python爬虫基础知识整理
本文主要记录python爬虫的基础知识点,主要知识:理论基础、爬虫技能简述、实现原理和技术、uillib库和urlerror、headers属性和代理服务器设置。
1)理论基础部分
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以按照我们设置的规则自动化爬取网络上的信息,这些规则被称为爬虫算法。
2)爬虫的组成有控制节点、爬虫节点和资源库
个人简单理解就是控制节点相当CPU,根据url分配线程,爬虫节点相当于GPU负责进行具体的爬取数据
3)爬虫类型
通用网络爬虫,主要用于大型搜索引擎中,由于其爬取范围广、数据量大所以对性能的要求较高
聚焦网络爬虫,按照预先定义好的主题进行有选择性的爬取,所以节省了资源,可以用于特定场景为特定人群服务,另外还有增量式网络爬虫和深层网络爬虫有时间可以深入了解
4)爬虫实现原理
通用网络爬虫:
------- 获取初始的url
------- 根据初始的url爬取页面并获得新的url
------- 将新的url放到url队列中
------- 从url队列中读取新的url,并根据新的url爬起网页,同时从新网页中获取新url,并重复上述过程
------- 满足爬虫系统设置的停止条件时,停止爬取
聚焦网络爬虫:
-------对爬取目标的定义和描述
-------获取初始的url
-------根据初始的url爬取页面,并获得新的url
-------从新的url中过滤掉与爬取目标无关的链接
-------将过滤后的链接放的url队列中
-------从url队列中,根据搜索算法,确定url的优先级,并确定下一步要爬取的url地址
-------从下一步要爬取的url地址中,读取新的url,然后依据新的url地址爬取网页,并重复上述爬取过程
------满足爬虫的停止条件时或无法获取新的url时停止爬
5)爬行策略有深度优先爬行策略、广度优先爬行策略、大站优先爬行策略、反链策略、其他爬行策略
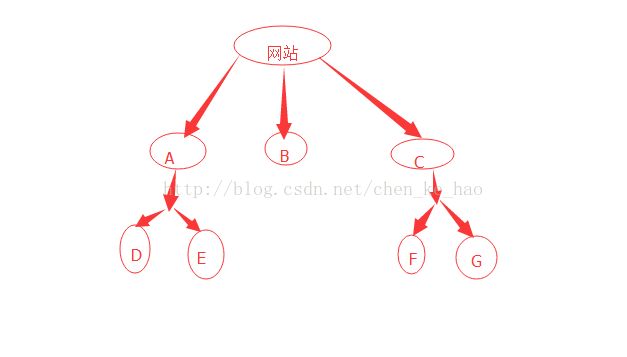
以这张图为例,如果假设有这样一个网站,网站里有一下这些页面,如果用深度优先策略爬取那么会首先爬取一个网页然后将这个网页的下层链接一次深入爬完再返回上一层进行爬取顺序为。A-D-E-B-C-F-G
如果是广度优先爬行策略的话,就会首先爬取同一层次的网页,将同一层次的网页爬完之后,再选择下一层次的网页去爬取顺序为A-B-C-D-E-F-G,
另外还有大站优先爬行策略,可以按照对应网页所属的站点归类,网站的网页数量多,就可以被成为女大站,那我就优先爬取大站的数据。
反链爬取指的是该网页被其他网页指向的次数,这个次数在一定程度上代表该网页被其他网页推荐的次数,这中爬取一般会考虑可靠的反链数,这样可以排除用垃圾站群将网页互相连接从而得到较高的连接数的作弊情况
6)网页更新策略,常见的更新策略有
用户体验策略:搜索引擎在查询某个关键词时,会有一个排名结果,用户一般都会访问排名靠前的前的网站,所以在服务器资源有限的情况下,会优先更新排名靠前的网站
历史数据策略:依据网页的历史数据通过泊松过程进行建模,从而确定下一次的更新时间,进而确定下一次爬取的时间
聚类分析策略:如果一个网页时新网站,没有历史数据可供分析,并且如果去存储历史数据就会增加服务器的负担,依据网页一些共性进行重新分类
7)网页分析算法有基于用户行为的网页分析算法、基于网络拓扑的网页分析算法、基于网页内容的网页分析算法
urllib库和异常处理
使用urllib爬取网页:首先导入模块,这样爬取的数据是一些编码,不能读取
import urllib.request
urllib.request.urlopen('网址')这样就爬取到了对应的网页数据,如何读取这些数据呢
import urllib.request
urllin.request.urlopen('网址').read().decode('utf-8')#爬取网页,以utf-8的编码格式读取数据还可以直接爬取数据并保存到文件,这种方法产生的缓存可以用urlretrieve()清除
urllib.request.urlretrieve('网址',filename='储存路径')
urllib.request.urlcleanup#这种方法产生的缓存可以用urlretrieve()清除
f.info()#返回当前环境的有关信息
f.getcode()#获取当前爬取页面的状态码,返回200为正确
f.geturl#获取当前所爬取的url地址
一般url标准中只会允许一部分ASCII字符入数字、字母、部分符号等,如果是汉字或以下特殊字符比如:&等就需要编码,可用下面的方法编码和解码
urllib.request.quote('需要编码的地址或字段')
urllib.request.unpuote('需要解码的地址或字段')有一些网站在爬取时会出现403错误,无法爬取的情况,这是网站做了反爬虫设置,此时可以设置Headers信息,模拟成浏览器访问这些网页,如何得到headers信息呢
将User-Agent这一段复制下来,这个段可以重复使用所以拿到后可以保存以后继续用
方法一,用build_opener()改报头
url='网址'
h=('User-Agent','头信息')
op=urllib.request.build_opener()#创建自定义opener对像并赋值给op
op.addheaders=[h]#添加头信息
data=opener.open(url).read()#打开网址读取数据方法二用add_header添加报头
url='网址'
r=urllib.request.Request(url)#创建一个request对象赋给r
r.add_header('User-Agent','头信息')
data=urllib.request.urlopen(r).read()超时设置,在爬取网页时我们会遇到超时无法打开网页的情况,我们可以设置超时时间避免
import urllib.request
for i in range(1,100):
try:
data=urllib.request.urlopen('https://1111.tmall.com',timeout=0.1).read()#timeout参数就是用来设置超时时间的
print(len(data))
except Exception as e:#异常扑捉
print('出现异常---->'+str(e))#用字符串格式打印出扑捉到的异常信息
HTTP请求,主要说GET请求和POST请求
GET请求会通过url网址传递信息,可以在网址中直接写上要传递的信息,比如这个网址
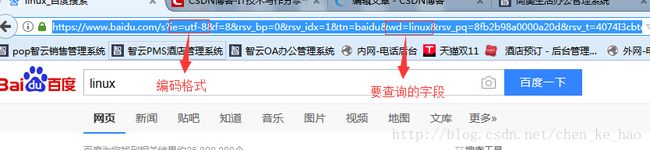
其实上面这个网址我们可以简化为一下形势,一样可以找到页面,这个字段wd=就是我要查询的信息
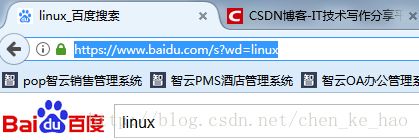
import urllib.request
'''
key='linux'
url='https://s.taobao.com/search?q='+key
print(url)
构造GET请求
r=urllib.request.Request(url)
'''
data=urllib.request.urlopen('https://s.taobao.com/search?ie=&q=iphonex').read()#请求数据
#写入文件
f=open('F:/uuuu/2.html','wb')
f.write(data)
f.close()
POST请求,再登陆、注册等操作时都会用到POST请求。
这部分可以查看我之前一篇博文,http://blog.csdn.net/chen_ke_hao/article/details/78145373
代理服务器设置
用同一个ip爬取同一个网页久了会被屏蔽,所以我们就需要设置代理服务器爬取,
def daili(proxy,url):
proxy=urllib.request.ProxyHandler({'http':proxy})#设置对应的代理服务器信息
op=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)#设置一个自定义opener对象,1参为代理信息,2参为HTTPHandler类
urllib.request.install_opener(op)#将op安装为全局,这样在使用urllib的时候亦会使用我们安装的op对象,所以下面才能直接用urllib爬取数据
data=urllib.request.urlopen(url).read()#.decode('utf-8')
return data
proxy='121.232.146.146:9000'
data=daili(proxy,'https://www.csdn.net/')
f=open('F:/uuuu/4.html','wb')
f.write(data)
f.close()
print(len(data))

Debuglog实例
Debuglog可以程序运行中,边运行边打印调试日志,这里举一个简单例程
http=urllib.request.HTTPHandler(debuglevel=1)#带上这个参数就会打印日志
http1=urllib.request.HTTPSHandler(debuglevel=1)
opener=urllib.request.build_opener(http,http1)#将对象赋予opener
urllib.request.install_opener(opener)#安装位全局
data=urllib.request.urlopen('https://www.csdn.net/').read()#读取数据
print(len(data))

异常处理-URLerror
程序在执行中可能会出现异常,这时就需要异常处理以避免程序退出,异常处理常用的是URLerror类和HTTPerror类
一般来说,产生URLError的原因有如下几种可能
1)连接不上服务器
2)远程URL不存在
3)无网络
4)触发了HTTPError(连接到了目标,但是被服务器拒绝,所以这个异常就会给返回一个状态码比如403、404等)
状态码的含义:
200 OK 一切正常
301 Moved Permanently 重定向到新的URL,永久性
302 Found 重定向的临时的url,非永久性
304 Not Modified 请求的资源未更新
400 Bad Request 非法请求
401 Unauthorized 请求未经授权
403 Forbidden 禁止访问
404 Not Found 没有找到对应页面
500 Internal Server Error
501 Not Implementation 服务器不支持实现请求所需要的功能
import urllib.error
try:
urllib.request.urlopen('http://blog.csdn.ne1t')
except urllib.error.URLError as e:#使用异常处理URLError类,将捕获到的信息赋予e
#print(e.code)#打印状态嘛,这里的网址是不存在的所以就不会有服务器给返回状态码,所以这句要注释掉,否则会有报错找不到code
print(e.reason)#打印错误信息
但是如果我们要用URLError类和HTTPError类一起用的话,并且如果没有状态码返回就要注释掉code,但是我总不能每次都知道有没有状态码返回吧,所以可以优化成下面这样。
import urllib.error
try:
urllib.request.urlopen('http://weixin.sogou.com/1')#微信文章里没有的页面
#print(len(data))
except urllib.error.URLError as e:#使用异常处理URLError类,将捕获到的信息赋予e
if hasattr(e,'code'):#判断是否有状态码
print(e.code)#打印状态
if hasattr(e,'reason'):#判断是否有错误信息
print(e.reason)#打印错误信息