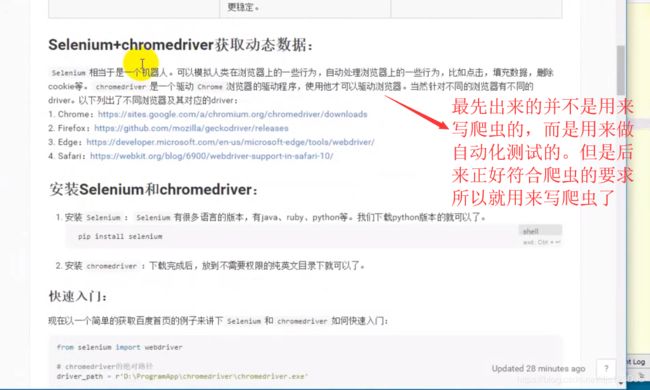
selenium使用 看这一篇就够了
使用 seleniun模拟浏览器进行数据抓取无疑是当下最通用的数据采集方案,它通吃各种数据加载方式,能够绕过客户巧S加密,绕过爬虫检测,绕过签名机制,它的应用,使得许多网站的反采集第略形同虚设:由于lenium不会在HTP请求数据中留下指纹,因此无法被网站直接识别和拦截。但这并不意味着 selenium真的就无法被网站屏蔽了,感兴趣的可以自己去研究。
安装selenium的驱动浏览器,只需要下载下来,放到不需要权限的纯英文目录下就可以了。一般安装在python.exe文件下,这样用的时候就不用写路径了。
selenium 里面的解析库是python语言写的,所以没有lxml这库这么快,lxml是c语言写的。
urL个不变,验证码不变
请求验证码的地址,获得相应,识别
ur1不变,验证码会变
思路:对方服务器返回验证码的时候,会和每个用户的信和验证码进个对应,之后,在用户发送post请求的时候,会对比ost请求中法的验证码和当前用户真正的存储在服务器端的验证码是否相同1.实例化 session
2 .使用 seesion请求登录贡面,获取验证码的地址3使用 session请求验证码,识别
4.使用 session发送post请求13-使用 selenium登录,遇到验证码urL不变,验证码不变,同上
ur不变,验证码会变
1. selenium请求登录页面,同时拿到验证码的地址2获取登录页面中 driver中的 cookie,交给 requests模块发送验证码的请求,识别
3.输入验证码,点击登录
1## seleniun便用的注意点
获取文本和获取属性
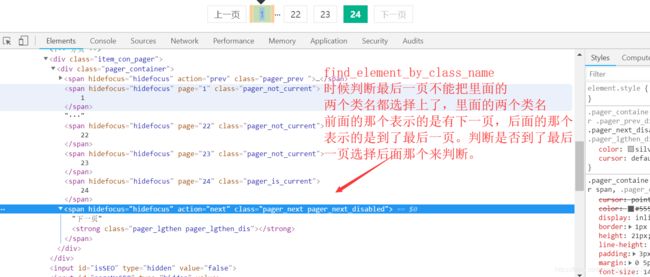
4.先定位到元素,然后调用,text'或者 get_attribute`方法来去- selenium获取的页面数据是浏览器中 elements的内容find element和 find elements的区别find element返回一个 element,如果没有会报错,find elements返回一个列表,没有就是空列表在判断是否有下一页的时候,使用 find elements来根据结果的列表长度来判断
find element和 find elements的区别find element返回一个 element,如果没有会报错find elements返回一个列表,没有就是空列表在判断是否有下一页的时候,使用 find elements来根据结果的列表长度来判断
如果页面中含有 iframe、 frame,需要先调用 driver. switch_to_frame的方法切换到 frame中才能定位元素- selenium请求第一页的时候回等待页面加载完了之后在获取数据,但是在点击翻页之后,selenium直接获取数据,此时可能会报错,因为数据还没有加载出来,需要tine. sleep(3)
inputTag. click
行为链:
有时候在页面中的操作可能要有很多步,那么这时候可以使用鼠标行为链类 Actionchains来完成比如现在要将鼠标移动到某个元素上并执行点击事件。那么示例代码如下:
#行为链
inputag= driver.find_element_by_id("kw")
dianji = driver.find_element_by_id("su")
action = ActionChains(driver)
action.move_to_element(inputag) #把鼠标移到输入框那
action.send_keys_to_element(inputag,"python") #在输入框输入python ,这里要注意不要写send_keys 会报错的
action.move_to_element(dianji) #又把鼠标移到点击按钮上面
action.click(dianji) #然后执行点击
action.perform()#统一执行行为链上的动作#print("driver.page_source")#这个是获取网页的源代码,seleniunm 它不会像requests那样返回数据,想获取请求的数据,要通过属性
来获取。
#_author:'DJS'
#date:2018-11-21
import time
from selenium import webdriver
driver = webdriver.Chrome()
from selenium.webdriver.common.action_chains import ActionChains #导入行为链的类
from selenium.webdriver.support.ui import WebDriverWait #导入显示等待这个类
from selenium.webdriver.support import expected_conditions as EC #导入等待条件类
from selenium.webdriver.common.by import By #导入选择的元素的By
from selenium.webdriver.support.ui import Select #导入select来包装,选取标签下的内容
from lxml import etree
#常见的表单元素:input type='text/password/email/number'
#button,input[type='submit']这个也是一个按钮
#checkbox input=checkbox
#select 下拉列表
#driver.close()关闭之前打开的那个页面
#driver.quit()关闭浏览器
#selenium 里面的解析库是python语言写的,所以没有lxml这库这么快,lxml是c语言写的。
# driver.get("https://www.baidu.com/")
# html = etree.HTML(driver.get)
#如果只想解析网页数据,推荐使用lxml来解析,因为lxml底层是C语言编写的,解析效率会更快
#如果想要对元素进行一些操作,比如给一个文本框输入值,或者点击某个按钮,那么必须使用
#selenium提供给我们查找的方法
# html.xpath("")
#操作selector标签
#driver.get("https://www.douban.com/")
# driver.switch_to_frame("g_iframe")
# driver.find_element_by_id("cateToggleLink").click()
# time.sleep(3)
#driver.find_element_by_class_name("s-fc1 z-slt").click()
#driver.switch_to_frame("g_iframe")
# driver.find_element_by_xpath("//a[text()='写入想定位的文本']").click()
# driver.find_element_by_id("cateToggleLink").click()
# driver.find_element_by_xpath("//a[text()='']").click()
#
#行为链
# inputag= driver.find_element_by_id("kw")
# dianji = driver.find_element_by_id("su")
# action = ActionChains(driver)
# action.move_to_element(inputag) #把鼠标移到输入框那
# action.send_keys_to_element(inputag,"python") #在输入框输入python ,这里要注意不要写send_keys 会报错的
# action.move_to_element(dianji) #又把鼠标移到点击按钮上面
# action.click(dianji) #然后执行点击
# action.perform()#统一执行行为链上的动作
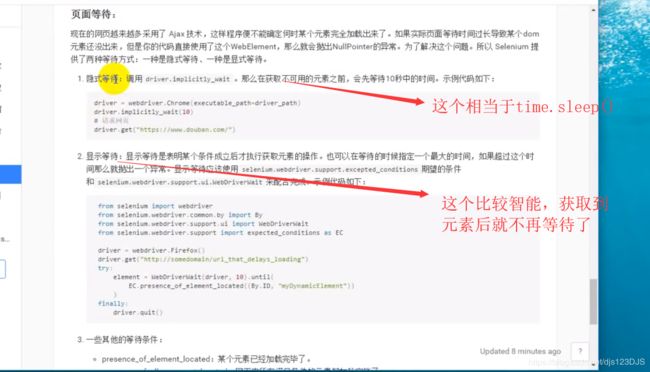
#driver.implicitly_wait(3) #隐式等待 ,作用于操作中,并没有作用于浏览器上面
#显式等待
# elment = WebDriverWait(driver,10).until(
# EC.presence_of_element_located((By.ID,'form_email')) #某个元素被加载进来,就不等待了
#
# )
# print(elment)
#
# time.sleep(1)
#
# driver.quit()
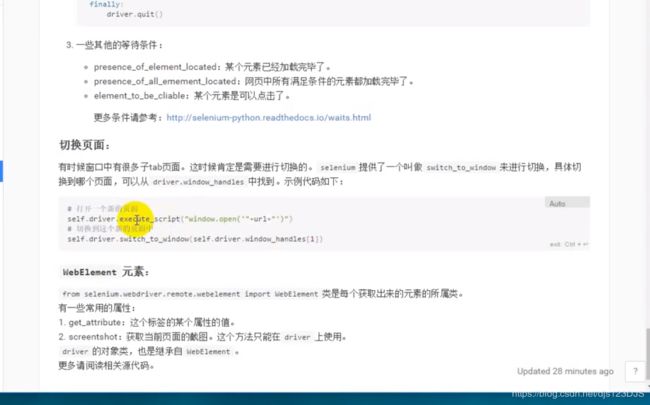
#打开多个页面,如打开百度后又打开豆瓣
# driver.get("https://www.baidu.com/")
# driver.execute_script("window.open('https://www.douban.com/')")#主要是这个
# print(driver.window_handles) #打引有多少个窗口
# driver.switch_to_window(driver.window_handles[1]) #里面装的是窗口句柄,切换到第二个窗口,[1]和索引一样
# #如果想爬取那个页面就用switch_to_window切换过去,driver 才会爬取
# print(driver.current_url) #当前url,就是浏览器所在的url
#设置代理ip
# option = driver.ChromeOptions()
# option.add_argument("--proxy-server=http://60.17.239.207:31032")
# driver(chrome_options=option)
# driver.get("http://httpbin.org/ip")
driver.get("https://www.baidu.com/")
print(driver.find_element_by_id("su").get_attribute("value")) #打印属性的值


#_author:'DJS'
#date:2018-11-20
import requests
from selenium import webdriver
import time
driver = webdriver.Chrome() #实例化浏览器
#response = driver.get('http:www.baidu.com') #发送请求
#进行截屏
#driver.save_screenshot("./baidu.png")
#设置窗口的大小
#driver.set_window_size(1800,1900)#宽和高
#最大化窗口
#driver.maximize_window()
#元素定位
# driver.find_element_by_id("kw").send_keys("python") #id是百度输入框的id,send_keys 是往里面输入文本
# driver.find_element_by_id("su").click() #click是点击
#获取cookies
# cookies = driver.get_cookies()
# print(cookies)
# print("*"*100)
# cookies = {i["name"]:i["value"] for i in cookies} #列表推导式是去列表里面的name ,和value,然后转换成字典
# print(cookies)
#获取html字符串
#print(driver.page_source) #这个是属性,因为他是个名词,方法有()的,
# 这个得到的是浏览器的elements的内容,因为他是浏览器请求的,不是当前url的响应
#打印当前url的地址,如果有click的,是click后的地址
# print(driver.current_url)
# driver.close()#退出当前页面
#登录豆瓣
driver.get("https://www.douban.com/")
driver.find_element_by_id("form_email").send_keys("1233455")
driver.find_element_by_id("form_password").send_keys("21454365")
#登录的时候遇到验证码可以设置时间长一点,自己手工输入
#识别验证码
image_url = driver.find_element_by_id("验证码id").get_attribute("src")
image_content = requests.get(image_url).content
print("识别验证码成功",image_content)
#输入验证码
driver.find_element_by_id("输入验证码的id的框").send_keys(image_content)
time.sleep(5)
driver.find_element_by_class_name("bn-submit").click() #点击登录
#获取cookies
cookies = {i["name"]:i["value"] for i in driver.get_cookies()}
time.sleep(3)
driver.quit()
#_author:'DJS'
#date:2018-11-20
import time
from selenium import webdriver
driver = webdriver.Chrome()
# driver.get("url")
# ret1 = driver.find_elements_by_xpath("写xpath的表达式获取数据") #elements 有s的是获取多个数据
# #这里返回的是列表
# for i in ret1:
# print(i.find_element_by_xpath("xpath").text) #获取文本,写在后面,不能写elements,写就是列表了
# #在selenium里面写xpath和平时写xpath是不同的,获取文本,属性那些东西要写在后面的
# print(i.find_element_by_xpath("xpath").get_attribute("href"))
#
# driver.find_element_by_link_text()
# print(ret1)
# driver.get("https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0x8bd2e5970002c76c&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=7&rsv_sug1=6&rsv_sug7=101&rsv_t=7c69GY%2BfBUyA1OS%2Fs2WOZ3bqYXxAhON89QI2kQdf4NqzmGnLv3hVBkKnrwKpyUh4ajVI&rsv_sug2=0&inputT=2139&rsv_sug4=2892&rsv_sug=2")
# #那个url已经放到driver里面了,可以直接调用driver的方法获取想要的数据
# ret = driver.find_element_by_link_text("下一页>").get_attribute("href")
# #seleunm会自动帮你补全url地址
# #find_element返回的是一个元素,find_elements返回发是一个列表
# ret1 = driver.find_element_by_partial_link_text("下一页").get_attribute("href")
# print(ret)
# print(ret1)
#登录qq邮箱
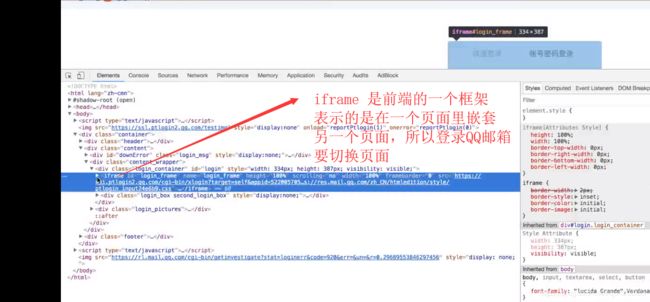
# driver.get("https://mail.qq.com/")
# driver.switch_to_frame("login_frame") #有些页面是用iframe进行嵌套的,所以要调用switch_to_frame进行切换到那个页面
# driver.find_element_by_id("switcher_plogin").click()
# time.sleep(1)
# driver.find_element_by_id("u").send_keys("邮箱号")
# time.sleep(1)
# driver.find_element_by_id("p").send_keys("密码")
# time.sleep(1)
# driver.find_element_by_id("p_low_login_enable").click()
# time.sleep(1)
# driver.find_element_by_id("login_button").click()
# time.sleep(3)
# driver.quit()
#bibi翻页 开始请求的时候程序是等到页面加载完后再找数据的,但是翻页的时候程序是立马找数据的
#他不会等到数据加载完再找,所以翻页的时候要设置超时时间,让数据加载完,程序才可以找到数据
driver.get("https://www.bilibili.com/v/douga/voice/?spm_id_from=333.5.b_646f7567615f766f696365.2#/")
print(driver.find_element_by_xpath("//button[@class='nav-btn iconfont icon-arrowdown3']").text)
# 注意element得到的是一个元素,elements得到的是一个列表
# 翻页
driver.find_element_by_xpath("//button[@class='nav-btn iconfont icon-arrowdown3']").click()
#等待页面的加载
time.sleep(3)
print(driver.find_element_by_xpath("//button[@class='nav-btn iconfont icon-arrowdown3']").text)
driver.quit()