目录
- Spark学习笔记2——RDD(上)
- RDD是什么?
- 例子
- 创建 RDD
- 并行化方式
- 读取外部数据集方式
- RDD 操作
- 转化操作
- 行动操作
- 惰性求值
- RDD是什么?
Spark学习笔记2——RDD(上)
笔记摘抄自 [美] Holden Karau 等著的《Spark快速大数据分析》
RDD是什么?
弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)
- Spark 的核心概念
- 一个不可变的分布式对象集合
- 每个 RDD 都被分为多个分区运行在集群的不同节点上
- RDD 可以包含 Python、Java、Scala 中任意类型的对象(可以自定义)
在 Spark 中,对数据的所有操作不外乎 创建 RDD、转化已有 RDD 以及 调用 RDD 操作 进行求值。而在这一切背后,Spark 会自动将 RDD 中的数据分发到集群上,并将操作并行化执行。
例子
创建 RDD 的两种方式:
- 读取一个外部数据集
- 驱动器程序里分发驱动器程序中的对象集合(比如 list 和 set)
这里通过读取文本文件作为一个字符串 RDD:
>>> lines = sc.textFile("README.md")RDD 的两种操作:
- 转化操作(transformation):由一个RDD 生成一个新的RDD,例如筛选数据
- 行动操作(action):对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中
调用转化操作 filter() :
>>> pythonLines = lines.filter(lambda line: "Python" in line)调用 first() 行动操作 :
>>> pythonLines.first()
u'high-level APIs in Scala, Java, Python, and R, and an optimized engine that'@Notice
- “惰性计算”:RDD 只有在进行第一个 行动操作 时才会被计算1
- “持久化”:RDD默认会在每次行动操作时重新计算2,如果想要在多个行动操作中重复使用同一个 RDD ,需要对该 RDD 进行 “持久化”
把RDD 持久化3到内存中
>>> pythonLines.persist
>>> pythonLines.count()
3
>>> pythonLines.first()
u'high-level APIs in Scala, Java, Python, and R, and an optimized engine that' 创建 RDD
并行化方式
把程序中一个已有的集合传给 SparkContext 的 parallelize() 方法,这种方式需要把整个数据集先放到一台机器的内存中,故不常用
JavaRDD lines = sc.parallelize(Arrays.asList("pandas", "i like pandas")); 读取外部数据集方式
JavaRDD lines = sc.textFile("/path/to/README.md"); RDD 操作
转化操作
RDD 的转化操作是返回一个新的RDD 的操作,比如 map() 和 filter()
例程(Java)
展示日志文件中所有错误记录
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.List;
public class CountError {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("CountError");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD log = javaSparkContext.textFile(args[0]);
JavaRDD errorsRDD = log.filter(
new Function() {
public Boolean call(String x) {
return x.contains("ERROR");
}
});
List errors = errorsRDD.collect();
for (String output : errors) {
System.out.println(output);
}
javaSparkContext.stop();
}
} 日志文件内容
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...运行效果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class CountError ~/SparkTest2.jar ~/SparkTest2.log
...
19/09/10 16:33:10 INFO DAGScheduler: Job 0 finished: collect at CountError.java:20, took 0.423698 s
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
...例程(Python)
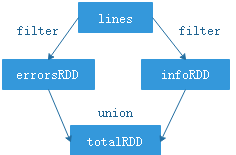
>>> lines = sc.textFile("/root/SparkTest2.log")
>>> errorsRDD = lines.filter(lambda lines: "ERROR" in lines)
>>> infoRDD = lines.filter(lambda lines: "INFO" in lines)
>>> totalRDD = errorsRDD.union(infoRDD)
>>> lines.count()
21
>>> errorsRDD.count()
4
>>> infoRDD.count()
17
>>> totalRDD.count()
21@Notice
转化操作可以操作任意数量的输入 RDD
Spark 会使用谱系图(lineage graph)来记录这些不同 RDD 之间的依赖关系,以此按需计算每个 RDD
@P.s.
也可以依靠谱系图在持久化的RDD 丢失部分数据时恢复所丢失的数据
行动操作
把最终求得的结果返回到驱动器程序,或者写入外部存储系统中的 RDD 操作
上文例程中的 count() 便是一个行动操作,另外还有 take() 、collect() 等操作
下面以 take() 为例,获取 union 后的 totalRDD 的前 10 条
>>> for line in totalRDD.take(10):print line
...
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
>>> @P.s.
程序把RDD 筛选到一个很小的规模单台机器内存足以放下时才可以使用 collect()
惰性求值
RDD 的转化操作都是惰性求值的,在被调用行动操作之前 Spark 不会开始计算
- 不应该把 RDD 看作存放着特定数据的数据集,而最好把每个 RDD 当作我们通过转化操作构建出来的、记录如何计算数据的 指令列表
- 把数据读取到 RDD 的操作也同样是惰性的
- 读取数据的操作也有可能会多次执行
如果创建 RDD 或转化 RDD 时就把文件中所有的行数都存储起来,会消耗大量存储空间,Spark 了解完整的操作链后,可以只计算结果真正需要的数据,例如行动操作为 first() 则只存储 “README.md” 中第一行 “Python”↩
如果不这样做也会导致重复创建 RDD 浪费存储空间↩
默认存储级别调用 persist() 和 cache() 是一样的↩