三、初探搜索
基本概念
映射(Mapping) 数据在每个字段中的解释说明
分析(Analysis) 全文是如何处理的可以被搜索的
领域特定语言查询(Query DSL) Elasticsearch使用的灵活的、强大的查询语言
空搜索:
最基本的搜索API表单是空搜索(empty search),它没有指定任何的查询条件,只返回集群索引中的所有文档:
GET /_search
//->返回
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 9,
"successful": 9,
"failed": 0
},
"hits": {
"total": 12,
"max_score": 1,
"hits": [
{
"_index": ".kibana",
"_type": "index-pattern",
"_id": "mytest1",
"_score": 1,
"_source": {
"title": "mytest1",
"notExpandable": true,
"fields": "..."
}
},
...
,{
"_index": "website",
"_type": "log",
"_id": "AV4YlJRcSI2kIEo0OHJ1",
"_score": 1,
"_source": {
"event": "User logged in"
}
}
]
}
}
hits: 响应中最重要的部分是 hits ,它包含了 total 字段来表示匹配到的文档总数, hits 数组还包含了匹配到的前10条数据。
took: 告诉我们整个搜索请求花费的毫秒数。
shards:_shards 节点告诉我们参与查询的分片数( total 字段),有多少是成功的( successful 字段),有多少的是失败的( failed 字段)
timeout:time_out 值告诉我们查询超时与否。
// Elasticsearch将返回在请求超时前收集到的结果
GET /_search?timeout=10ms
多索引和多类别:
//在所有索引的所有类型中搜索
/_search
//在索引 gb 的所有类型中搜索
/gb/_search
//在索引 gb 和 us 的所有类型中搜索
/gb,us/_search
//在以 g 或 u 开头的索引的所有类型中搜索
/g*,u*/_search
//在索引 gb 的类型 user 中搜索
/gb/user/_search
//在索引 gb 和 us 的类型为 user 和 tweet 中搜索
/gb,us/user,tweet/_search
//在所有索引的 user 和 tweet 中搜索 search types user and tweet in all indices
/_all/user,tweet/_search
分页
和SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size : 结果数,默认 10
from : 跳过开始的结果数,默认 0
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10简易搜索
search API有两种表单
1. 一种是“简易版”的查询字符串(query string)将所有参数通过查询字符串定义
2. 使用JSON完整的表示请求体(request body),这种富搜索语言叫做结构化查询语句(DSL)
GET /_all/tweet/_search?q=tweet:elasticsearch
//使用百分号(查询字符串语法)
/*
"+" 前缀表示语句匹配条件必须被满足。类似的 "-" 前缀表示条件必须不被满足。所有条件如果没有 + 或 - 表示是可选的——匹配越多,相关的文档就越多
*/
GET /_search?q=%2Bname%3Ajohn+%2Btweet%3Amary
//_all 字段,返回包含 "mary" 字符的所有文档的简单搜索:
GET /_search?q=mary
GET /_search?q=%2Bname%3A(mary+john)+%2Bdate%3A%3E2014-09-10+%2B(aggregations+geo)
映射和分析
确切值(Exact values) VS 全文文本本(Full text)
Elasticsearch中的数据可以大致分为两种类型:确切值 及 全文文本。
1. 确切值是确定的,正如它的名字一样。比如一个date或用户ID,也可以包含更多的字符串比如username或email地址。确切值 "Foo" 和 "foo" 就并不相同。确切值 2014 和 2014-09-15 也不相同。
2. 全文文本,从另一个角度来说是文本化的数据(常常以人类的语言书写),比如一篇推文(Twitter的文章)或邮件正文
Elasticsearch首先对文本分析(analyzes),然后使用结果建立一个倒排索引。
倒排索引
Elasticsearch使用一种叫做倒排索引(inverted index)的结构来做快速的全文搜索倒排索引
由在文档中出现的唯一的单词列表,以及对于每个单词在文档中的位置组成。
分析和分析器
分析(analysis)是这样一个过程:
1. 首先,标记化一个文本块为适用于倒排索引单独的词(term)
2. 然后标准化这些词为标准形式,提高它们的“可搜索性”或“查全率”
这个工作是分析器(analyzer)完成的。一个分析器(analyzer)只是一个包装用于将三个功能放到一个包里:
1. 字符过滤器。首先字符串经过字符过滤器(character filter),它们的工作是在标记化前处理字符串。
2. 分词器。分词器(tokenizer)被标记化成独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开
3. 标记过滤。每个词都通过所有标记过滤(token filters),它可以修改词去掉词(例如停用词像 "a" 、 "and" 、 "the" 等等),或者增加词(例如同义词像 "jump" 和 "leap" )
映射
查看映射类型
GET /_mapping
GET /blogs/_mapping
GET /blogs/category/_mapping
//字段的映射(叫做属性(properties))
{
"blogs": {
"mappings": {
"category": {
"properties": {
"category_id": {
"type": "long"
},
"categroy__name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
//对于 string 字段,两个最重要的映射参数是 index 和 analyer 。
/*
1.index:
analyzed, 首先分析这个字符串,然后索引。换言之,以全文形式索引此字段。
not_analyzed, 索引这个字段,使之可以被搜索,但是索引内容和指定值一样。不分析此字段。
no, 不索引这个字段。这个字段不能为搜索到。
string 类型字段默认值是 analyzed 。如果我们想映射字段为确切值,我们需要设置它为 not_analyzed
2.analyer
对于 analyzed 类型的字符串字段,使用 analyzer 参数来指定哪一种分析器将在搜索和索引
的时候使用。默认的,Elasticsearch使用 standard 分析器,,但是你可以通过指定一个内建的分析器来更改它
*/
更新映射
PUT /gb
{
"mappings": {
"tweet": {
"properties": {
"tweet": {
"type": "string",
"analyzer": "english"
},
"date": {
"type": "date"
},
"name": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}测试映射
GET /gb/_analyze?field=tweet&text=Black-cats
GET /gb/_analyze?field=tag&text=Black-cats请求体查询
GET /_search
{
"from": 30,
"size": 10
}
/*Elasticsearch的作者们倾向于使用 GET 提交查询请求,因为他们觉得这个词相比 POST 来说,
能更好的描述这种行为。*/
POST /_search
{
"from": 30,
"size": 10
}
GET /_search
{
"query": YOUR_QUERY_HERE
}
//空查询 - {} - 在功能上等同于使用 match_all 查询子句
GET /_search
{
"query": {
"match_all": {}
}
}
查询子句
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
//或指向一个指定的字段:
Elasticsearch权威指南(中文版)
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
//例如:
GET /_search
{
"query": {
"match": {
"tweet": "elasticsearch"
}
}
}
合并多子句
合并简单的子句为一个复杂的查询语句
- 叶子子句(leaf clauses)(比如 match 子句)用以在将查询字符串与一个字段(或多字段)进行比较
- 复合子句(compound)用以合并其他的子句。例如, bool 子句允许你合并其他的合法子句, must , must_not 或者 should ,如果可能的话:
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }}
}
}复合子句能合并 任意其他查询子句,包括其他的复合子句。 这就意味着复合子句可以相互嵌套,从而实现非常复杂的逻辑。
查询与过滤
原则上来说,使用查询语句做全文本搜索或其他需要进行相关性评分的时候,剩下的全部用过滤语句
过滤语句:
//term 过滤
/*term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型):*/
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}
//terms 过滤
/*terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个
值,那么文档需要一起去做匹配:*/
{
"terms": {
"tag": [ "search", "full_text", "nosql" ]
}
}
//range 过滤
/*range 过滤允许我们按照指定范围查找一批数据:
gt , 大于
gte , 大于等于
lt , 小于
lte , 小于等于
*/
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
//exists 和 missing
/*exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,SQL语句中的 IS_NULL 条件*/
{
"exists": {
"field": "title"
}
}
//bool 过滤
/*
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑
must :: 多个查询条件的完全匹配,相当于 and
must_not :: 多个查询条件的相反匹配,相当于 not
should :: 至少有一个查询条件匹配, 相当于 or
*/
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}
//bool 查询
/*
bool 查询与 bool 过滤相似,用于合并多个查询子句。不同的是, bool 过滤可以直接给
出是否匹配成功, 而 bool 查询要计算每一个查询子句的 _score (相关性分值)。
如果 bool 查询下没有 must 子句,那至少应该有一个 should 子句。但是 如果
有 must 子句,那么没有 should 子句也可以进行查询。
*/
//match_all 查询.使用 match_all 可以查询到所有文档,是没有查询条件下的默认语句。
{
"match_all": {}
}
//match 查询
/*match 查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析 match 一下查
询字符:
*/
{
"match": {
"tweet": "About Search"
}
}
//multi_match 查询
/*multi_match 查询允许你做 match 查询的基础上同时搜索多个字段:*/
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
查询与过滤条件的合并
查询语句和过滤语句可以放在各自的上下文中。
{
"match": {
"email": "business opportunity"
}
}
+
{
"term": {
"folder": "inbox"
}
}
=
//search API中只能包含 query 语句,所以我们需要用 filtered 来同时包含 "query" 和"filter" 子句:
{
"filtered": {
"query": { "match": { "email": "business opportunity" }},
"filter": { "term": { "folder": "inbox" }}
}
}
//在外层再加入 query 的上下文关系:(5.0以前)
GET /_search
{
"query": {
"filtered": {
"query": { "match": { "email": "business opportunity" }},
"filter": { "term": { "folder": "inbox" }}
}
}
}
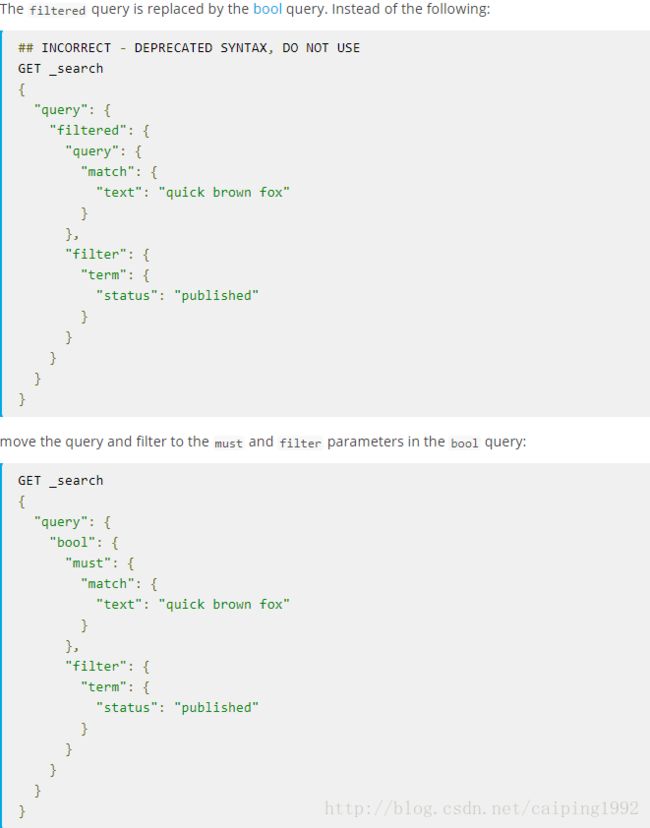
//5.0以后
GET _search
{
"query": {
"bool": {
"must": {
"match": { "text": "quick brown fox" }
},
"filter": {
"term": { "status": "published" }
}
}
}
}
单条过滤语句
GET /_search
{
"query": {
"bool": {
"filter": { "term": { "folder": "inbox" }}
}
}
}
查询语句中的过滤
验证查询
GET /gb/tweet/_validate/query
{
"query": {
"tweet": {
"match": "really powerful"
}
}
}
//->返回
{
"valid": false
}
//理解错误信息.想知道语句非法的具体错误信息,需要加上 explain 参数:
GET /gb/tweet/_validate/query?explain
{
"query": {
"tweet": {
"match": "really powerful"
}
}
//->返回
{
"valid": false,
"error": "org.elasticsearch.common.ParsingException: no [query] registered for [tweet]"
}
理解查询语句
//如果是合法语句的话,使用 explain 参数可以返回一个带有查询语句的可阅读描述
{
"query": {
"bool": {
"should": {
"match": {
"tweet": "manage text search"
}
},
"filter": {
"term": {
"user_id": 2
}
}
}
},
"sort": [
{
"date": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
字符串参数排序
为多值字段排序
为多值字段排序
多值字段字符串排序
指同一个字段在ES索引中可以有多个含义,即可使用多个分析器(analyser)进行分词与排序,也可以不添加分析器,保留原值。
文档是如何被匹配到的
当 explain 选项加到某一文档上时,它会告诉你为何这个文档会被匹配,以及一个文档为何没有被匹配。
请求路径为 /index/type/id/_explain
GET /us/tweet/12/_explain
{
"query": {
"bool": {
"filter": {
"term": {
"user_id": 2
}
},
"should": {
"match": {
"tweet": "honeymoon"
}
}
}
}
}官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html