单机形式的kafka+ zookeeper的简单使用
一、zookeeper安装
首先安装zookeeper,版本3.4.6,网址https://zookeeper.apache.org/
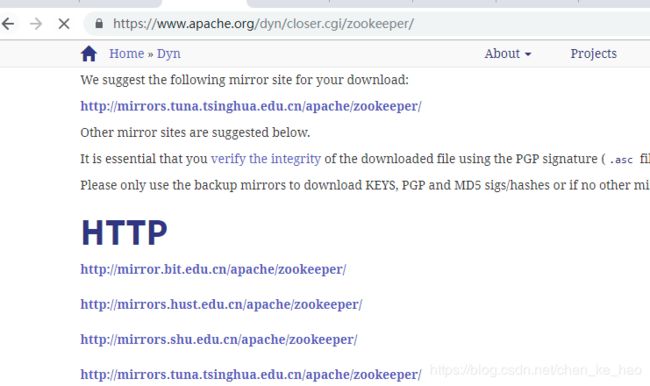
解压,tar xzvf zookeeper-3.4.6.tar.gz,这里把解压后的文件放到/usr/下面并创建日志目录
mkdir /usr/zookeeper/log然后再创建myid文件,如果是集群部署这个是各个集群的节点标识不能重复
echo 1 > /usr/zookeeper/zookeeper/myid然后进入zookeeper的安装目录下的conf目录执行如下操作编辑配置文件
cd /usr/zookeeper/conf && mv zoo_sample.cfg zoo.cfg && vim zoo.cfg最后一行,这个定义了每个主机对应的节点,server.x,x数值应和myid保持一致,当zookeeper启动时会读取myid文件和zoo.cfg配置信息,然后确定唯一的节点,后面的端口号是集群中Leader和Follower之间进行通信的端口,一般不用修改,保存即可
dataDir=/usr/zookeeper 数据目录去掉注释修改如此
dataLogDir=/usr/zookeeper/log 追加一行事务日志目录
autopurge.snapRetainCount=3 保留文件数据配置,默认是3
添加一行清理频率的配置,单位是小时,默认为0,表示不会自动清理,应该根据需要配置一个>=1的整数,这里配置为1:
autopurge.purgeInterval=1
server.1=192.168.3.10:2888:3888 最后添加节点信息,这里可以配hosts名,但是我这里是直接写的IP 然后执行启动后,查看信息无问题
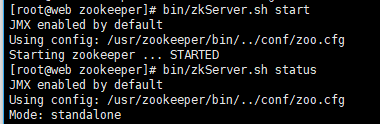
二、kafka安装
网址https://www.apache.org/,这里选择2.0.0版本的基于Scala 2.11的kafka_2.11-0.9.0.1.tgz安装包


这里的先决条件是zookeeper正常运行
tar xzvf kafka_2.11-0.11.0.2.tgz 解压安装包
mv kafka_2.11-0.11.0.2 /usr/kafka 移动到/usr/目录下然后编辑配置文件
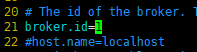
vim config/server.properties修改broker.id=1,默认是0。这个值是集群中唯一的一个整数,每台机器各不相同,这里web节点设置为1其他机器后来再更改
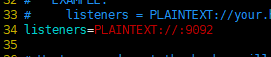
然后往下找到listeners这个配置项一般配置PLAINTEXT://ip:9092,如果配置0.0.0.0则绑定全部网卡,如果默认像下面这样,kafka会绑定默认的所有网卡ip,一般在机器中hosts,hostname都要正确配置,这里默认即可;然后下面的port默认不用配置
注意另外有一些advertised开头的参数,这些参数可以提供客户端访问的配置,比如advertised.listeners会覆盖listeners配置效果和listeners配置完全一样,但是客户端访问时会通过配置的参数访问zookeeper,另外还有advertised.host.name参数,这个也是指定客户端获取元数据的zookeeper主机,默认情况下如果这些参数不配置,那么客户端访问时hosts必须配置kafka集群的地址映射,否则直接会找不到对应的主机,但是advertised.host.name配置之后,客户端可以直接使用ip地址就可以生产或消费kafka,kafka会自动返回advertised.host.name的值供客户端使用,注意这里advertised.host.name一定要设置为ip地址,而不是主机名因为kafka会原样返回;这些就是advertised参数的区别和用途,生产环境中根据需要进行配置即可
然后配置kafka日志目录,注意目录要提前建好
![]()
然后下面num.partitions是默认单个broker上的partitions数量,默认是1个,如果想提高单机的并发性能,这里可以配置多个
![]()
然后是kafka日志的保留时间,单位小时,默认是168小时,也就是7天
![]()
然后设置协调的zookeeper集群列表,然后指定了Kafka在zookeeper上创建的znode为/kafka
![]()
默认6000,这个表示连接zookeeper服务器的超时时间
![]()
在路径里执行启动kafka的命令,-daemon意思是放到后台运行
bin/kafka-server-start.sh -daemon config/server.propertiesjps可以查看到进程,由于我之前新建过topic,运行topic查看命令可以看到之前建好的主题
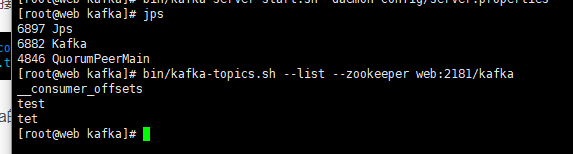
可以查看topic里的消息,当然得推送过消息才能看到

三、Python标本消费kafka数据和推送数据
生产数据
from kafka import KafkaProducer
import time
producer = KafkaProducer(bootstrap_servers = 'web:9092')
r = producer.send('test','{"name":"chenkehao"}')
#r.get(timeout=10) 阻塞时间也可以用time.sleep()代替
time.sleep(0.1)
print 'OK'在topic里就可以看到这个消息
![]()
消费数据
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',bootstrap_servers='web:9092')
for msg in consumer:
print msg可以看到数据已经消费到了
![]()