R语言读取Excel文件
因为一个项目需要,原始数据全部是Excel文件,包括.xls和.xlsx格式,并且很多excel数据的格式并不规范,一个个转为csv格式不太现实,所以把所有能了解到的读取excel的方法都试了一遍,做个简单汇总。
相关的包:RODBC、xlsx、openxlsx、gdata、readxl,测试平台win7。
RODBC包-相关方法
RODBC-odbcConnectExcel2007()、odbcConnectExcel()、sqlFech()、sqlTables()安装
install.packages(“RODBC”, dependencies=TRUE) #可能需要安装一些依赖包使用方法
#64位机下,.xls和.xlsx文件用相同方法
library(RODBC)
con <- odbcConnectExcel2007("D:/R/RODBC.xlsx") #64位机下方法
sqlTables(con) #查看该xlsx文件中有哪些表
# TABLE_CAT TABLE_SCHEM TABLE_NAME TABLE_TYPE REMARKS
# 1 D:\\R\\RODBC.xlsx 商品信息$ SYSTEM TABLE
# 2 D:\\R\\RODBC.xlsx 补充说明$ SYSTEM TABLE
# 3 D:\\R\\RODBC.xlsx 销售信息$ SYSTEM TABLE
table_test <- sqlFetch(con,"销售信息")
table_test
odbcClose(con) 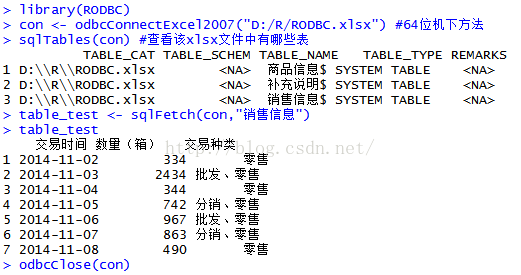
#32位机下,.xls和.xlsx文件主要在方法odbcConnectExcel2007()和odbcConnectExcel()的差异,其余方法相同
con <- odbcConnectExcel ("D:/R/RODBC.xlsx") #
sqlTables(con) #查看该xlsx文件中有哪些表
table_test <- sqlFetch(con,"销售信息")
odbcClose(con)优缺点说明
RODBC主要是读取数据库的包,是我接触到的读取Excel中效率最高的。并且还有sqlQuery方法可以写SQL灵活读取数据。并且能够同时读取.xls和.xlsx文件。.
在简单比较了各种方法后,觉得RODBC真是神器,并且没有各种乱七八糟的限制,于是欢快地选择了它,事实证明它的确是又快又爽,可是也隐藏了许多潜在的坑爹特性,不深入了解根本没办法发现。如果你有幸看到,说不定可以提前绕过某些坑,或者无法绕过,只能另择新欢。
坑No1.
必须通过Sheet名读取表,一个Excel文件里面可能有多个sheet表,所以你要读取其中某张表,或者所有表,必须提前知道每张表的表名。如下图中的”销售信息”、”商品信息”、”补充说明”。此坑影响不大,并且用sqlTables可以查到表名,可以解决这个问题。
#在表结构相同的情况下,读取所有的表内容
con <- odbcConnectExcel2007("D:/R/RODBC.xlsx") #64位机下方法
tbls <- sqlTables(con)
table_test <- sqlFetch(con, tbls$TABLE_NAME[3])
odbcClose(con)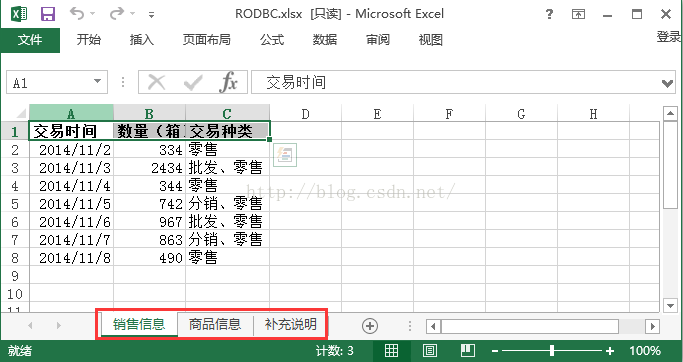
坑No2.
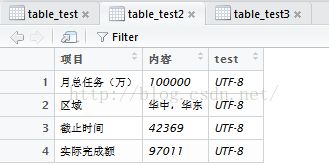
当某一列有不同类型的数值时,就悲剧了,如下例子中,用RODBC读入不能指定读入数据的格式,所以按照Excel默认格式读取数据时,就会出现一列中类型不统一的值为NA。此坑用RODBC无解,只能另择其他。
如下,测试数据中,区域项目是字符,其余字段为数值或日期。下图左边是excel文件中的内容,右边是读入结果。
library(RODBC)
con <- odbcConnectExcel2007("D:/R/RODBC.xlsx") #64位机下方法
table_test3 <- sqlFetch(con,"补充说明")
table_test3
odbcClose(con)

坑No3.
这也是一个不用不知道的坑,RODBC读取Excel文件在数据列较多时,多出的列可能被忽略,RODBC读取极限是255列(没有找到官方的说明,只是我的测试结果)。此坑用RODBC同样无解,只能另择其他。
如下,使用测试数据有380行280列,RODBC读入后,是380行255列。
library(RODBC)
con <- odbcConnectExcel2007("D:/R/RODBC.xlsx") #64位机下方法
table_test2 <- sqlFetch(con,"商品信息")
odbcClose(con)
xlsx包-相关方法
xlsx-read.xlsx()、read.xlsx2()
安装
install.packages(“xlsx”) #需要已经安装rJava包
使用方法
library(xlsx)
table_test <- read.xlsx("D:/R/xlsx.xlsx",1, encoding="UTF-8")
table_test1 <- read.xlsx("D:/R/xlsx.xls",1, encoding="UTF-8")
table_test2 <- read.xlsx2("D:/R/xlsx.xlsx",1, test="UTF-8") #默认读入列为character,可自定义新的列。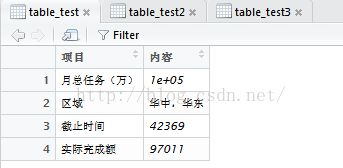
优缺点说明
优点很明显,上面的例子很完美解决了上面RODBC的坑No2.,同时可以读取.xls文件。此外,xlsx还有write.xlsx()系列方法,读写兼具,有需要的可以查看说明文档。
坑No1.
缺点也非常明显,就是效率极低,读取数据时间长并且稍大的数据集就可能出现内存不够用的问题。下面的例子就是用RODBC和xlsx的方法分别读取同一个excel文件所用时间,RODBC的优势很明显,测试数据1340行3列。
library(RODBC)
con <- odbcConnectExcel2007("D:/R/ceshi.xlsx")
system.time(table_test <- sqlFetch(con,"Sheet1"))
odbcClose(con)
library(xlsx)
system.time(table_test <- read.xlsx("D:/R/ceshi.xlsx",1, encoding="UTF-8"))
坑No2.
容易出现内存不够用的问题。用xlsx的方法读取前面用到测试RODBC的数据表,结果,错误信息就是OutOfMemory。

openxlsx包-主要方法
openxlsx-read.xlsx()
安装
install.packages("openxlsx")
使用方法
library(openxlsx)
table_test <- read.xlsx("D:/R/xlsx.xlsx",1)
table_test1 <- read.xlsx("D:/R/xlsx.xls",1)

优缺点说明
优点与xlsx包中的方法一样,不会出现RODBC的坑No2.的问题。此外,读取ceshi.xlsx所花费时间比RODBC稍长,但相比xlsx快了许多。并且同样有write.xlsx()方法,读写兼具。
system.time(table_test <- read.xlsx("D:/R/ceshi.xlsx",1))坑No1.
缺点很大的一个,见上面的使用方法,不能读取.xls文件。
gdata包-相关方法
gdata-read.xls()
安装
install.packages("gdata") #电脑已安装Perl使用方法
library(gdata)
table_test <- read.xls("D:/R/xlsx.xlsx",1, fileEncoding="UTF-8",sep=",") #xlsx文件
table_test1 <- read.xls("D:/R/xlsx.xls",1, fileEncoding="UTF-8",sep=",") #xls文件优缺点说明
优点同样,不会有RODBC的两个问题。效率用同样的ceshi.xlsx文件来做测试,可以看到花费时间优于xlsx。同时可以读取.xlsx和.xls文件。
system.time(table_test <- read.xls("D:/R/ceshi.xlsx",1, fileEncoding="UTF-8",sep=","))
坑No1.
gdata是基于Perl的,所以存在因为Perl而可能出现的问题。读取中文字符时,可能会出现“Wide character in print”的提醒信息。这是由于perl只能处理两种编码:ascii码和utf-8。ascii码是很少的,像中文、日文、韩文等字符要想能被perl处理,只能用 utf-8编码方式。
下面就是我在读取某个Excel文件时,输出的log文件。log文件里面基本上全部是这样的提醒。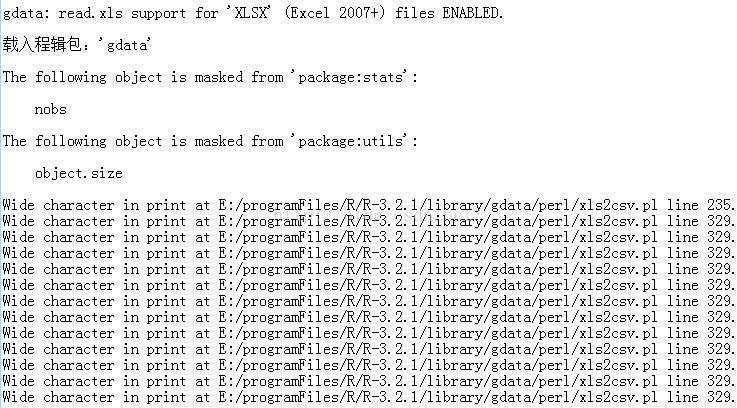
readxl包-相关方法
readxl-read_excel()
安装
install.packages("readxl")使用方法
library(readxl)
table_test <- read_excel ("D:/R/xlsx.xlsx",1, col_types =c("text","text")) #xlsx文件
table_test1 <- read_excel ("D:/R/xlsx.xls",1, col_types = c("text","text")) #xls文件
优缺点说明
优点同样不存在RODBC的坑No1.和坑No2.,读取效率利用ceshi.xlsx文件测试,读取比RODBC更高效。
system.time(table_test <- read_excel("D:/R/xlsx.xlsx",1))坑No1.
见使用方法,不能读取.xls文件。
最后对同一个文件,使用这五个包中的相关方法,对读取结果做一个对比。可以看看这些包在效率和对Excel中一些特殊的数据格式的读取结果。
#gdata
library(gdata)
system.time(table_test <- gdata::read.xls("D:/R/ceshi.xlsx",2, fileEncoding="UTF-8",sep=","))
#RODBC
library(RODBC)
con <- odbcConnectExcel2007("D:/R/ceshi.xlsx") #64位机下方法
tbls <- sqlTables(con)
system.time(table_test1 <- sqlFetch(con, tbls$TABLE_NAME[2]))
odbcClose(con)
#xlsx
library(xlsx)
system.time(table_test2 <- xlsx::read.xlsx("D:/R/ceshi.xlsx",2,encoding="UTF-8"))
#openxlsx
library(openxlsx)
system.time(table_test3 <- openxlsx::read.xlsx("D:/R/ceshi.xlsx",2))
#readxl
library(readxl)
system.time(table_tes4 <- read_excel("D:/R/ceshi.xlsx",2)) 
原始数据表
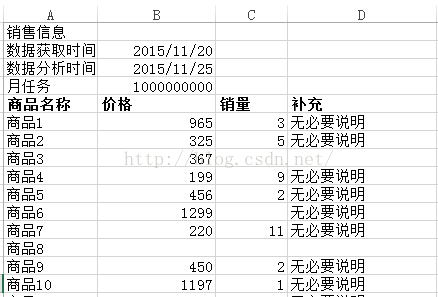
gdata读入结果

RODBC读入结果

xlsx读入结果

openxl读入结果

readxl读入结果
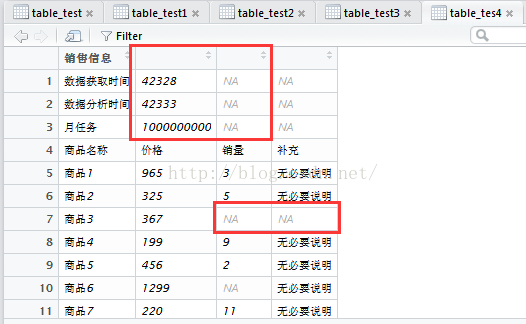
可以说没有完美的方法。
综上,对Excel数据分析的基本原则:
1. 能转化成csv格式,请尽量这样做,这个才是最高效的选择。
2. 1无法达到的情况下,小数据量,并且数据格式比较统一的情况下优先选择RODBC。
3. 非.xls文件时,优先选择readxl、openxlsx。
4. 同时需要读写操作,xlsx(效率较低,对内存要求高)或者openxlsx。有任何问题或建议,欢迎指出。
转载请说明出处,谢谢。