【Deep Learning】DeepLab
【论文】SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
前段时间学习了DeepLab,这里花时间记录一下,感谢几位小伙伴的分享。DeepLab的主体结构事实上是参照VGG改造的,它的几个优点:首先是速度快(hole算法),另外是精确(CRF),然后是网络结构简单(采用了DCNN和CRF结合的形式)。下面简单记录一下DeepLab的结构和思想,第一部分介绍DCNN的结构创新,第二部分介绍Hole算法。
【1.1】Dense spatial score evaluation
1. 把VGG-16的全连接层改成卷积层
把最后的全连接层改造成卷积层,整个网络相当于变成了一个全卷积网络,这个方法不详细叙述,不了解的童鞋可以看看FCN或者SEGNET。但是原本的VGG有5个pooling层,这样的话在pooling5输出的的feature非常稀疏,即把原尺寸缩小了32倍(2^5,即整体的stride=32,计算公式为:strides(i)=stride(1)*stride(2)*…*stride(i-1)),这恰恰是全卷积网络的通病,所以我们需要得到更dense的图像。
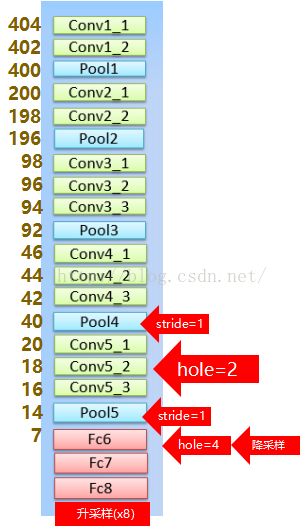
2. 为了让获得的图像更为dense,将pooling4、5的stride由2变为1,如下图:
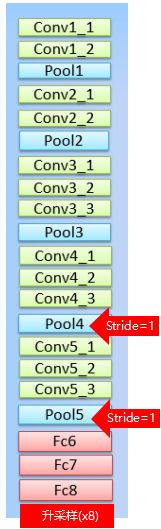
这样的话尺寸就缩小为原本的8倍,但是这样的话之后节点的感受野就会发生变化。
这里有个感受野的计算公式:
RF=((RF-1)*stride)+fsize
感受野需要层后往前推,也就是“当前这一层的节点往前看能看到多少前几层的节点”。公式中假设当前层的RF=1,stride是上一层的步长,fsize是filter的尺寸,padding不影响感受野大小。这是一个递推公式。详细解释这个问题,请看下面的图:

最左边的图就是VGG原来的结构,可以看到最下方的层往前看,能看到4个最上面层的节点,标号从左到右分别是{1,2,3,4},{3,4,5,6},{5,6,7,8},右边是将pooling的stride变为1之后的图,显而易见,最下方的节点的RF减少,只能看到最上面层的三个节点。
为了解决这个问题,作者提出了Hole算法。
3. Hole算法
为了保证感受野不发生变化,某一层的stride由2变为1以后,后面的层需要采用hole算法。具体来讲就是将连续的连接关系是根据hole size大小变成skip连接的。pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。同时由于Hole算法让feature map更加dense,所以网络直接用差值升采样就能获得很好的结果,而不用去学习升采样的参数了(FCN中采用了de-convolution)。
则网络结构变为:
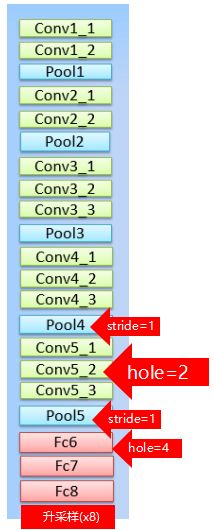
要解释这个问题还是回到刚才那个简单一些的问题:

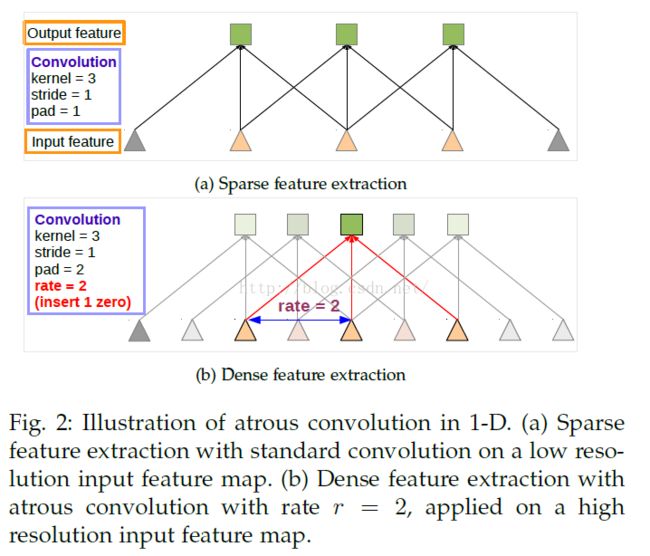
我们在下方的卷积层中应用Hole算法,可以看到最下方多了两个神经元,但是每个神经元感受野都没有变化,都能看到最上层的4个神经元。运用hole算法之后实际的kernel_size有个计算公式:ke = k + (k-1)(r-1),这里的r是rate,其实就是input stride,一个意思。
4. 对VGG16进行finetune
将原来分类的1000类改为21类,因为要分割出21种物体,同时把损失函数改为交叉熵的形式。即对于样本集,p为真实分布,q为预测分布,则有:
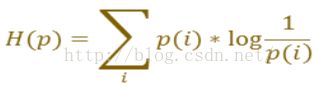
这和逻辑回归的损失函数是一样的,只是将2类拓展到多类。不明白的童鞋可以去看看LR。
【1.2】Controlling the network’s respective field size
1. 对FC6的卷积核直接降采样
VGG16 的感受野是224*224(文中写的是这个,但是我觉得应该是212*212),把网络改为全卷积的话是404*404(fc6的卷积核大小是7*7)。但是这样做的话,这部分就会成计算速度提升的瓶颈,左右又提出一个做法,对第一层全连接层的卷积核做简单的降采样到4*4(3*3), 计算速度变快,改成4*4的时候RF变为308,有兴趣的可以算一算。
2. 把FC6输出的feature map从4096减少到1024
以上两步都加快了运算速度。
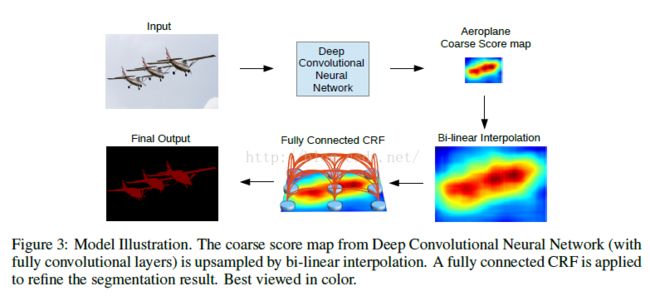
【2.1】在升采样之后加入CRF(条件随机场)精细化边缘
越深的网络分类越精确,但是因为不变性和大感受野导致定位不精确。此处加入CRF精细化边缘信息。
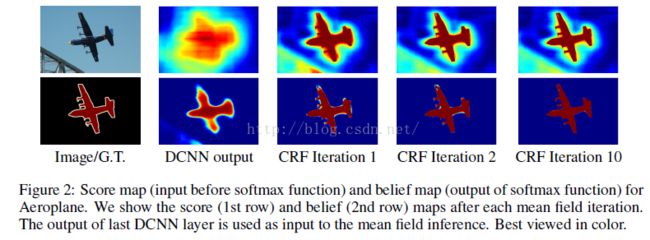
下图中第一行是在输入softmax之前做CRF得到的结果,下面一行是softmax的输出经过CRF得到的结果。
简单介绍一下CRF。我们用下面的公式来表示输出结果的整体能量,或者说混沌程度,称为能量函数(energy function):
![]()
前一项代表像素的内聚程度,其中,其中P(xi)就是DCNN输出的score map在i这个像素上,它的真实标签的概率。
后一项代表相邻节点的相关程度
![]()
其中二元能量项描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。二元势函数描述的是每一个像素与其他所有像素的关系,所以叫“全连接”。
对每一个类(现在有21类)求解E(x),当取到min E(x)时像素值最稳定。
【2.2】Multi-scale prediction
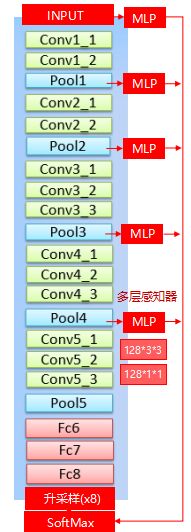
参考FCN的做法,将INPUT,pooling1,pooling2,pooling3,pooling4的输出结果信息传到sofftmax,因为随着层数的加深,一些细节还是会被丢失。具体的做法是在这几个地方加入多层感知机,其实就是3*3*128和1*1*128两个卷积层,最后再融合到softmax。
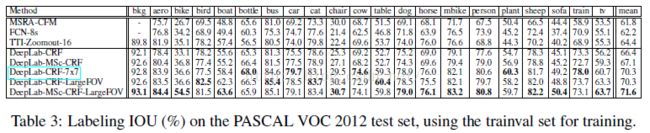
【3】实验对比
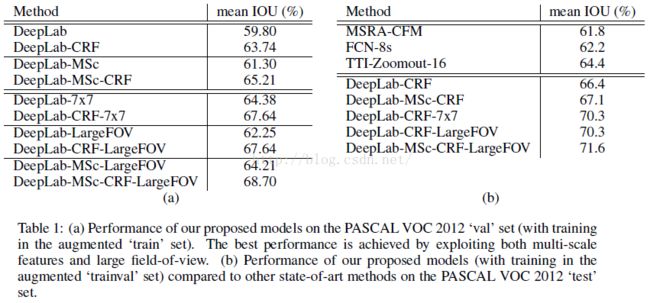
最后就是一个实验的对比,可以看到DEEPLAB+MSC+CRF+LARGEFOV的效果是最好的。
下图是deeplab在pascal voc上的mean IoU对比。
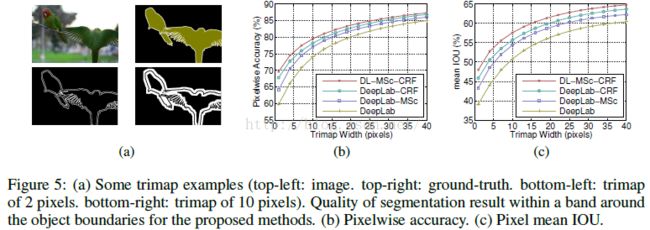
下图是检验边界分割的准确率,在边界设置一个窄带(白色部分),叫做trimap(文中原话:We compute the mean IOU for those pixels that
are located within a narrow band (called trimap) of ‘void’ labels.),在trimap中计算mean IoU,然后加大trimap的宽度,再计算准确率,得到曲线。
下图是DeepLab在PASCAL VOC 2012的测试集上的准确率对比。