Linux内核UDP收包为什么效率低?能做什么优化?
现在很多人都在诟病Linux内核协议栈收包效率低,不管他们是真的懂还是一点都不懂只是听别人说的,反正就是在一味地怼Linux内核协议栈,他们的武器貌似只有DPDK。
但是,即便Linux内核协议栈收包效率真的很低,这是为什么?有没有办法去尝试着优化?而不是动不动就DPDK,一窝蜂跟上去的想法,大部分都是很low的想法。
再次重申,我不写技术文档,我也不分析源码,本文只是一个思考的总结,但凡是思考,那必然是主观的,不图精确,甚至不图正确。
我们从最开始说起。
Linux内核作为一个通用操作系统内核,脱胎于UNIX那一套现代操作系统理论。
但一开始不知道怎么回事将网络协议栈的实现塞进了内核态,从此它就一直在内核态了。既然网络协议栈的处理在内核态进行,那么网络数据包必然是在内核态被处理的。无论如何,数据包要先进入内核态,这就涉及到了进入内核态的方式:
- 外部可以从两个方向进入内核-从用户态系统调用进入或者从硬件中断进入。
也就是说,系统在任意时刻,必然处在两个上下文中的一个:
- 进程上下文
- 中断上下文 (在非中断线程化的系统,也就是任意进程上下文)
收包逻辑的协议栈处理显然是自网卡而上的,它显然是在中断上下文中,而数据包往用户进程的数据接收处理,显然是在应用程序的进程上下文中, 数据包通过socket在两个上下文中被转接。
在socket层的数据包转接处,必然存在着一个队列缓存,这是一个典型的 生产者-消费者 模型,中断上下文的终点作为生产者将数据包入队,而进程上下文作为消费者从队列消费数据包:
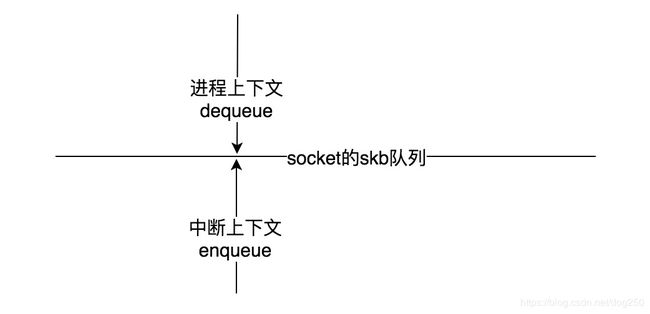
非常清爽的一个图,这个图是 两个上下文接力处理协议栈收包逻辑的必然结果 ,让我们加入一些实际必须要考虑的问题后,我们会发现这幅图并不是那么清爽,然后再回过头看如何来优化。
既然两个上下文都要在任意可能的时刻操作同一个socket进行数据包的转交,那么必须有一个同步机制保护socket元数据以及数据包skb本身。
由于Linux内核中断,软中断可能处在任意进程上下文,唯一的同步方案几乎就是spinlock了,于是,真正的图示应该是下面的样子:
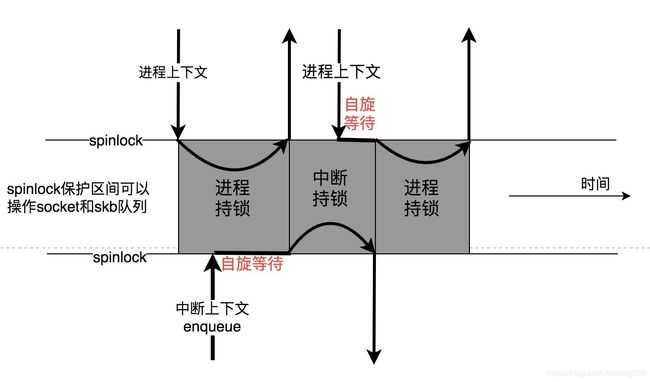
现在可以说,类似上面的这种这种保护是非常必要的,特别是对于TCP而言。
我们知道,TCP是基于事务的有状态传输协议,而且携带复杂的流控和拥塞控制机制,这些机制所依托的就是socket当前的一些状态数据,比如inflight,lost,retrans等等,这些状态数据在发包和接收ACK/SACK期间会不断变化,所以说:
- 在一个上下文完成一次事务传输之前,必须锁定socket状态数据。
比方说发包流程。数据包的发送可以出现在两个上下文中:
- 进程上下文:系统调用触发的发包。
- 中断上下文:ACK/SACK触发的发包。
任何一个上下文的发包过程必须被TCP协议本身比如拥塞控制,流量控制这些所终止,而不能被中途切换到另一个上下文中,所以必须锁定。
问题是,上图中的锁定是不是太狠了些,中断上下文自旋时间完全取决于进程上下文的行文,这不利于软中断的快速返回,极大地降低了系统的响应度。
于是,需要把锁的粒度进行细分。Linux内核并没有在横向上将锁的粒度做划分,而是在纵向上,采用两个层次的锁机制:
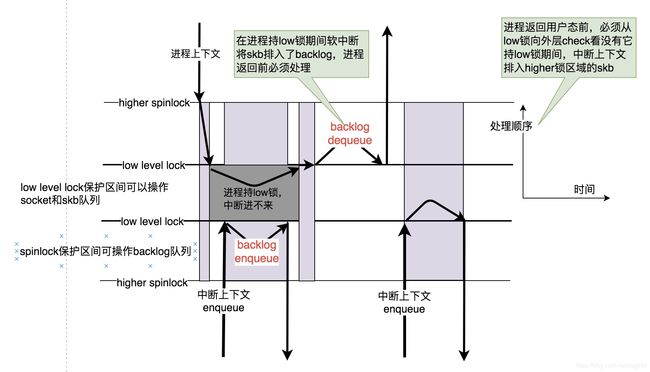
我们看到的Linux内核在处理收包逻辑时的backlog,其实抽象出来就是上面的二级锁,它是不是很像Windows的IRQL机制呢?伴随着APC,DPC,你可以把暂时由于高level的IRQL阻滞而无法执行的逻辑放入DPC:
- 由于进程上下文对socket的low锁占有,中断上下文将skb排入次level的backlog队列,当进程上下文释放low锁的时候,顺序执行次level被排入的任务,即处理backlog中的skb。
事实上这是一种非常常见且通用的设计,除了Windows的IRQL,Linux中断的上半部/下半部也是这种基于思想设计的。
前面说了,TCP的一次事务可能非常 复杂耗时 ,并且必须一次完成,这意味着期间必须持有socket low锁,以发包逻辑 tcp_write_xmit 函数为例,其内部循环发包,直到受到窗口限制而终止,每一次tcp_transmit_skb返回耗时3微秒~5微秒,平均4微秒,以每次发送4个包为例,在这期间,若使用spinlock,那么中断上下文的收包路径将自旋16微秒,16微秒对于spinlock而言有点久了,于是采用两级的lock机制,非常有效!
backlog队列机制有效降低了中断上下文的spin时延,提高了系统的响应度,非常不错。
但问题是,UDP有必要这样吗?
首先,UDP是无状态的,收包和发包都无需事务,协议栈对UDP的处理,从来都是单个报文粒度的,因此只需要保护唯一的socket接收队列即可,即 sk_receive_queue 。
enqueue(skb, sk)
{
spin_lock(sk->sk_receive_queue->lock);
skb_queue_tail(sk->sk_receive_queue, skb);
spin_unlock(sk->sk_receive_queue->lock);
}
sk_buff dequeue(sk)
{
spin_lock(sk->sk_receive_queue->lock);
skb = skb_dequeue(sk->sk_receive_queue);
spin_unlock(sk->sk_receive_queue->lock);
return skb;
}
需要保护的接收队列操作区间都是指令级别的时延,采用一把单一的 sk_receive_queue->lock 足矣。
确实,在Linux 2.6.25版本内核之前,就是这么干的。而自从2.2版本内核,TCP就已经采用二级锁backlog队列了。
然而,在2.6.25版本内核中,Linux协议栈的UDP收包路径,转而采用了两层锁的backlog队列机制,和TCP一样的逻辑:
low_lock_lock(sk)
{
spin_lock(sk->higher_level_spin_lock); // 热点!
sk->low_lock_owned_by_process = 1;
spin_unlock(sk->higher_level_spin_lock);
}
low_lock_unlock(sk)
{
spin_lock(sk->higher_level_spin_lock);
sk->low_lock_owned_by_process = 0;
spin_unlock(sk->higher_level_spin_lock);
}
udp_rcv(skb) // 中断上下文
{
sk = lookup(...);
spin_lock(sk->higher_level_spin_lock); // 热点!
if (sk->low_lock_owned_by_process) {
enqueue_to_backlog(skb, sk);
} else {
enqueue(skb, sk);// 见上面的伪代码
update_statis(sk);
wakeup_process(sk);
}
spin_unlock(sk->higher_level_spin_lock);
}
udp_recv(sk, buff) // 进程上下文
{
skb = dequeue(sk); // 见上面的伪代码
if (skb) {
copy_skb_to_buff(skb, buff);
low_lock_lock(sk);
update_statis(sk);
low_lock_unlock(sk);
dequeue_backlog_to_receive_queue(sk);
}
}
显然这非常没有必要。如果你有多个线程同时操作一个UDP socket,将会直面这个热点,但事实上,你很难遭遇这样的场景,如果非要说一个,那么DNS服务器可能首当其中。
之所以在2.6.25版本内核引入了二级锁backlog队列,大致是考虑到UDP需要统计内存全局记账,以防UDP吃尽系统内存,可以review一下 sk_rmem_schedule 函数的逻辑。而在2.6.25版本内核之前,UDP的内存使用是不记账的,由于UDP本身没有任何类似流控,拥塞控制之类的约束机制,很容易被恶意程序将系统内存吃尽。
因此,除了sk_receive_queue需要保护,内存记账逻辑也是需要保护的,比如累加当前skb对内存的占用到全局数据结构。但即便如此,把这些统计数据的更新都塞入到spinlock的保护区域,也还是要比两级lock要好。
在我看来,之所以引入二级锁backlog机制来保护内存记账逻辑,这是在 借鉴 TCP的代码,或者说 抄代码 更直接些。这个携带backlog队列机制的UDP收包代码存在了好多年,一直在4.9内核才终结。
事实上,仅仅下面的逻辑就可以了:
enqueue(skb, sk)
{
spin_lock(sk->sk_receive_queue->lock);
skb_queue_tail(sk->sk_receive_queue, skb);
update_statis(sk);
spin_unlock(sk->sk_receive_queue->lock);
}
sk_buff dequeue(sk)
{
spin_lock(sk->sk_receive_queue->lock);
skb = skb_dequeue(sk->sk_receive_queue);
update_statis(sk);
spin_unlock(sk->sk_receive_queue->lock);
return skb;
}
udp_rcv(skb) // 中断上下文
{
sk = lookup(...);
spin_lock(sk->higher_level_spin_lock);
enqueue(skb, sk);// 见上面的伪代码
spin_unlock(sk->higher_level_spin_lock);
}
udp_recv(sk, buff) // 进程上下文
{
skb = dequeue(sk); // 见上面的伪代码
if (skb) {
copy_skb_to_buff(skb, buff);
}
}
简单直接!Linux内核的UDP处理逻辑在4.10版本也确实去掉了两级的lock。恢复到了2.6.25内核版本之前的逻辑。
上面的优化带来了可观的性能收益,但是却并不值得炫耀。
因为上面的优化更像是解决了一个bug,这个bug是在2.6.25版本内核因为借鉴TCP的backlog实现而引入的,而事实上,UDP并不需要这种花哨的backlog逻辑。所以说,上面的效果并非优化而带来的效果,而是解了一个bug带来的效果。
但是为什么迟至4.10版本才发现并解决这个问题的呢?
我想这件事可能跟QUIC有关。
用得少的逻辑自然就不容易发现问题,这就好比David Miller在2.6版本内核引入IPv6实现的那几个bug,就是因为IPv6用的人少,所以一直在很晚的4.23+版本内核才被发现被解决。对于UDP,一直到2.6.24版本其实现都挺好,符合逻辑,2.6.25引入的二级锁bug同样是因为UDP本身用的少而没有被发现。
在QUIC之前,很少有那种有来有回的持续全双工UDP长连接,基本都是request/response的oneshot类型的连接。然而QUIC却是类似TCP的全双工协议,在数据发送端持续发送大块数据的同时,伴随着的是接收大量的ACK报文,这显然和TCP一样,也是一种反馈控制的方式来驱动数据的发送。
QUIC是有确认机制的,但是处理确认却不是在内核进行的,内核只是一个快速将确认包收到用户态QUIC处理进程的一个通路,这个通路越快越好!
也就是说,QUIC的ACK报文的接收效率会影响其数据的发送效率。
随着QUIC的大规模部署,人们才开始逐渐关注其背后UDP的收包效率问题。
摆脱了二级锁的backlog队列之后,仅仅是为UDP后续的优化扫清了障碍,这才是真正刚刚开始。摆在UDP的内核协议栈收包效率面前的,有一个现成的靶子,那就是DPDK。
挺烦DPDK的,说实话,被人天天说的东西都挺烦。不过你得先把内核协议栈的UDP性能优化到接近DPDK,再把这种鄙视当后话来讲才更酷。
由于UDP的处理非常简单,因此实现一个能和DPDK对接的UDP用户态协议栈则并不是一件难事。而TCP则相反,它非常复杂,所以DPDK很少有完整处理TCP端到端逻辑的,大多数都只是做类似中间节点DPI这种事。目前都没有几个好用的基于DPDK的TCP实现,但是UDP实现却很多。
DPDK的伪粉丝拿UDP说事的,比拿TCP说事,成本要低很多。
好吧,那为什么DPDK处理UDP收包效率那么高?
答案很简单, DPDK是在进程上下文轮询接收UDP数据包的! 也就是说,它摆脱了两个问题:
- 进程上下文和中断上下文操作共享数据的锁问题。
- 进程上下文和中断上下文切换导致的cache miss问题。
这两点其实也就是 “为什么内核协议栈性能干不过用户态协议栈” 的要点。当然,Linux内核协议栈无法摆脱这两点问题,也就回答了本文的题目中的第一个问题, “Linux内核UDP收包为什么效率低?” 。
不同的上下文异步操作同一份数据,锁是必不可少的。关于锁的话题已经烂大街了。
现在仅就cache来讨论,中断上下文和进程上下文之间的切换,也有一个明显的case:
- 中断上下文中修改了socket的元统计数据,该修改会表现在cache中,然而当其wakeup该socket的处理进程后,切换到进程上下文的recv系统调用,其也或读或写这个统计数据,伴随着cache的flush以及cache的一致性同步。
如果这些操作统一在进程上下文中进行,cache的利用率将会高效很多。当然,回到UDP收包不合理的backlog队列机制,其实backlog本身存在的目的之一,就是为了让进程上下文去处理,以提高cache的利用率,减少不必要的flush。然而,初衷未必能达到效果,在传输层用backlog将skb推给进程上下文去处理,已经太晚了,何必不再网卡就给进程上下文呢?就像DPDK那样。
其实Linux内核社区早就意识到了这两点,早在3.11版本内核中引入的busy poll机制就是为了解决锁和切换问题的。busy poll的思想非常简单,那就是:
- 不再需要软中断上下文往接收队列里“推”数据包,而改成自己在进程上下文里主动从网卡上“拉”数据包。
落实到代码上,那就是在进程上下文的recvmsg函数中直接调用napi的收包函数,从ring buffer里拿数据,自己调用netif_receive_skb。
如果busy poll总能执行,它总是能拉取到自己下一个需要的数据包,那么这基本就是DPDK的效率了,然而和DPDK一样,这并不是一个统一的解决方案,轮询固然对于收包有收益,但中断是不能丢的,用CPU的自旋轮询换取收包效率,这买卖代价太大,毕竟Linux内核并非专职收包的。
当然了,也许内核态实现协议栈本身就是一种错误,但这个话题有点跑偏,毕竟我们就是要优化内核协议栈的,而不是放弃它。关于这个话题,推荐一篇好文:
千万级并发实现的秘密:内核不是解决方案,而是问题所在! http://highscalability.com/blog/2013/5/13/the-secret-to-10-million-concurrent-connections-the-kernel-i.html
现在,我们不能指望busy poll担当所有的性能问题,仍然要依靠中断。既然依靠中断,锁的问题就是优化的重点。
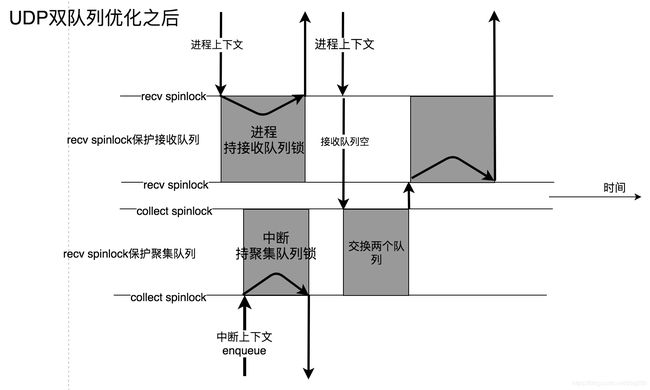
以双核CPU为例,假设CPU0专职处理中断,而收包进程则绑定在CPU1上,我们很快能意识到, CPU0和CPU1对于每一个skb的enqueue和dequeue均在争抢socket的sk_receive_queue的spinlock 。
优化措施显而易见, 将多个skb聚集起来,一次性入接收队列 。显然,这需要两个队列:
- 维护聚集队列:由中断上下文将skb推入该队列。
- 维护接收队列:进程上下文从该队列拉取skb。
- 接收队列为空时,交换聚集队列和接收队列。
这样,同样在上述双核CPU的情况下,只有在上面的第3点的操作中,才需要锁保护。
考虑到机器的CPU并非双核,可能是任意核,收包进程也未必绑定任何CPU,因此上述每一个队列均需要一把锁保护,无论如何, 和单队列相比,双队列情况下,锁的竞争减少了一半!
collect_enqueue(skb, sk)
{
spin_lock(sk->sk_collect_queue->lock);
skb_queue_tail(sk->sk_collect_queue, skb);
update_statis(sk);
spin_unlock(sk->sk_collect_queue->lock);
}
sk_buff recv_dequeue(sk)
{
spin_lock(sk->sk_receive_queue->lock);
skb = skb_dequeue(sk->sk_receive_queue);
update_statis(sk);
spin_unlock(sk->sk_receive_queue->lock);
return skb;
}
udp_rcv(skb) // 中断上下文
{
sk = lookup(...);
spin_lock(sk->higher_level_spin_lock);
collect_enqueue(skb, sk);// 仅仅往聚集队列里推入。
spin_unlock(sk->higher_level_spin_lock);
}
udp_recv(sk, buff) // 进程上下文
{
if (empty(sk->sk_receive_queue)) {
spin_lock(sk->queues_lock);
swap(sk->sk_receive_queue, sk->sk_collect_queue);
spin_unlock(sk->queues_lock)
}
skb = recv_dequeue(sk); // 仅仅从接收队列里拉取
if (skb) {
copy_skb_to_buff(skb, buff);
}
}
如此一来,双队列解除了中断上下文和进程上下文之间的锁竞争。
来看一下对比图示:
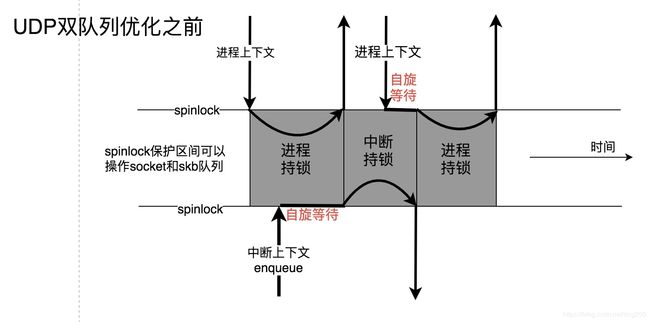 引入双队列后:
引入双队列后:
即便已经很不错了,但是:
- 中断上下文中不同CPU可能会收到同一个socket的skb,CPU依然会在聚集队列的锁上蹦跶。
- 不同的CPU上的进程也可能会处理同一个socket,本意是合作,却需要接收队列的锁来将其操作串行化。
没办法,通用的操作系统内核只能做到这里了,如果要解决以上的问题,就需要按照任何和角色明确绑CPU核心了,然而这也就不再是通用的内核了。最终,你会在内核里闻到DPDK的腐臭味,超级恶心。
对了,我暂且将双队列区分为了 聚集队列 和 接收队列 ,更好的名字可能是 backlog队列 和 接收队列 。中断上下文总是操作backlog队列,而进程上下文在接收队列为空时,交换backlog队列为接收队列。然而,backlog队列这个名字在我看来非常臭名昭著,所以,暂且不用它了。
…
我想本文应该就要结束了,确实没有源码分析,事实上,我觉得我写的这篇要比下面的这种有意思的多,然而可能在网上能找到的基本都是这种 非常详细的源码分析:
...
bh_lock_sock(sk); // 锁定住sk
if (!sock_owned_by_user(sk)) // 判断sk是不是被用户进程所拥有,如果没有被拥有的话。
rc = __udp_queue_rcv_skb(sk, skb); // 直接调用__udp_queue_rcv_skb
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) { //否则调用sk_add_backlog将skb放入backlog
bh_unlock_sock(sk); // 如果失败,解锁sk,直接丢包
goto drop;
}
bh_unlock_sock(sk); // 解锁sk
return rc; // 返回rc
...
哈哈…
我为什么没有谈UDP的GRO,LRO机制,因为太不通用了。但是另一方面,如果应用程序加以稍微支持,UDP的GRO,LRO将会带来非常可观的收益,别忘了,内核只是UDP报文的一个通路即可,既然是通路,它便不包含处理逻辑,越快通过,越好。如果你在乎高吞吐,那么就GRO呗,如下:
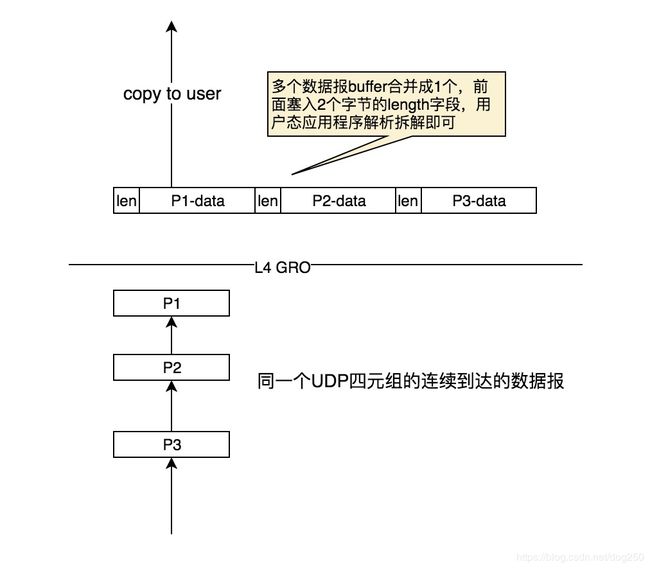
UDP的通用L4 GRO相当于一个非常简单的5层协议,应用程序按照len字段稍加解析拆分即可,这将极大减少系统调用的次数,减少上下文切换带来的cache miss损耗。
我要花点篇幅说点关于 “写XX” 的话题。这并没有跑题,只是本文题目取得并不恰当,毕竟这不是一篇单纯讲UDP协议的文档。
关于到底写什么才牛逼,这里有个鄙视链,在程序员看来,写代码的最牛逼,程序员往往看不起写文档写ppt的,也看不起写博客的和写技术书的,然而在经理看来,写代码的又是最low,比不过写ppt的。
但这种程序员或者经理的视角伸展出来的鄙视链,眼光未免太狭隘太局限了,我先推而广之。
任何文字的东西,除了职业本身就是诉诸文字的作者之外,其作者都可能会被专业的人看不起。职业诉诸文字的作品,只有文学作品。
也就是说,除了诗人写诗,文学家写小说或者散文这些之外,别的任何东西写成文字,都会被专门做那件事的人无视甚至鄙视。甚至就说文学本身,一个作家牛不牛逼,往往要看他是不是写过诗(最短),或者是不是写过小说(最长),散文之类的很难成大家,往往有鸡汤文嫌疑。
并非只因为这是个 唯作品论 的时代。而是一直如此。
专业的人就得能胜任专业的事,一个修下水道的天天不去修下水道而去写文章介绍自己修下水道修的多么好,你觉得他是专业的吗?
搞音乐的无法谱曲,即便再会作词写音乐理论也不行;将军不能在战场胜利搞出再牛逼的兵法也是纸上谈兵;数学家完不成个伟大证明没个可以用公式表达的推论猜想啥的,再牛逼的文字表述也只能当个老师;程序员也一样,没代码,啥也不是。
只有诗人,文学家的作品是文字本身。只有他们写一些东西看起来才是理所应当的。
我自己就特别喜欢写点东西,技术的,哲学的,历史的,各行各业吐槽的…但我并不是文学家,我的职业是程序员,我的爱好是一切可以思考的东西,无论怎样,我也不是搞文学的,所以无论从哪头看,我都是被鄙视的。
所以我把我写的文章自己看成是 思考的结果。 它们不是原理分析,不是源码分析,不是科普,不是百科,仅仅是我思考的结果,我每天上下班路上,我每天入睡前思考的结果。
我为什么不写源码分析?
因为我感觉很多写源码分析的都是吹水待价而沽的,当前出一本源码分析的书成本太低了,所以大家都去写这种源码分析,无非就是想给自己挣个名气以后好捞金罢了, 这人是XXX的作者 , 这人写过书 … 然后大公司就会联系到他,或者一些可以赚钱的平台就会联系到他,仅此而已吧。我当然要避开这个群体。
我来说下写源码分析需要做什么。
什么都不需要做,只要懂编程语言语法,能看懂代码的语法即可,然后给代码写注释,源码分析就完成了,你甚至都不需要懂代码的逻辑,源码分析可以这么写:
if (!sock_owned_by_user(sk)) // 判断sk是不是被用户进程所拥有,如果没有被拥有的话。
rc = __udp_queue_rcv_skb(sk, skb); // 直接调用__udp_queue_rcv_skb
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) { //否则调用sk_add_backlog将skb放入backlog
bh_unlock_sock(sk); // 如果失败,解锁sk,直接丢包
只要是命名良好的源代码,只需要把代码翻译成中文即可。
而国内几乎所有的技术书籍都可以冠以 “深入理解” , “深度解析” 之名,实则就是类似上面的 源码翻译。 只能呵呵。
那么,我为什么不给Linux内核社区提交patch呢?
因为我没有兴趣,而且嫌麻烦,也没那时间和别人撕逼。deep into Linux内核这只是为了赚一份工资养家糊口,但既然工作日一整天大部分时间都在和Linux内核打交道,那么Linux内核也纳入了我的思考范围,仅此而已,这并不意味着它会占据我的一切时间,而且我本无意在这个领域登堂入室,这只是一个职业,如果我的工作内容不包括向社区提交patch,我个人是不会做的,真的是太麻烦,而且需要遵守一定的规范,这相当于是 另一份不拿工资的工作。 但偶尔,我也会写一些patch单方面公开,这种公开没有任何成本,纯粹是兴趣,觉得好玩,我想怎么做就怎么做,发到博客,发到知乎文章,扔到论坛,甚至发到微信朋友圈,没有人会要求我必须如何如何,更不会有人要求我必须采用某种格式。
和写源码分析待价而沽使我不得开心颜一样,我并不认为写patch提交给社区能让我更快乐。我只是思考,仅此而已,无需被承认,所以不必想方设法为外人知。
专业领域内,以IT互联网行业为例,真正的牛人几乎不写书,不写文章,更不会写什么源码分析,真正的牛人留下的是代码而不是逼逼,除了代码他们没有时间干别的,牛人不是老师,所以他们不会有时间和精力来思考如何把一种技能教给别人。
我不是牛人,所以我有时间写文章,但我也不是欺世盗名待价而沽之人,所以我不写毫无含金量的源码分析,我只是一个在路上思考的人,所以我写的东西都是思考的总结,不精确,甚至不正确,但这就是了。
比如浙江温州皮鞋湿,比如国之重器报喜鸟,没有意义,但这就是了。
浙江温州皮鞋湿,下雨进水不会胖。