目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
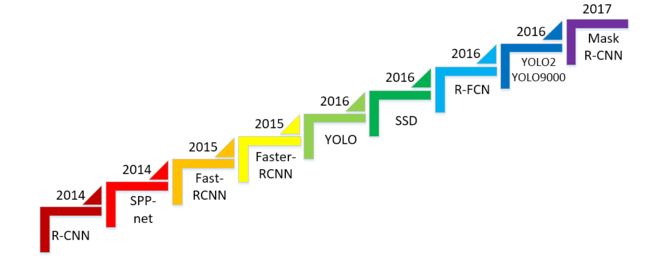
目标检测系列:
目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
目标检测(object detection)系列(二) SPP-Net:让卷积计算可以共享
目标检测(object detection)系列(三) Fast R-CNN:end-to-end的愉快训练
目标检测(object detection)系列(四) Faster R-CNN:有RPN的Fast R-CNN
目标检测(object detection)系列(五) YOLO:目标检测的另一种打开方式
目标检测(object detection)系列(六) SSD:兼顾效率和准确性
目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN
目标检测(object detection)系列(八) YOLOv2:更好,更快,更强
目标检测(object detection)系列(九) YOLOv3:取百家所长成一家之言
目标检测(object detection)系列(十) FPN:用特征金字塔引入多尺度
目标检测(object detection)系列(十一) RetinaNet:one-stage检测器巅峰之作
目标检测(object detection)系列(十二) CornerNet:anchor free的开端
目标检测扩展系列:
目标检测(object detection)扩展系列(一) Selective Search:选择性搜索算法
目标检测(object detection)扩展系列(二) OHEM:在线难例挖掘
简介 :CNN目标检测的开山之作
R-CNN提出于2014年,应当算是卷积神经网络在目标检测任务中的开山之作了,当然同年间还有一个overfeat算法,在这里暂不讨论。R-CNN的论文是《Rich feature hierarchies for accurate oject detection and semantic segmentation》,在之后的几年中,目标检测任务的CNN模型也越来越多,实时性与准确率也越来越好,但是最为经典的模型还是很值得学习的。
R-CNN原理
设计理念
对于R-CNN模型,它其实是将4个应用于不同任务的已有的算法很好的结合了起来,最终在目标检测任务中取得了不错的效果,这种结合更像是偏向于工程的方法,而不是在算法上的一种突破,当然在后续的Fast-RCNN与Faster-RCNN中模型逐步完善并整合成为一个模型,但是在R-CNN中是没有的。
所以R-CNN由4个部分构成,它们分别是:
- 区域建议算法(ss)
- 特征提取算法(AlexNet)
- 线性分类器(线性SVM)
- 边界框修正回归模型(Bounding box)
区域建议算法
首先是区域建议(Region Proposal)算法,这个东西在CNN之前就已经有了,而且算法不止一种,ss(selective search)算法是比较著名的一个,此外还有EdgeBox,MSER,MCG等等算法,CS231n中对这几种算法做了一个简单的介绍,感兴趣的话可以移步到CS231n第16课时。
那么ss算法在R-CNN中有什么用呢?这要从目标检测任务开始谈起,在一副图像中要实现目标检测任务,一种最简单的思路是如果建立滑动窗,对每次滑动窗提取出来的图像做分类,如果分类结果恰好是目标的话,就实现了检测啦,**目标的属性由分类器给,目标的位置由滑动窗给。**但是考虑到一次滑动遍历产生的子图像数量就不小了,同时还有不同步长和窗口尺寸的情况,此时产生的待分类图像是非常多的,这种方式显然没什么实用价值,于是就有了ss算法,一种根据图像自身信息产生推荐区域的算法,它大概会产生1000-2000个潜在目标区域,照比滑动遍历的方式,这个数量已经减少了很多了。
特征提取算法
这里的特征提取算法其实就是卷积神经网络,R-CNN中使用的是AlexNet,但是作者(Ross)并没有把AlexNet当做分类器来使用,而是只用了网络的特征层做ss算法输出的图像的特征提取工作,如果想要了解AlexNet的话,可以参考从AlexNet理解卷积神经网络的一般结构,然后第7层特征给了SVM分类器,第五次特征给了Bounding Box回归模型。
线性分类器
R-CNN使用了线性SVM分类器,这个没啥好说的,机器学习中很牛的算法了,如果想要了解请移步如何理解支持向量机的最大分类间隔,需要说明的是,目标检测任务是有分类的功能的,比如一个任务是检测猫和狗,那么除了要框出猫和狗的位置之外,也需要判断是猫还是狗,这也是SVM在R-CNN中的作用。所以待检测物体有几类,那么就应该有几个二分类的SVM分类器,在上面的例子中,就需要两个二分类分类器了,分别是“猫-非猫”模型和“狗-非狗”模型,在R-CNN中,分类器有20个,它的输入特征是AlexNet提取到的fc7层特征。
边界框修正回归模型
Bounding box也是个古老的话题了,计算机视觉常见任务中,在分类与检测之间还有一个定位任务,在一副图像中只有一个目标,然后把这个目标框出来,用到的就是Bounding box回归模型。
在R-CNN中,Bounding box的作用是修正ss推荐的区域的边界,输入的特征是AlexNet的第五层特征,与SVM分类器一样,它也是每一个类别都有一个模型,一共20个。
在上面,我们分别介绍了R-CNN的四个部分和他们的作用,可以看到,其实都是之前的东西,但是R-CNN的成功之处在于找到一种训练与测试的方法,把这四个部分结合了起来,而准确率大幅提升的原因在于CNN的引入。我们参考下HOG+SVM做行人检测的方法,HOG就是一种手工特征,而在R-CNN中换成了CNN提取特征。
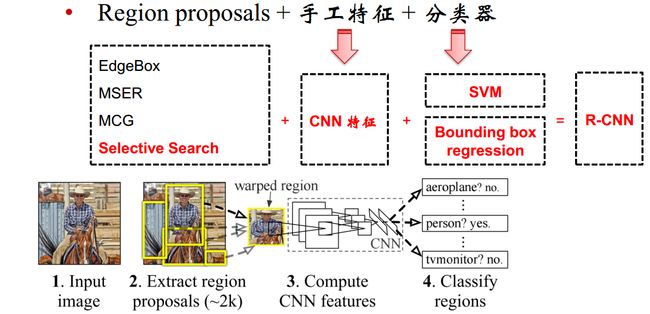
所以个人的看法是理解R-CNN的关键不在于上面提到的四个算法本身,而是它们在R-CNN到底是怎么训练和测试的!
R-CNN的训练
R-CNN训练了CNN,SVM与Bounding box三个模型,因为ss算法用不着训练,哈哈~~
ss在生成了1000-2000个推荐区域之后,就和训练任务没啥关系了,训练样本是由ss区域生成出来的子图构建起来的。
而且三个部分的训练时独立的,并没有整合在一起。
1.训练CNN
CNN是在ImageNet上pre-train的AlexNet模型,在R-CNN中进行fine-tune,fine-tune的过程是将AlexNet的Softmax改为任务需要的类别数,然后还是当做一个分类模型来训练,训练样本的构建使用ss生成的子图,当这些图与实际样本的框(Ground-truth)的IoU大于等于0.5时,认为是某一个类的正样本,这样的类一共有20个;IoU小于0.5时,认为是负样本。然后就可以AlexNet做pre-train了,pre-train之后AlexNet的Softmax层就被扔掉了,只剩下训练后的参数,这套参数就用来做特征提取。
2.训练SVM
之前提到了,SVM的输入特征是AlexNet fc7的输出,然后SVM做二分类,一个有20个SVM模型。那么对于其中某一个分类器来说,它的正样本是所有Ground-truth区域经过AlexNet后输出的特征,负样本是与Ground-truth区域重合IoU小于0.3的区域经过AlexNet后输出的特征,特征和标签确定了,就可以训练SVM了。
3.训练Bounding box回归模型
Bounding box回归模型也是20个,还是拿其中一个来说,它的输入是AlexNet conv5的特征,注意这里的20指的是类的个数,但是对一个Bounding box来说,它有4套参数,因为一个Bounding box回归模型分别对4个数做回归,这4个数是表征边界框的四个值,模型的损失函数如下:
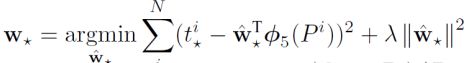
其中i是样本个数,*就是4个数,他们分别是x,y,w,h,其中(x,y)是中心位置,(w,h)是宽和高;P是ss给出来的区域,它由Px,Py,Pw,Ph四个数决定,这个区域经过AlexNet后再第五层输出特征,然后在特征每一个维度前都训练一个参数w,一组特征就有一组w,随4组做回归就有4组w;最后一个数就是t,它同样有4个数tx,ty,tw,th,是这样计算出来的:
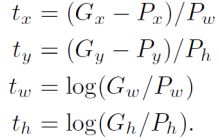
而G就是经过修正后的边界框,它还是4个数Gx,Gy,Gw,Gh。通过上面的公式可以看到,t是边界框的偏差。
最后就是到底什么样的ss区域能够作为输入,在这里是IoU大于0.6的。
用一句话总结Bounding box回归模型就是:对于某一个类的回归模型而言,用IoU>0.6的ss区域经过卷积后作为输入特征,用同一组特征分别训练4组权值与之对应,对边界框四个属性值分别做回归。
经过上面三个独立的部分,R-CNN的训练就完成了,可以看到,确实是非常麻烦,这不仅仅体现在速度慢上,过程也及其繁琐,因为每一步都需要重新构建样本。
R-CNN的测试
经过训练的R-CNN就可以拿来做测试了,测试过程还是可以一次完成的,它有下面几步:
1.ss算法提取1000-2000个区域;
2.对所有的区域做归一化,为了CNN网络能接受;
3.用AlexNet网络提出两套特征,一个是fc7层的,一个是con5层的;
4.对于一个fc7区域的特征,分别过20个分类器,看看哪个分类器给的分数最高,以确定区域的类别,并把所有的区域一次操作;
5.对上述所有打好label的区域使用非极大值抑制操作,以获取没有冗余(重叠)的区域子集,经过非极大值抑制之后,就认为剩下的所有的区域都是最后要框出来的;
6.重新拿回第5步剩下的区域con5层的特征,送入Bounding box模型,根据模型的输出做出一次修正;
7.根据SVM的结果打标签,根据修正的结果画框;
8.结束!!!!!!
R-CNN性能评价
R-CNN的出现使计算机视觉中的目标检测任务的性能评价map出现了质的飞跃:

但是R-CNN也有一个很致命的缺陷,超长的训练时间和测试时间:
训练时间需要84个小时,如果说训练时间还不是那么重要的话,那么单张图片的测试时间长达47s,这个缺陷使R-CNN失去了实用性,好在后续的各种算法对其进行了改进,这个我们后面在提。
补充
1.非极大值抑制在这里不介绍了;
2.如何根据Bounding box模型的输出做出修正:
模型输出是四个值的偏差(比例),那么根据如下公式就能够得到最后的位置
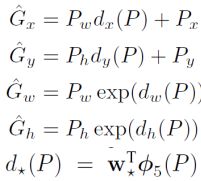
第五个公式就是Bounding box模型。