Spark 2.0 DataSet 各种操作 action操作 基本操作 typed untyped
1、Action操作
employee数据表
{"name": "Leo", "age": 25, "depId": 1, "gender": "male", "salary": 20000}
{"name": "Marry", "age": 30, "depId": 2, "gender": "female", "salary": 25000}
{"name": "Jack", "age": 35, "depId": 1, "gender": "male", "salary": 15000}
{"name": "Tom", "age": 42, "depId": 3, "gender": "male", "salary": 18000}
{"name": "Kattie", "age": 21, "depId": 3, "gender": "female", "salary": 21000}
{"name": "Jen", "age": 30, "depId": 2, "gender": "female", "salary": 28000}
{"name": "Jen", "age": 19, "depId": 2, "gender": "female", "salary": 8000}
执行代码
import org.apache.spark.sql.SparkSession
/**
* action操作详解
*
* collect、count、first、foreach、reduce、show、take
*
*/
object ActionOperation {
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("ActionOperation")
.master("local")
.config("spark.sql.warehouse.dir", "C:\\Users\\Administrator\\Desktop\\spark-warehouse")
.getOrCreate()
import spark.implicits._
val employee = spark.read.json("C:\\Users\\Administrator\\Desktop\\employee.json")
// collect:将分布式存储在集群上的分布式数据集(比如dataset),中的所有数据都获取到driver端来
employee.collect().foreach { println(_) }
// count:对dataset中的记录数进行统计个数的操作
println(employee.count())
// first:获取数据集中的第一条数据
println(employee.first())
// foreach:遍历数据集中的每一条数据,对数据进行操作,这个跟collect不同,collect是将数据获取到driver端进行操作
// foreach是将计算操作推到集群上去分布式执行
// foreach(println(_))这种,真正在集群中执行的时候,是没用的,因为输出的结果是在分布式的集群中的,我们是看不到的
employee.foreach { println(_) }
// reduce:对数据集中的所有数据进行归约的操作,多条变成一条
// 用reduce来实现数据集的个数的统计
println(employee.map(employee => 1).reduce(_ + _))
// show,默认将dataset数据打印前20条
employee.show()
// take,从数据集中获取指定条数
employee.take(3).foreach { println(_) }
}
}
2、基础操作
持久化
创建临时视图 主要是为了可以直接对数据执行sql语句
获取执行计划 获取spark sql的执行计划
查看schema
写数据到外部存储
dataset与dataframe相互转换 as toDF
package com.scala.spark
import org.apache.spark.sql.SparkSession
object BasicOperation {
case class Employee(name:String,age:Long,depId:Long,gender:String,salary:Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("action").master("local").getOrCreate()
import spark.implicits._
val employee=spark.read.json("employee")
//第一步 cache()避免重复计算
/* employee.cache()
println(employee.count())
println(employee.count())*/
//创建临时视图,主要是为了,可以直接对数据执行sql语句
employee.createOrReplaceTempView("temp")
spark.sql("select * from temp where age>25").show()
//获取sql执行计划
//dataframe/dataset,比如执行了一个sql语句获取的dataframe,实际上内部包含一个logical plan,逻辑执行计划
//设计执行的时候,首先会通过底层的catalyst optimizer,生成物理执行计划,比如说会做一些优化,比如push filter
//还会通过whole-stage code generation技术去自动化生成代码,提升执行性能
spark.sql("select * from temp where age>25").explain()
employee.printSchema()
val employDataSet = employee.as[Employee]
employDataSet.show()
employDataSet.printSchema()
val frame = employDataSet.toDF()
frame.show()
frame.printSchema()
}
}
3、typed操作 类似rdd 有稍微区别
repartition 操作 coalesce操作
coalesce和repartition操作 都是重定义分区 区别coalesce只能减少分区数量 而且可以选择不发生shuffle
repartiton,可以增加分区,也可以减少分区,必须会发生shuffle,相当于是进行了一次重分区操作
package com.scala.spark.typedOperation
import org.apache.spark.sql.SparkSession
object TypedOperation {
case class Employee(name:String,age:Long,depId:Long,gender:String,salary:Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("action").master("local").getOrCreate()
import spark.implicits._
val employee=spark.read.json("employee")
val DataSet = employee.as[Employee]
println(DataSet.rdd.partitions.size)
//coalesce和repartition操作 都是重定义分区 区别coalesce只能减少分区数量 而且可以选择不发生shuffle
// repartiton,可以增加分区,也可以减少分区,必须会发生shuffle,相当于是进行了一次重分区操作
val repartitionDataSet = DataSet.repartition(10)
//看下分区
println(repartitionDataSet.rdd.partitions.size)
val coalescePartion = repartitionDataSet.coalesce(5)
println(coalescePartion.rdd.partitions.size)
DataSet.show()
}
}
distinct 和dropDuplicates操作
distinct去重,是根据每条数据,进行完整内容比对之后有重复的去掉
dropDuplicates 根据每一条数据,可以按照指定的字段进行去重 多个条件也可以
/* val distinctDataSet = DataSet.distinct()
distinctDataSet.show()
val singleDrop=DataSet.dropDuplicates(Seq("name"))
singleDrop.show()
val dropDataSet = DataSet.dropDuplicates("name","age")
dropDataSet.show()*/
except filter intersect
except:获取在当前dataset中有,但是在另外一个dataset中没有的元素
filter:根据我们自己的逻辑,如果返回true,那么就保留该元素,否则就过滤掉该元素
intersect:获取两个数据集的交集
val exceptDS = DataSet.except(DataSet2)
exceptDS.show()
val filterDS = DataSet.filter(employee=>employee.age>30)
filterDS.show()
val intersectDS = DataSet.intersect(DataSet2)
intersectDS.show()
map flatmap mapPartitions
map:将数据集中的每条数据都做一个映射,返回一条新数据
flatMap:数据集中的每条数据都可以返回多条数据
mapPartitions:一次性对一个partition中的数据进行处理
/* DataSet.map{my=>(my.name,my.age+1000)}.show()
departMentDS.flatMap{department=>Seq(Department(department.id+1,department.name+"来自于1"),Department(department.id+2,department.name+"来自于2"))}.show()
DataSet.mapPartitions{
allValues =>{
val returnValue=scala.collection.mutable.ArrayBuffer[(String,Long)]()
while(allValues.hasNext){
val every = allValues.next()
returnValue+=((every.name,every.salary+8888))
}
returnValue.iterator
}
}.show()
*/
flatmap

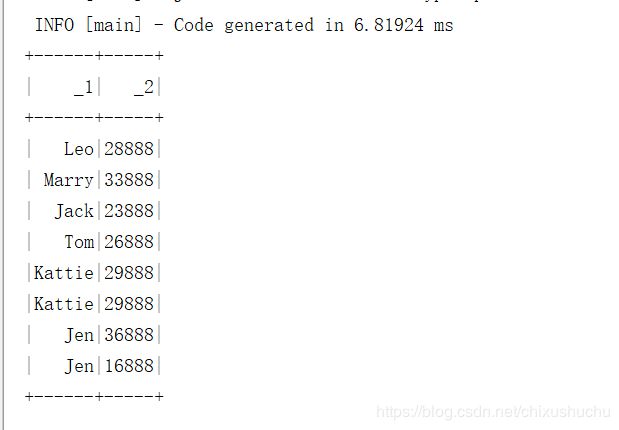
joinwith
//将两个数据集 连到一起
DataSet.joinWith(department,$"depId"===$"id").foreach(println(_))
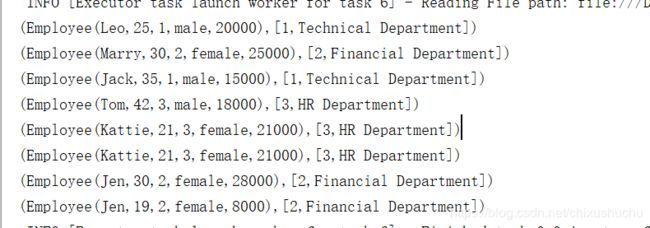
sort
DataSet.sort($"age".desc).show()
randomSplit sample
randomSplit 按照比例将dataset切割为几个
sample按照指定比例抽取数据
//randomSplit 按照权重 将dataset切割为几个dataset
val randomSplitDS = DataSet.randomSplit(Array(2,3,5))
randomSplitDS.foreach(ds=>ds.show())
//sample 按照指定比例,随机抽取数据
DataSet.sample(false,0.3).show()
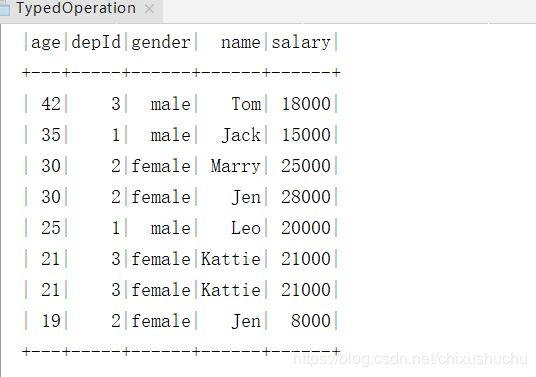
package com.scala.spark.typedOperation
import org.apache.spark.sql.SparkSession
object TypedOperation {
case class Employee(name:String,age:Long,depId:Long,gender:String,salary:Long)
case class Department(id: Long, name: String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("action").master("local").getOrCreate()
import spark.implicits._
val employee=spark.read.json("employee")
val employee2=spark.read.json("employee2")
val department=spark.read.json("department")
val departMentDS = department.as[Department]
val DataSet = employee.as[Employee]
val DataSet2=employee2.as[Employee]
/* println(DataSet.rdd.partitions.size)
//coalesce和repartition操作 都是重定义分区 区别coalesce只能减少分区数量 而且可以选择不发生shuffle
// repartiton,可以增加分区,也可以减少分区,必须会发生shuffle,相当于是进行了一次重分区操作
val repartitionDataSet = DataSet.repartition(10)
//看下分区
println(repartitionDataSet.rdd.partitions.size)
val coalescePartion = repartitionDataSet.coalesce(5)
println(coalescePartion.rdd.partitions.size)
DataSet.show()*/
//去重
// 都是用来进行去重的,区别在哪儿呢?
// distinct,是根据每一条数据,进行完整内容的比对和去重
// dropDuplicates,可以根据指定的字段进行去重
/* val distinctDataSet = DataSet.distinct()
distinctDataSet.show()
val singleDrop=DataSet.dropDuplicates(Seq("name"))
singleDrop.show()
val dropDataSet = DataSet.dropDuplicates("name","age")
dropDataSet.show()*/
// except:获取在当前dataset中有,但是在另外一个dataset中没有的元素
// filter:根据我们自己的逻辑,如果返回true,那么就保留该元素,否则就过滤掉该元素
// intersect:获取两个数据集的交集
/* val exceptDS = DataSet.except(DataSet2)
exceptDS.show()
val filterDS = DataSet.filter(employee=>employee.age>30)
filterDS.show()
val intersectDS = DataSet.intersect(DataSet2)
intersectDS.show()*/
// map:将数据集中的每条数据都做一个映射,返回一条新数据
// flatMap:数据集中的每条数据都可以返回多条数据
// mapPartitions:一次性对一个partition中的数据进行处理
/* DataSet.map{my=>(my.name,my.age+1000)}.show()
departMentDS.flatMap{department=>Seq(Department(department.id+1,department.name+"来自于1"),Department(department.id+2,department.name+"来自于2"))}.show()
DataSet.mapPartitions{
allValues =>{
val returnValue=scala.collection.mutable.ArrayBuffer[(String,Long)]()
while(allValues.hasNext){
val every = allValues.next()
returnValue+=((every.name,every.salary+8888))
}
returnValue.iterator
}
}.show()
*/
/*
DataSet.join(departMentDS,$"depId"===$"id").foreach(println(_))
//将两个数据集 连到一起
DataSet.joinWith(department,$"depId"===$"id").foreach(println(_))
DataSet.show()*/
//sort 排序
// DataSet.sort($"age".desc).show()
//randomSplit 按照权重 将dataset切割为几个dataset
val randomSplitDS = DataSet.randomSplit(Array(2,3,5))
randomSplitDS.foreach(ds=>ds.show())
//sample 按照指定比例,随机抽取数据
DataSet.sample(false,0.3).show()
}
}
Untyped操作
select where groupBy agg col join
导入
import spark.implicits._
import org.apache.spark.sql.functions._
package com.scala.spark.untypedOperation
import org.apache.spark.sql.SparkSession
object UntypedOperation {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("untyped").master("local").getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val employee=spark.read.json("employee")
val department=spark.read.json("department")
employee.where($"age">35)
.join(department,$"depId"===$"id")
.groupBy(department("name"),employee("gender"))
.agg(avg((employee("salary"))))
.show()
employee.select("name","age").where($"age">29).show()
}
}

