github
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 20 |
| Estimate | 估计这个任务需要多少时间 | 35 | 20 |
| Development | 开发 | 850 | 750 |
| Analysis | 需求分析(包括学习新技术) | 60 | 30 |
| Design Spec | 生成设计文档 | 30 | 10 |
| Design Review | 设计复审 | 15 | 20 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 25 | 80 |
| Design | 具体设计 | 100 | 50 |
| Coding | 具体编码 | 350 | 300 |
| Code Review | 代码复审 | 80 | 160 |
| Test | 测试(自我测试,修改,提交修改) | 200 | 220 |
| Reporting | 报告 | 60 | 160 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结并提出过程改进计划 | 40 | 60 |
| 合计 | 945 | 930 |
计算模块接口的设计与实现过程
解题思路
示例:2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
准备工作:
1.获取省市区数据一份cpca的省市区csv因为只能使用一个py文件,将其输出后采用万能的打表法,获得address dict
2.寻找api大作战。。高德天下第一!
正式实施:
1.利用正则匹配11位数字,把11位电话单独取出保存
2.提取第一位难度保存,删除感叹号和句号
3.提取逗号前面的名字,删除逗号,得到结果福建省福州市鼓楼区鼓西街道湖滨路110号湖滨大厦一层
4.根据已有的address dict匹配省市区级,采用的方法为将输入的str一个字符一个字符读入,直到遍历搜索到表中存在的元素
5.因为乡镇级不会省去后缀,使用关键词镇、乡、街道、办事处等匹配,路级同理,使用街、弄、大道等匹配,门牌号的关键词用号、牌来搜索,剩下的内容则是最低级的地址
6.附加题只能调用天下第一的高德地图api来进行补全了,这里采用正地理编码和反地理编码双重检测,由地址->经纬度,经纬度->地址,基本上都能找到,其实也就是懒得找更详细的api了。
7.输出!
实现方法
| 类外函数 | 功能 |
|---|---|
| find_it | 利用正则找到电话号码 |
| geocode(regeocode) | 利用url现场获取高德地图数据 |
| 类内方法 | 功能 |
|---|---|
| find | 分割姓名、难度、电话号码和剩下的字符串 |
| search_address | 分割省市区前三级 |
| define_address | 输出 |
| nandu_one(two\three) | 根据难度进行不同的分割 |
| fill_province(city,area....)_address | 根据关键词检索(包括缺失“省”时的补充) |
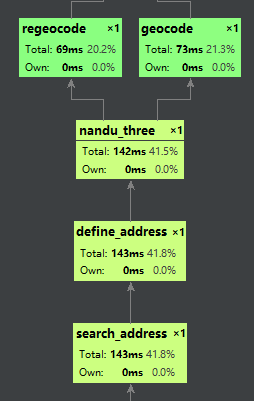
难度一二流程图

难度三流程图

Tips:这里使用了pycharm的profile来画流程图,中间加了一些sleep不然看不见某些步骤
代码质量检测

Tips:这里用的是codacy的质量检测,不容易,真的不容易,删掉了无数个没用的空格,把类内无用函数提出类,删掉没用的import,以后真的要注意代码规范和格式的问题。可惜这网站的折线图只能按天数来画,不然就能看到从刚开始的10+个报错到0。真的不容易。
易错点(踩过的坑)
1.数据有可能缺少省市,如福建福州这种情况,无法匹配cpca表中的结果,如福建省,在每一步判断的时候加上关键字省和市再进行搜索
2.在寻找关键字然后从原句中删除相应字段的时候,注意只要删除一次
3.在匹配门牌号时出现特殊情况:2!王老五,福建福州12345678910市工业路福州图书馆20号楼111。在匹配“号”时提前匹配,多加一层判断当前带号的字符串前面是否还有中文
4.直辖市的“市”字需要去掉,不然评测错误
计算模块接口部分的性能改进
代码性能测试
对还是它,pycharm的profile,真香,简单粗暴。最开始做的优化自然是提前跳出遍历循环这些了,然后打表法内采用最愚蠢的去重法和删掉一些没用的。为了去除等待输入的时间,这里直接赋初值为3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.进行测试
然后最高的就是request环节了,url的请求和request的__init__是最花时间的,显然这环节的耗时就看一手fzu给不给力了。仔细一想,那咋办嘛。顺便一提就是其实最开始的打表并不占太多时间,因为就3000多个数据

计算模块部分单元测试展示
覆盖率
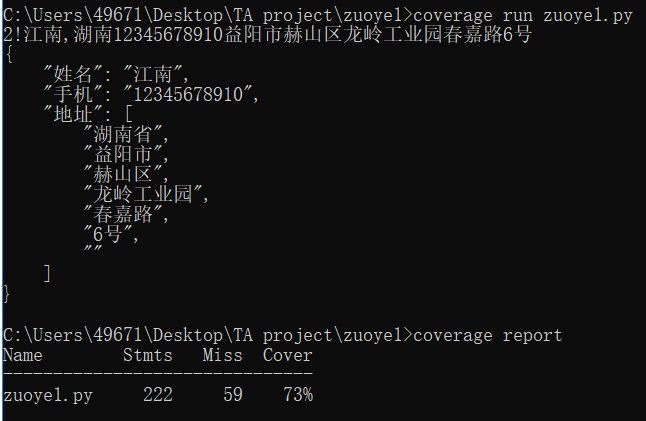
这里采用了coverage库来检测coverage博客园教学显然覆盖率低的可怕,主要是因为在后三级中的关键词检索中我手动加了许多种可能,等于每次搜索都会多一次if的判断,暂时没想到有什么好的方法解决,毕竟中国地名大千世界。像这种

计算模块部分异常处理说明
看到这才突然意识到还有异常处理这种东西。emmmmmmmmm。于是补了个各种输入报错的情况上去,然后看了下后面的代码,恩,很不错,不会异常,大概或许。
try:
matchstr=r'(\d{11})'
phone_number=findit(matchstr,all_x)
nandu=all_x[0]
if (nandu<'0' or nandu>'3'):
raise AttributeError('木有难度...')
gantanhao=all_x[1]
if (gantanhao!='!'):
raise AttributeError('木有感叹号...')
x_nandu=all_x.replace(str(nandu)+'!','')
dou_pos=x_nandu.find(',')
if(dou_pos==-1):
raise AttributeError('木有逗号...')
name=x_nandu[:dou_pos]
if(name==''):
raise AttributeError('木有名字...')
x_name=x_nandu.replace(str(name)+',','')
res_x=x_name.replace(str(phone_number),'')
res_x=res_x.replace(".",'')
except AttributeError:
print("输入格式不符合规范")
sys.exit(0)
#!黎剖奕,广东省珠海金湾区三灶12580镇乐康街一巷11号三灶镇海澄村委会.
#1黎剖奕,广东省珠海金湾区三灶镇乐康街一巷11号三灶镇海澄村委会13614572468.
#1!,广东省珠海金湾区三灶镇乐康街一巷11号三灶镇海澄村委会13614572468.
#1!黎剖奕广东省珠海金湾区三灶镇乐康街一巷11号三灶镇海澄村委会13614572468.
#以上均会报错:输入格式不符合规范历程总结
最开始做的时候我是不想引用api来做的所以找了个数据库(本来想爬,懒)然后附加题实在没法做,不甘心只能找api了,所以前面分割前三级的代码有大量的复制黏贴也就是相似内容,就打了很长时间,刚开始是完全没想到要做这么累的,因为代码写得太丑,就不贴了。不过以前基本没在意过这什么代码质量这种就只在乎性能,也算长了见识了,更多的是认识了中国的大好河山,打开浏览器随便一看就发现给我推荐了个地图数据库分析,最后一句,高德地图天下第一!