Python 学习开发最佳工具 pycharm+anaconda
Python语言近来在人工智能,机器学习,数据分析等领域的突出表现让其火爆异常。在Github搜一下machine learning 可以看到语言使用情况排名如下:

图1
此处不想过多介绍Python优缺点,本文主要是告诉初学者如何搭建python练习平台。在众多的python解析器和工具中,个人认为Anaconda + pycharm是很不错的搭配。
前者拥有丰富的包可以直接调用,省去了很多pip安装过程,后者是只针对python使用的开发工具。
本文内容 介绍 Pycharm 和Anaconda的下载,安装,配置 及第一个程序运行完成。
下载:
根据自己电脑系统选择合适的32位或64位的程序安装包,他们都支持Windows, MacOS 和Linux系统. Pycharm 主要选择Community版本
Pycharm 下载: http://www.jetbrains.com/pycharm/download/#section=windows
Anaconda 下载: https://www.anaconda.com/download/
安装:
初学者可以直接使用默认的安装方式,两个包安装在同一目录下,注意安装过程比较慢,尤其是Anaconda,需要十几分钟,咱安装3.6版本,安装完后文件夹就有3.7GB。
配置:
安装完以上两个程序包后 开始配置。打开Pycharm 选择File-->Default setting--> Project Interpreter, 将会看到右边的project interpreter 显示
选择向下箭头可以看到 Anaconda3\python.exe路径(图2),选择确认即可。配置完成后可以看到已经导入了很多包,版本及最新的版本(图3)。
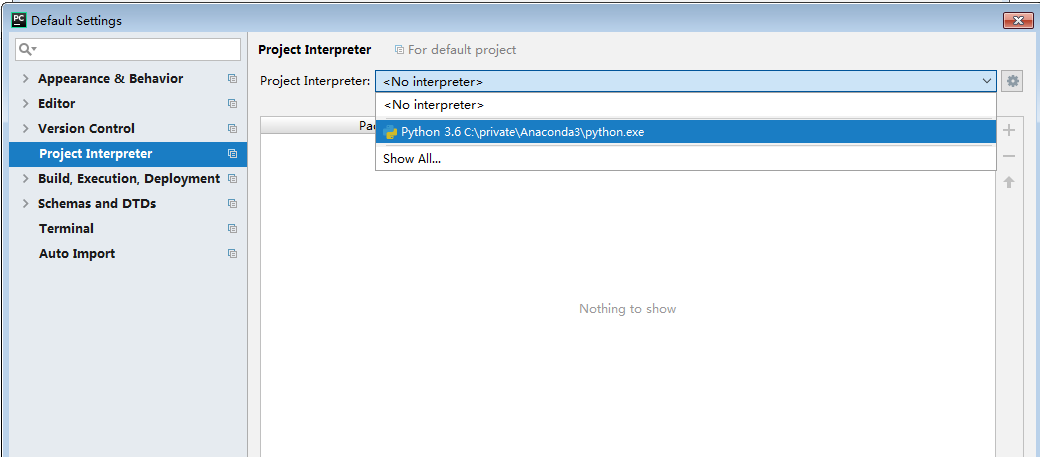
图2
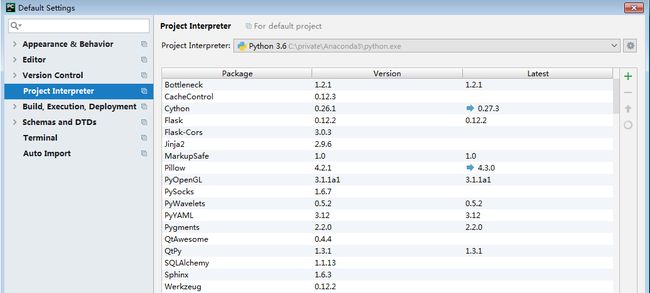
图3
项目案例:
目前为止最佳工具已经做好,接下来就可以发挥您的优势来玩转pyhon
下列程序是一个用来统计一篇英文新闻中使用最频繁的单词,只是做简单展示,因而提前下载好文本文件,且没有使用去停用词功能。
对该案例简单分析:
第一步 需要考虑如何打开文件 直接使用open() 还是使用with open() as f 方式,推荐使用后者,可以不用考虑自己写代码关闭文件问题
第二步 需要考虑如何计算每个单词出现的频率,最好的方式是使用字典统计,用字典的关键字存储单词,字典值存储次数
第三步 在统计单词前需要将单词从文件中提取,这里采用正则方式直接提取单词,当然这里比较简单,后续复杂类型可以考虑使用NLP工具包
第四步 对统计好的字典按出现单词频率最高进行排序,也就是使用sorted() 进行逆排序,之后采用列表切片方式获取使用最频繁的单词。
# Program start. import re import io #Define a class to process text and calculate words frequency class CounterWords(): #Read text file and save the words in dict def __init__(self,path): self.word_dict = dict() with io.open(path,encoding="utf-8") as f: data = f.read() words = [single.lower() for single in re.findall("\w+", data)] for word in words: self.word_dict[word] = self.word_dict.get(word,0) + 1 #Calculate the top used words frequency def word_frequency(self,n): assert n > 0, "n should be large than 0" word_sort = sorted(self.word_dict.items(), key=lambda item:item[1], reverse=True) return word_sort[:n] if __name__ == "__main__": top_commom_word = CounterWords('news_xinhua.txt').word_frequency(10) print ("The top used words:") for word in top_commom_word: print (word)
Output the top 10 used words:
The top used words:
('the', 23)
('of', 19)
('and', 16)
('cpc', 8)
('central', 6)
('committee', 6)
('a', 6)
('to', 6)
('xi', 5)
('political', 5)
哈哈 “xi” 使用了5次, 此处的"xi"就是习大大,这是一篇关于习大大主持的民主生活会的文章,有5次提到他哦。
本文仅做自己记忆的笔记,希望对新人有所借鉴。