图RGB图像中提取的一组特征映射到正交的鸟瞰特征图中。
作者还建立了一个内部表述,能够确定图像中的哪些特征与鸟瞰图上的每个位置相关。为了合理地确定场景的三维结构,我们使用了Topdown的深度卷积神经网络。
文章主要贡献:
- 引入一种基于透视图像的特征映射为鸟瞰图视角的正交特征变换(OFT),该方法有效利用了图像的完整性;
- 构建了DL结构用于预测单目RGB图像目标的3D框;
- 强调3D推理在目标检测任务中的重要性;
2.Related Work
2D object detection
主要可分为 single stage detectors:YOLO、SSD、RetinaNet等;two-stage detectors:Faster R-CNN、 FPN 等;
到目前为止,绝大多数的3D目标检测方法都采用了后一种方法,部分原因是三维空间中固定大小区域到图像空间中可变大小区域的映射比较困难。作者通过OFT转换克服了这一限制,允许我们利用one-stage结构的速度和精度优势。
3D object detection from LiDAR
3D目标检测对自动驾驶具有重要意义,已经有很多基于LiDAR的方法都取得了较大成功。大多数变化来自激光雷达点云的编码方式。
3D object detection from images
由于缺乏绝对深度信息,从图像中获取3D边界框是个具有挑战性的问题。许多方法都是从使用上述标准的检测器中提取的2D框开始,在此基础上,它们要么直接对每个区域回归出3D姿态参数,要么将3D模板匹配到图像;……
以上所有工作的一个主要限制是,每个区域的proposal或者bbox都是独立处理的,排除了任何关于场景3D配置的联合推理。我们的方法类似于【3】的特征聚合步骤,但是对生成的proposal应用了一个二级卷积网络,同时保留了它们的空间配置。
Integral images
自从Viola和Jones开创性的工作中引入积分图像以来,积分图像(Integral image)就从根本上与目标检测相关联。它们在包括AVOD,MV3D,Mono3D,3DOP在内的许多现代3D目标检测方法中形成了重要的组成部分。
3. 3D Object Detection Architecture
本节作者描述了单目图像中提取3D边界框的完整方法。图3显示了系统的整体概述。算法主要由5个部分构成:
- 前端由ResNet特征提取器来提取输入图像的多尺度特征图;
- 一种正交特征变换,它将每个尺度上基于图像的特征转换为鸟瞰图的正交表述法;
- 一种由一系列ResNet残差单元组成的自上而下的网络,它以不受图像中观察到的透视效果影响的方式来处理鸟瞰视角的特征图;
- 一组输出头,分别生成每个对象类和每个类别在地平面的位置,置信度得分,位置偏移量,尺度偏移量和方向向量;
- 非极大值抑制和解码阶段,该阶段识别出峰值,并生成离散边界框预测;

3.1.Featureextraction
框架的第一个元素就是卷积特征提取器,从原始输入图像生成多级的多尺度2D特征图。这些特征编码了图像中低层结构的信息,这些信息构成了自上而下网络的基本组件,以构建场景的隐式3D表示。前端网络还负责根据图像特征的大小推断深度信息,因为后续阶段的结构目标是消除尺度的变化。
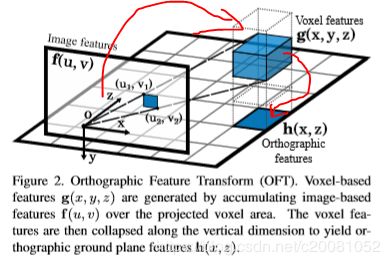
3.2.Orthographic feature transform
为了在没有透视效果的情况下对3D世界进行推理,首先必须将图像空间中提取的特征图映射到世界空间中的正交特征图中,我们称之为正交特征变换(OFT)。
OFT的目标是用前端特征提取器提取的基于图像的特征图![]() 中的相关n维特征填充3D体素特征图
中的相关n维特征填充3D体素特征图![]() . 立体像素特征图定义在一个均匀间隔的3D网格
. 立体像素特征图定义在一个均匀间隔的3D网格![]() , 它与地平面距离是固定的,在相机坐标
, 它与地平面距离是固定的,在相机坐标![]() 以下,维度为W,H,D,体素大小为 r .对于给定的体素网格位置
以下,维度为W,H,D,体素大小为 r .对于给定的体素网格位置![]()
![]() , 通过对对应与体素的2D投影的图像特征图
, 通过对对应与体素的2D投影的图像特征图![]() 的区域进行特征累加,得到体素特征
的区域进行特征累加,得到体素特征![]() . 一般情况下,每一个体素(大小为r 的立方体)都会投射到像平面上的六边形区域,作者用一个矩形包围框来近似它。其中左上角
. 一般情况下,每一个体素(大小为r 的立方体)都会投射到像平面上的六边形区域,作者用一个矩形包围框来近似它。其中左上角![]() 和右下角
和右下角![]() 的坐标如下:
的坐标如下:
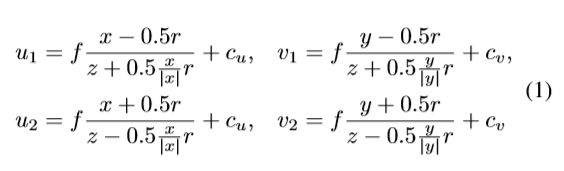
其中, f 是相机焦距,而![]() 是图像坐标系原点。
是图像坐标系原点。
然后,可以通过在图像特征图f 中投影的体素包围框(上面说的近似矩形包围框)上进行平均池化,将该特征值分配到体素特征图 g 中的适当位置。
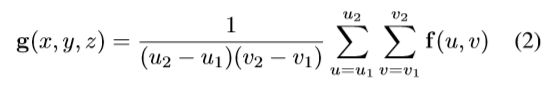
所得到的体素特征图 g 已经提供了一个不受透视投影影响的场景表示。然而,在大型体素网格上运行深度神经网络通常是非常占内存的。鉴于我们感兴趣的主要应用如自动驾驶中的大多数目标是固定在2D地平面上,我们可以通过分解使问题更容易处理,我们将3D体素特征图分解到另一个2D表示图上,我们称为正交特征图 h(x,z). 正交特征图是通过将学习得到的权重矩阵![]() 沿着垂直轴与体素特征图相乘后求和得到:
沿着垂直轴与体素特征图相乘后求和得到:
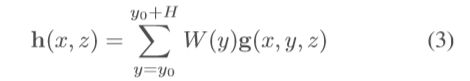
在转换到最终正交特征图之前的中间体素表述的优点是保留了场景的垂直配置信息,这对于随后的任务,例如估计目标边界框的高度和垂直位置来说是至关重要的。
3.2.1 Fast average pooling with integral images
一个典型的体素网格会生成约150k个边界框,这个远远多于Faster R-CNN的~2k个ROI。作者利用一个基于积分图的快速平均池化操作。积分图 F, 由输入特征图 f 用如下递归方式得到:
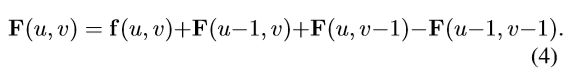
给定积分特征图 F, 由(u1,v1)和(u2,v2)定义的边界框,其对应的输出特征为 g(x,y,z) :
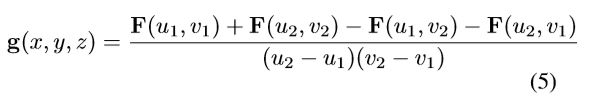
3.3.Topdown network
3D推理组件由一个子网络构成,称之为自上而下网络。这是一个简单的卷积网络,使用ResNet风格的skip连接,它在之前描述的OFT阶段生成的2D特征图 h 上运行。距离相机较远和较近的特征图得到完全相同的处理,尽管对应的图像区域要小得多。
3.4.Confidence map prediction
置信度图S(x,z)是个平滑函数,它表示在(x,y0,z)位置是否存在以该位置为中心带边界框的目标存在可能性。其中y0 表示在相机下方距离地面的距离。给定N个真实目标的真实边界框中心 ![]() , i=1,...,N,我们计算GT置信度图为一个平滑的高斯区域,其以目标中心为中心,宽度为
, i=1,...,N,我们计算GT置信度图为一个平滑的高斯区域,其以目标中心为中心,宽度为![]() ,在位置(x,z)置信度公式为:
,在位置(x,z)置信度公式为:
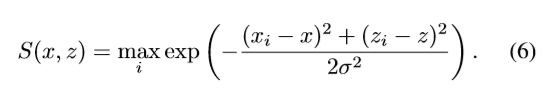
网络置信度图预测分支头使用 L1 loss来训练的,回归到正交网格 H上每个位置的GT 置信度上。由于正样本(高置信度的位置)要远远少于负样本,为了克服该问题,作者引入常量因子0.01 ,将其乘以负样本位置(S(x,z)得分<0.05的位置)这样减少大量负样本的影响。
3.5.Localization and bounding box estimation
上面的置信度图将每个目标的位置粗略近似编码为置信度得分中的一个峰值,从而给出一个精确到特征图分辨率r 的位置估计。为了更加精确的定位每个对象,我们在对应的GT 目标pi 的中心追加了一个额外的网络输出头,该输出头可以预测距离地面网格单元位置(x,y0,z)的相对偏移![]() :
:
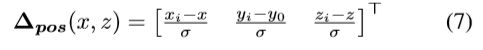
除了定位到每个目标,我们还必须确定每个边界框的大小和方向。文章将进一步介绍连个网络输出,一个是尺寸输出分支头,预测GT目标 i 的尺寸![]() 和给定类别所有目标的平均尺寸
和给定类别所有目标的平均尺寸![]() 之间的对数尺度偏移
之间的对数尺度偏移![]() :
:
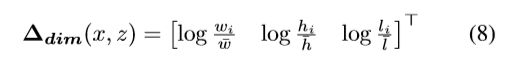
另一个输出是方向输出分支头,预测目标绕y轴的方向角![]() 的sine和cosine值:
的sine和cosine值:
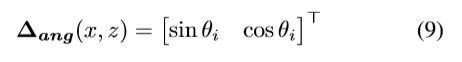
注意,因为我们在正交鸟瞰图空间,我们能直接预测绕y轴的方向角θ,不像其他人的工作【23】需要考虑角度和相对视角的问题预测所谓的观察角度α的影响。文中的位置偏移![]() ,尺寸偏移
,尺寸偏移![]() , 方向向量
, 方向向量![]() 都是用 L1 loss训练的。
都是用 L1 loss训练的。
3.6.Non-maximum suppression
与其他目标检测算法类似,使用非极大值抑制(NMS)阶段来获得最终的离散的目标预测集。在传统的目标检测设置中,这个步骤很花费时间,因为它需要O(![]() )次的边界框重叠计算。这是由于成对的3D框不一定是轴对称的,这使得重叠计算比2D情况更加困难,幸运的是,使用置信度图代替锚点框分类的一个好处是,我们可以应用更传统的图像处理意义上的NMS,即在二维置信度图S 上搜索局部极大值。此处,正交投影鸟视图再次证明了它的价值:在三维世界中,两个物体不能占据相同体积,这意味着置信度图上的峰值是分离的。
)次的边界框重叠计算。这是由于成对的3D框不一定是轴对称的,这使得重叠计算比2D情况更加困难,幸运的是,使用置信度图代替锚点框分类的一个好处是,我们可以应用更传统的图像处理意义上的NMS,即在二维置信度图S 上搜索局部极大值。此处,正交投影鸟视图再次证明了它的价值:在三维世界中,两个物体不能占据相同体积,这意味着置信度图上的峰值是分离的。
为了减轻噪音对预测的影响,我们首先用高斯核(其宽度为![]() )来平滑置信度图。在平滑后的置信度图上位置(xi,zi)的值
)来平滑置信度图。在平滑后的置信度图上位置(xi,zi)的值![]() 被认为是最大的,如果它满足下式:
被认为是最大的,如果它满足下式:
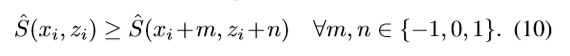
在产生的峰值位置中,任何小于给定阈值 t 的置信度![]() 都将被排除。这导致最后的预测对象实例,其边界框中心
都将被排除。这导致最后的预测对象实例,其边界框中心![]() ,尺寸
,尺寸![]() ,以及方向
,以及方向![]() ,是通过反向关系方差7,8,9来得到。
,是通过反向关系方差7,8,9来得到。
4.Experiments
4.1.Experimental setup
Architecture
前端特征提取器使用的是没有bottleneck层的ResNet-18. 作者有意选择前端网络相对较浅,因为希望尽可能地强调模型的三维推理组件。我们在最后3个向下采样层之前提取特征,得到一组特征图{![]() },其尺度为原始输入分辨率的1/8, 1/16, 1/32.用卷积核1x1来将特征图变化到特定的256大小,然后用正交特征变换产生正交特征图{
},其尺度为原始输入分辨率的1/8, 1/16, 1/32.用卷积核1x1来将特征图变化到特定的256大小,然后用正交特征变换产生正交特征图{![]() }. 文章中使用体素网格尺寸为80mx4mx80m,这足以包含KITTI中所有带注释的实例,并将网格分辨率r 设置为0.5m。对于自上而下网络,我们使用一个简单的16层ResNet,没有任何的下采样和bottleneck层。每个输出头由一个1x1卷积组成。在整个模型中,用group normalization来替代 batch normalization,因为前者被证明在小batch数据上表现更好。
}. 文章中使用体素网格尺寸为80mx4mx80m,这足以包含KITTI中所有带注释的实例,并将网格分辨率r 设置为0.5m。对于自上而下网络,我们使用一个简单的16层ResNet,没有任何的下采样和bottleneck层。每个输出头由一个1x1卷积组成。在整个模型中,用group normalization来替代 batch normalization,因为前者被证明在小batch数据上表现更好。
Dataset
训练以及验证用的是KITTI 3D目标检测benchmark 数据集。训练集是3712张,验证集是3769张,遵循Chen et al.【3】的分法。
Data augmentation
由于我们的方法依赖从像平面到地平面的固定映射吗,我们发现大量的数据增强对于网络的鲁棒性学习是必不可少的。我们采用三种广泛使用的方法:随机裁剪、缩放和水平翻转,相应地调整相机标定参数 ![]() 和
和 ![]() 来反应这些扰动。
来反应这些扰动。
Training procedure
使用SGD对600个epoch进行训练,batch size为8,动量为0.9, 学习率为10^-7, 遵循【21】,对loss进行求和而不是平均,这避免了将梯度偏向于对象实例很少的示例。利用一种简单的等权重策略将不同输出头的损失函数组合起来。
4.2.Comparison to state-of-the-art
在KITTI 3D目标检测benchmark上进行评估。3D边界框检测任务要求每个预测的3D边界框应与相应的GT框至少70%的重合度(汽车case)以及50%的重合度(行人和自行车case)。与此同时,鸟瞰图检测任务稍微宽松些,要求预测在2D鸟瞰图投影与GT框在地面的投影达到相同的重合度(即上面针对3D重合度,此处针对投影后的2D重合度,数据还是70%和50%),本文将评估集中在car上。结果见表一
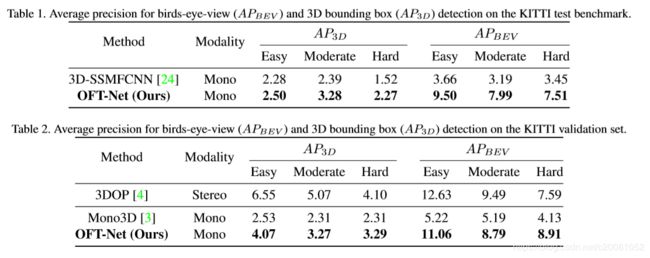
从表一和表二可以看出,我们的方法能够在所有可比较的(即单目)方法中,在所有任务和所有难度标准上都有相当大的优势。这种改进在较难评估类中特别明显,其中包括严重遮挡,截断或者原理相机的实例。表2还显示,我们的方法与Chen et al.(2015)【4】的立体视觉方法具有竞争力,达到了接近或在某种情况下优于他们的3DOP系统的性能。尽管与【4】不同,我们的方法没有获取场景深度的的任何显示知识。
4.3.Qualitative results
Comparison to Mono3D
我们在图4中对我们的方法和Mono3D 【3】生成的预测进行了定性比较。指的注意的是,作者系统能可靠地探测到距离相机相当远的物体。这是2D和3D检测中常见的失效情况,而我们的系统正确识别的许多失效情况都被Mono3D忽略了。
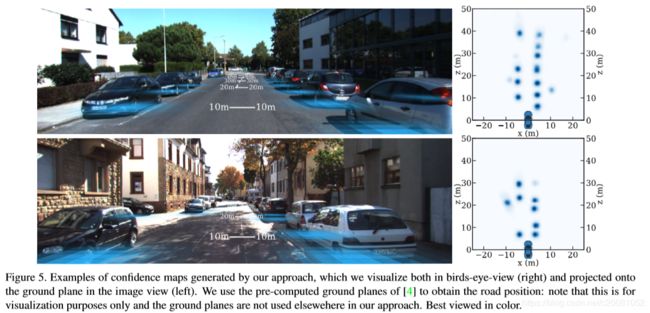
Ground plane confidence maps
本文方法的一个独特特点是,主要在正交鸟瞰图的特征空间,为了说明这一点,图5显示了自上而下视图和投影到地平面图像中的预测置信度图S(x,z)的示例。可以看出,预测的置信度图在每个对象中心都有很好的局部特性。
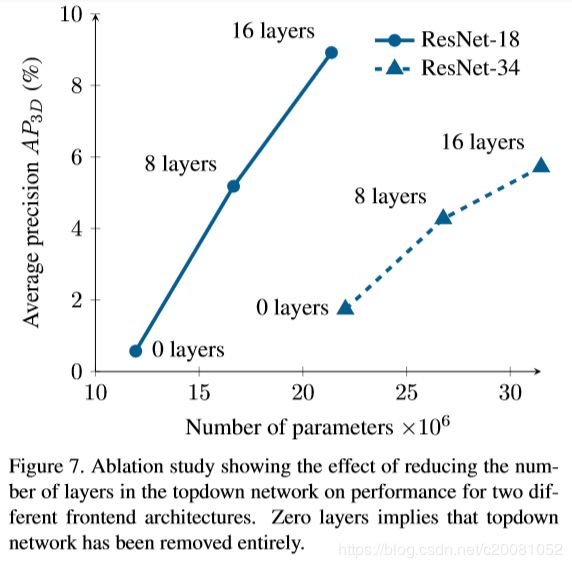
4.4.Ablation study
作者用消融研究来验证自上而下网络中移除层会影响网络性能。并且研究发现,用较浅的特征提取层接较大的自上而下网络要比较大特征提取层而没有自上而下网络这种情况性能更好,尽管两种情况参数量相当,见图7;