责任链模式是经典的GoF 23种设计模式之一,也许你已经了解这种模式。不管你是否熟悉,建议读者在阅读本文之前,不妨先思考下面三个问题:
(1) 如何用多种风格迥异的编程范式来实现责任链模式? (2) 能否让责任链上的结点多任务并发执行? (3) 能否把责任链部署到分布式环境下,分布在世界各地的多台计算机,通过某种方式构成一条责任链,协同工作,能否做到呢?
引言
责任链铁索连环 无模式的实现方式面向过程风格 面向对象风格OOP 1 解法一用模板方法模式实现责任链模式 2 解法二用策略模式实现责任链模式 函数式风格Functional Programming 1 解法三用一等公民函数替换策略模式实现责任链模式 2 解法四用偏应用函数实现责任链模式 21 替换Node类 22 为函数升阶函数的Curry化为更高阶的函数 23 为函数降阶偏应用函数 3 解法五用偏函数实现责任链模式 31 偏函数我不完美但我们很完美 32 用偏函数实现责任链模式 响应式风格Reactive Programming 1 响应式思维别拉进来推出去 2 解法六用Actor模型实现责任链模式 21 Actor模型简介 22 Akka一个支持高并发分布式计算消息驱动的Actor库 23 为责任链上的处理者结点定义Actor类 24 创建actor对象 25 连环计创建基于actor的责任链 26 如何礼貌地向别人提问题 27 对未来值的聪明响应我不理你但当你有结果的时候一定要告诉我 28 并发世界也有秩序 3 解法七用RXReactive eXtension响应式扩展实现责任链模式 4 两种响应式编程方式的比较 回顾与总结
本文对责任链模式给出7种不同实现方式,其中:
OOP(面向对象编程):有2种采用面向对象编程范式,即:
(1)用模板方法模式实现责任链模式(第3.1节)
(2)用策略模式实现责任链模式(第3.2节)
一种采用混合OOP和FP的编程范式,即:
(3)用一等公民函数替换策略模式实现责任链模式(第4.1节)
FP(函数式编程):有2种采用纯函数式编程范式,即:
(4)用偏应用函数实现责任链模式(第4.2节)
(5)用偏函数实现责任链模式(第4.3节)
RP(响应式编程):最后2种采用响应式编程范式,即:
(6)用Actor模型实现责任链模式(第5.2节)
(7)用RX响应式扩展实现责任链模式(第5.3节)
1. 责任链:铁索连环
某用户购买了一款软件,用了几天就crash,重要在数据丢失。用户很生气,后果很严重。于是打电话给软件公司客服投诉。客服如果不能解决,会问经理,若经理也不能解决或者认为不规他解决,会转给工程师解决,这样客服、经理、工程师就构成了一条责任链。
记用户反映在问题为Input,每个问题Input都用各自不同的业务值value(可由一个字符表示),用Scala代码描述为:
case class Input(value: Char)
记解答为输出Output,带字符串信息value。
case class Output(value: String)
温馨提示:Scala中的case类常用于定义数据类和消息事件。别小看上面这一行代码,它定义了很多东西:
(1)定义了类Output,实现序列化接口 (2)定义类里有个不可变成员value,类型为String (3)提供带参数的构造函数,参数为value,类型为String,实现方式是为不可变成员value赋值 (4)提供不可变成员value的get方法,方法名为value。 (5)覆盖toString方法并提供可读信息 (6)覆盖hashCode方法并实现 (7)覆盖equals方法并实现 (8)还有其他方法,如copy, apply, unapply…
若用Java写,要写很长的代码,如下:
public class Output implements Serializable { private final String value; public Output(String value) { this.value = value; } public String value() { return value; } @Override public String toString() { ... } @Override public int hashCode() { ... } @Override public boolean equals(Output that) { ... } 还有其他方法,如copy, apply, unapply... }
假设客服只负责处理业务值为a, w;处理问题在方式是返回信息:”Customer Service handles ” + 业务值。即:
def canHandleByCustomService(request: Input) = "aw" contains request.value
def handleByCustomService(request: Input) = Output("Customer Service handles " + request.value)
类似的,经理只负责处理业务值为b, w, z;工程师只负责处理业务值为c, z。即:
def canHandleByManager(request: Input) = "bwz" contains request.value def handleByManager(request: Input) = Output("Manager handles " + request.value) def canHandleByEngineer(request: Input) = "cz" contains request.value def handleByEngineer(request: Input) = Output("Engineer handles " + request.value)
2. 无模式的实现方式(面向过程风格)
根据前面描述,处理过程可由一系列条件分支来描述:
object NoDp { def handle(request: Input): Option[Output] = if (canHandleByCustomService(request)) { Some(handleByCustomService(request)) } else if (canHandleByManager(request)) { Some(handleByManager(request)) } else if (canHandleByEngineer(request)) { Some(handleByEngineer(request)) } else { None } }
返回值为Option类型,当有解答时为其子类Some并给出结果,否则是None。
这种实现方式虽然简单,但存在以下缺点:
扩展性差,扩展需要增加else if语句,违反开闭原则。
灵活性差,不能随意动态调整调用顺序。
给用户代码暴露太多细节,用户需要知道哪些人能处理哪些事,以及处理的顺序。
下面给出7种不同责任链模式在实现,都能解决以上问题。
3. 面向对象风格(OOP)
3.1 解法一:用模板方法模式实现责任链模式
定义责任链上在结点类:
abstract class HandlerNode
存在可变成员变量指向后续结点
var next: HandlerNode = _
处理过程就是能处理则处理,否则递归向后传:
@tailrec final def handle(request: Input): Option[Output] = { if (canHandle(request)) Some(doHandle(request)) else if (next == null) None else next handle request }
温馨提示:@tailrec表明该函数使用了尾递归优化。虽然不上加@tailrec,Scala编译器也会对任何可以尾递归优化的代码进行尾递归优化,但是加上@tailrec之后,如果这个函数不能做尾递归优化,那是编译不过的。有了@tailrec,妈妈再也不用担心这个函数能不能做了尾递归优化了。
上面在处理过程是个模板(用到模板方式模式),用到两个抽象方法canHandle和doHandle:
protected def canHandle(request: Input): Boolean protected def doHandle(request: Input): Output
客服,经理,工程师,属于不同处理结点,也就是继承HandlerNode类,并提供各自不同的实现:
class CustomerService extends HandlerNode { override protected def canHandle(request: Input): Boolean = canHandleByCustomService(request) override protected def doHandle(request: Input): Output = handleByCustomService(request) } class Manager extends HandlerNode { override protected def canHandle(request: Input): Boolean = canHandleByManager(request) override protected def doHandle(request: Input): Output = handleByManager(request) } class Engineer extends HandlerNode { override protected def canHandle(request: Input): Boolean = canHandleByEngineer(request) override protected def doHandle(request: Input): Output = handleByEngineer(request) }
类图如下:
创建上面3个处理结点:
val customerService = new CustomerService val manager = new Manager val engineer = new Engineer
由多个结点的不同顺序构成不同的责任链:
customerService.next = manager
manager.next = engineer
现在用户只需投诉给客服就行,无需知道处理细节:
def handle(request: Input): Option[Output] = {
customerService handle request
}
假如连续收到一连串投诉码”cafebabe wenzhe”,对于每个投诉,打印处理结果,如果没人处理的业务则不打印:
val cafebabe = "cafebabe wenzhe" println("----- Oop1: inherit -----") for (ch <- cafebabe) { Oop1 handle Input(ch) map (_.value) foreach println }
输出正确结果:
Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
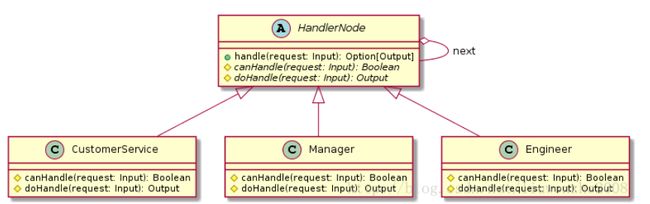
3.2 解法二:用策略模式实现责任链模式
上面的实现中,用到模板方法模式,用到继承,处理者与结点是同一个类层次中;现在换一种方式:用策略模式,用聚合。
将处理者与结点分开。
我们首先定义处理者接口:
trait Handler {
def canHandle(request: Input): Boolean
def handle(request: Input): Output
}
客服,经理,工程师分别给出不同的处理者实现:
class CustomerService extends Handler { def canHandle(request: Input): Boolean = canHandleByCustomService(request) def handle(request: Input): Output = handleByCustomService(request) } class Manager extends Handler { def canHandle(request: Input): Boolean = canHandleByManager(request) def handle(request: Input): Output = handleByManager(request) } class Engineer extends Handler { def canHandle(request: Input): Boolean = canHandleByEngineer(request) def handle(request: Input): Output = handleByEngineer(request) }
结点除了带有可变在nextNode外,还聚合了一个处理者(不可变,构造时传入):
class Node(handler: Handler) { var nextNode: Node = _
处理过程与上类似:
@tailrec final def handle(request: Input): Option[Output] = { if (handler canHandle request) Some(handler handle request) else if (nextNode == null) None else nextNode handle request } }
类图如下:
创建3个处理结点: 客服,经理,工程师
val customerService = new Node(new CustomerService) val manager = new Node(new Manager) val engineer = new Node(new Engineer)
构成责任链:
customerService.nextNode = manager
manager.nextNode = engineer
现在用户只需投诉给A(客服)就行,无需知道处理细节:
def handle(request: Input): Option[Output] = {
customerService handle request
}
假如连续收到一连串投诉码”cafebabe wenzhe”,对于每个投诉,打印处理结果,如果没人处理的业务则不打印:
val cafebabe = "cafebabe wenzhe" println("----- Oop2: aggregation -----") for (ch <- cafebabe) { Oop2 handle Input(ch) map (_.value) foreach println }
输出正确结果:
Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
4. 函数式风格(Functional Programming)
大部分程序员都熟悉面对对象,而不熟悉函数式编程,为了让面向对象程序员容易理解,我们先从上面3.2节在OOP实现方式出发,一步一步地重构为FP。
4.1 解法三:用一等公民函数替换策略模式实现责任链模式
OOP通过抽取接口,构建具体子类,利用多态实现各种设计模式。从FP在角度,接口Handler的作用也可看作是提供两个函数的东西。那么,可以将3.2节代码中接口Handler及其子类去掉,把接口中的两个方法作为类Node的不可变成员变量(构造函数传入),那么类Node变为:
class Node(canHandle: Input => Boolean, doHandle: Input => Output) { var nextNode: Node = _ @tailrec final def handle(request: Input): Option[Output] = { if (canHandle(request)) Some(doHandle(request)) else if (nextNode == null) None else nextNode handle request } }
类图如下,只有一个Node类,简单很多吧:
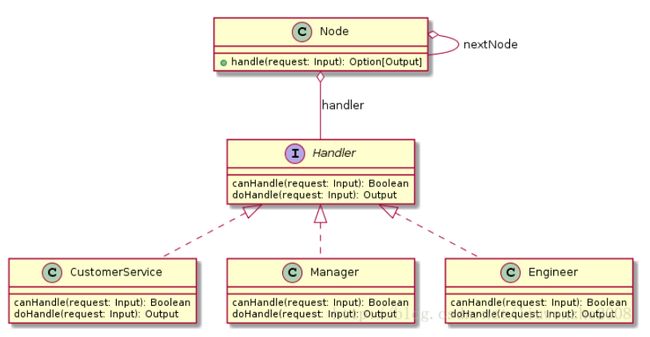
相应的,修改构造责任链的代码:
val customerService = new Node(canHandleByCustomService, handleByCustomService) val manager = new Node(canHandleByManager, handleByManager) val engineer = new Node(canHandleByEngineer, handleByEngineer)
其他代码与3.2节一样,这里不在提供。比较3.2节的纯OOP方式,这里的实现不仅变短了,而且扩展起来更方便,不需要为新的不同的处理策略再定义类,只需传如不同的函数即可。
4.2 解法四:用偏应用函数实现责任链模式
4.2.1 替换Node类
上一小节我们已经成功地用“一等公民”函数替换Handler接口及其子类。现在就只剩下Node类了,能否也用函数替换呢?
分析一下,Node类有3个成员变量:
(1)canHandle: Input => Boolean,它是一个函数变量 (2)doHandle: Input => Output,它也是一个函数变量 (3)nextNode: Node,指向下一结点的变量。
另外Node类在主要方法是handle,它有一个参数request:Input,返回输出结果Option[Output],代表可能有结果,可能没结果。
从FP角度,Node类没有存在的必要,可以写一个函数代替它,这个函数具有下面的特点:
(1)函数的内容就是Node类handle方法的内容,需要的外部环境全部由参数提供 (2)返回值是Option[Output] (3)有4个输入参数(canHandle, doHandle, nextNode, request)
我们可以写成下面的函数:
def handleByChainNode(canHandle: Input => Boolean, handle: Input => Output, nextHandle: Input => Option[Output], request: Input): Option[Output] = { if (canHandle(request)) Some(handle(request)) else if (nextHandle == null) None else nextHandle(request) }
4.2.2 为函数升阶:函数的Curry化为更高阶的函数
上面的函数有太多参数(4个),是一种坏味道(Code Smell),因为这样的函数不好使用。每个处理者(客服、经理、工程师),我们只需要赋予canHandle,handle两个参数;把处理者链起来的链接顺序,只需要传递nextHandle参数;处理业务请求,只需要传入request参数。那么,现在这么多参数,我们很难一次性提供,那么我们应该怎么用它来解决问题呢?
解决方法首先就是要减少参数个数,每减少一个参数,函数的返回值是另一个函数(作为返回值的函数是一等公民),那个被减少的参数作为返回值函数的参数。比如把request参数从handleByChainNode的参数中去掉,那么handleByChainNode需要返回另一个函数(参数就是request),代码如下:
def handleByChainNode(canHandle: Input => Boolean, handle: Input => Output, nextHandle: Input => Option[Output]): Input => Option[Output] = { (request: Input) => { if (canHandle(request)) Some(handle(request)) else if (nextHandle == null) None else nextHandle(request) } }
这是一个返回函数的函数,我们叫做高阶函数。这样写的代码是不是有的绕?为了方便阅读,scala提供语法糖,上面的代码也可以写出这样:
def handleByChainNode(canHandle: Input => Boolean, handle: Input => Output, nextHandle: Input => Option[Output]) (request: Input): Option[Output] = { if (canHandle(request)) Some(handle(request)) else if (nextHandle == null) None else nextHandle(request) }
这是一个二阶函数,拥有两个参数列表,第一个参数列表包含三个参数(canHandle,handle,nextHandle),另一个参数列表只有一个参数(request)。这里虽然返回值不是函数,而是原来的Option[Output],但从普通函数(一阶函数)的角度看它的返回值就是一个函数。
现在,第一个参数列表的参数还是太多,怎么办?同样办法,我们可以继续增加参数列表,减少每个参数列表中参数个数,最终我们得到下面的4阶函数(有4个参数列表):
def handleByChainNode(canHandle: Input => Boolean) (handle: Input => Output) (nextHandle: Input => Option[Output]) (request: Input): Option[Output] = { if (canHandle(request)) Some(handle(request)) else if (nextHandle == null) None else nextHandle(request) }
上面这个通过增加函数阶数的办法来减少参数个数,直到每个参数列表只有一个参数的过程,叫做函数的Curry化。那么,这又有什么用呢?接下来你就知道!
4.2.3 为函数降阶:偏应用函数
有了上面的Curry化后的高阶函数,创建每个处理结点就很容易了,就是调用上面“半”个handleByChainNode方法:
val customerService = handleByChainNode(canHandleByCustomService)(handleByCustomService) _ val manager = handleByChainNode(canHandleByManager)(handleByManager) _ val engineer = handleByChainNode(canHandleByEngineer)(handleByEngineer) _
之所以说“半”个方法,是因为还没给handler函数后面两个参数列表赋值(函数调用后面的下划线表示没提供数据),即没有给参数nextHandle赋值,也没有给request参数赋值。这在函数式编程中叫做“偏应用函数”,方便把一个高阶的函数降阶为更低阶的函数。这个低阶函数虽然也是函数,当实际上已经包含了一些不可变状态(就是调用高阶函数时那些已经赋值的参数,这里是canHandleByXX, handleByXX)。
现在customerService,manager,engineer都是2阶函数,其第一个参数列表是(nextHandle: Input => Option[Output]),第二个参数列表是(request: Input)。我们可以对nextHandle参数赋值从而把这些结点链起来:
val handleChain = customerService(manager(engineer(null)))
若要调整顺序就很简单了,只要换一下调用顺序即可。现在handleChain是一个一阶函数,也就是我们熟悉的普通函数,参数为request,返回Option[Output],处理用户业务请求也就是调用handleChain而已:
def handle(request: Input): Option[Output] = {
handleChain(request)
}
测试下, 假如连续收到一连串投诉码”cafebabe wenzhe”,对于每个投诉,打印处理结果,如果没人处理的业务则不打印:
val cafebabe = "cafebabe wenzhe" println("----- Fp1: partial apply function -----") for (ch <- cafebabe) { Fp1 handle Input(ch) map (_.value) foreach println }
输出正确结果:
Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
现在责任链的实现完全没有类了,也不存在可变状态(OOP中可变成员变量nextHandler在多线程环境下不是线程安全的,而现在完全不存在可变状态),这是本文给出的第一个纯函数式实现。从代码来看,更短更简洁!
4.3 解法五:用偏函数实现责任链模式
4.3.1 偏函数:我不完美,但我们很完美!
若一个函数只能处理其参数的某些取值范围,而对其它取值范围在处理没有定义,这样的函数不是一个完整的函数,而像是一部分函数,我们称之为“部分实现函数”,或者叫“偏函数”(Partial Function)。
有点抽象吧,那我举个例子,定义这样一个函数:输入参数类型是整数类型,对偶数有定义,行为是对偶数平方,但没为奇数定义行为,这显然不是个完整的函数,而是部分实现的函数,即偏函数。
温馨提示:上一节中“偏应用函数”与本节的“偏函数”,尽管名字很像,都是不完整的函数,但却是完全不同的概念,不同之处在于缺少的部分不一样。函数可以有多个参数列表,若缺少了某个参数列表,就是“偏应用函数”,侧重参数列表的不完整性;于此不同的是,若一个函数有且只有一个的参数,并且没有实现对该参数有部分取值范围的处理,就是“偏函数”,侧重实现的不完整性。“偏应用函数”的好处在于将大函数(高阶函数)分解为一系列可重用的小函数(低阶函数)并获得某些不可变状态,侧重于“分”;而“偏函数”的好处在于灵活组合一系列功能简单的小函数构成功能强大的大函数,侧重于“合”。
val squareEven = new PartialFunction[Int, Int] { def apply(x: Int) = x * x def isDefinedAt(x: Int) = x % 2 == 0 }
更方便的是用模式匹配来描述:
val squareEven: PartialFunction[Int, Int] = { case x: Int if x % 2 == 0 => x * x }
case语句很容易读,即:”当整数x对2取模为0时,返回x的平方”。
偏函数比普通函数更小,因此代码的可重用粒度也就更细。通过定义一些列“不完美”的偏函数,通过不同的组合方式,可以产生各种不同的“更完美”的偏函数。下面介绍偏函数如何组合实现责任链模式。
4.3.2 用偏函数实现责任链模式
由于客服,经理,工程师每个人都只负责处理某些业务,他们都是部分业务的处理者,可以用偏函数来描述:
def handler(canHandle: Input => Boolean, handle: Input => Output): PartialFunction[Input, Output] = { case request: Input if canHandle(request) => handle(request) }
将客服,经理,工程师各自不同的责任范围和处理方法传入,从而产生责任链上的结点:
val customService = handler(canHandleByCustomService, handleByCustomService) val manager = handler(canHandleByManager, handleByManager) val engineer = handler(canHandleByEngineer, handleByEngineer)
现在customService,manager,engineer都是偏函数。偏函数虽然不完整,但可以组合,多个不完整的偏函数可以组合成一个更完整一点的偏函数。责任链的构造可以由一系列偏函数组合而成:
val handleChain = customService orElse manager orElse engineer
可以看到我们很容易调整执行顺序。handleChain也是偏函数,但是处理能力更强了。向handleChain输入业务请求,直接调用这个函数:
def handle(request: Input): Output = { handleChain(request) // throw MatchError exception when no handler can handle the request }
这样调用的话可能会抛出异常:当request取值在偏函数handleChain定义范围之外(即责任链上所有结点都不能处理)时,会抛出MatchError异常。为了跟前面其他实现的调用方法一致,我们希望返回一个Option[Output],如果能够处理,就返回结果Some[Output];若不能处理,返回None。
有两种方法可以实现:
(1)使用Try类封装异常(无异常返回Success[Output],抛出异常返回Failure),然后再转成Option,代码如下:
def handle(request: Input): Option[Output] = {
Try(handleChain(request)) toOption
}
这是一种通用的解决方式。
(2)对于Scala的偏函数,还有更专用的方式,可以通过偏函数的lift方法把处理结果转成Option,
def handle(request: Input): Option[Output] = {
handleChain lift request
}
测试下, 假如连续收到一连串投诉码”cafebabe wenzhe”,对于每个投诉,打印处理结果,如果没人处理的业务则不打印:
val cafebabe = "cafebabe wenzhe" println("----- Fp2: partial function -----") for (ch <- cafebabe) { Fp2 handle Input(ch) map (_.value) foreach println }
输出正确结果:
Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
利用偏函数间的组合(orElse)方式,取代了nextHandler状态。比起前面4种实现方式,偏函数的实现方式更加简洁,优雅。
到目前为止的5种责任链模式的实现方式,都是单线程的。那么,请读者考虑下面两个问题:
(1) 能否让责任链上的结点多任务并发执行? (2) 能否把责任链部署到分布式环境下,分布在世界各地的多台计算机,通过某种方式构成一条责任链,协同工作,能否做到呢?
5. 响应式风格(Reactive Programming)
5.1 响应式思维:别拉进来,推出去!
面向对象设计模式一般通过接口(或抽象类)对代码进行隔离,减少代码间的耦合度(见第3节);函数式风格实现的设计模式也是通过“接口”隔离,只不过这个“接口”更加通用,其实就是“一等公民”函数(4.1节)或者偏函数(4.2节)。无论哪种方式,说到底都是对象间直接的方法调用,都是“拉”式的。用户向客服投诉,客服处理,其实就是用户代码调用了客服类(AHandler)的handle方法(OOP,见第3节),或者调用客服处理函数(FP,见第4节),这些都是“拉”的思维方式。用户搞不定,于是把客服“拉”进来;客服也搞不定时,把经理“拉”进来;经理也搞不定时,把工程师“拉”进来。他们通过直接调用对方的服务接口实现交互。
与“拉”不同的方式是“推”,用户搞不定,“推送”消息给客服反映问题;客服对此事件作出响应,若能搞定就把解决方案“推送”回给用户,否则就找帮手,把消息forward给经理;同样的,经理做出响应后若搞不定则再forward给工程师,工程师再对消息事件做出响应。每个个体之间都是独立的、事件消息驱动的、响应式的,他们之间通过把事件消息“推”出去来实现交互,通过响应不同的事件消息来做各种具体不同的事。这种思维方式就是响应式思维,更加符合自然。在自然界中,人与人的交互都是事件消息驱动、响应式处理的,人与人都是独立个体,都能并行处理,都是分布式的。基于这种思想的响应式编程(RP)更容易处理并发问题,更适合分布式计算。对象之间可以完全独立解耦,甚至可以分布在不同的机器上,就好像我们可以通过手机给地球另一端的人交流消息一样。
5.2 解法六:用Actor模型实现责任链模式
5.2.1 Actor模型简介
一个Actor可以比做一个人,或者比做一台单核单任务计算机,或者比做一个企业里的某个工作角色,虽然它只是一个很轻量级的对象而言。具有如下特性:
(1) 灵活部署:多个Actor可以在同一进程内(这时候是并发),也可以跨进程,还可以跨机器跨网络,分布式应用。 (2) Actor内代码执行方式:同一时间一个Actor内永远只有一条线程在执行,因此保证了Actor内部线程安全。Actor就好比一台单核单任务计算机。 (3) Actor间的交互方式:Actor与Actor之间的交流,就像人与人之间的交流,发送事件消息(无类型限制),响应事件并处理。不能直接调用Actor的方法,因为不同Actor很可能不在同一台机器上。 (4) 有序的树状组织结构:多个Actor可以构成一个社会,每个Actor就像一个公司里不同的职位,有作为老板的Actor管理多个部门经理Actor,经理Actor管理多个员工Actor。Actor间有监管机制,如父Actor监管子Actor。 (5) 出错处理:不怕,让他挂!(Let it crash!)当某一Actor挂了,其监控者(另一Actor)会收到消息,响应方式可以是恢复那个Actor,重启Actor,停止Actor,也可以把自己也挂起,或者也可以继续向它的上级Actor汇报,等等,Actor具有很高的容错性,怎么处理,完全取决于你! (6) Actor非常轻量级,一个应用程序可以创建几百万个Actor,就像你的计算机瞬间就变成几百万台计算机一样。 (7) Actor非常适合描述现实世界中的对象,类似OOP,只是每个对象都是Actor并具有Actor的一切优点:线程安全、并发、分布式、高容错性。
5.2.2 Akka,一个支持高并发、分布式计算、消息驱动的Actor库
Akka Actor是使用scala实现的Actor模型,目前已经成为scala的标准Actor模型。Scala之所以在并发编程方面有强大的优势,Akka Actor是其重要原因。Akka Actor是一个分布式计算库,著名的大数据框架Spark底层就是用它来实现分布式计算的。可以在build.sbt增加依赖(类似Maven,SBT编译时会从Maven中心仓库递归下载依赖):
libraryDependencies += "com.typesafe.akka" %% "akka-actor" % "2.4.17"
5.2.3 为责任链上的处理者结点定义Actor类
从面向对象的角度,责任链上的每个结点,即客服,经理,工程师,都是描述现实世界的对象。在Actor响应式编程中,这种描述现实世界的对象很适合用Actor来定义。因此,我们为这些结点定义一个Actor的子类:HandlerActor(准确讲是混入Actor特质的类,这里说成子类是便于理解)。不同的结点,除了以下3点不同,其他都是相同的:
判断有责任处理输入请求的函数:canHandle,类型为:Input => Boolean
处理输入请求的函数:handle,类型为: Input => Output
对下一个处理者结点的引用:nextHandler,类型为:ActorRef,因为每个结点都是Actor。
我们可以把这些不同点作为HandlerActor类的成员变量,对于不同的结点它们有不同的值。其中,canHandle和handle两个成员变量可以定义为不可变的,作为构造函数的输入参数,结点构造时需要外部指定;而nextHandler,为了方便在运行时更换结点顺序,设计为可变的。
class HandlerActor(canHandle: Input => Boolean, handle: Input => Output) extends Actor with ActorLogging { private var nextHandler: ActorRef = _
这个类很像第4.1节中的Node类,只不过它继承Actor(后面混入ActorLogging特质是为了方便打log)。
自定义Actor类中唯一一个必须override的方法,是receive方法,它负责接收事件消息并且做出响应。
def receive = { case SetNextHandler(nextHandler) => this.nextHandler = nextHandler case handleEvent @ Handle(request) => { log debug s"${request.value}" if (canHandle(request)) sender ! Result(Some(handle(request))) else if (nextHandler == null) sender ! Result(None) else nextHandler forward handleEvent } }
方法receive返回一个偏函数(见第4.3节),通常我们用模式匹配来描述偏函数。上面代码中匹配了两个case,表明收到这两种消息事件(无类型限制)以及各自的响应逻辑,下面对这两种事件进行解释:
(1) 第一种事件:SetNextHandler,顾名思义,它请求HandlerActor去设置下一个处理者结点,事件中附带着期望设置为下一处理者的引用。SetNextHandler事件由下面的case类来定义:
case class SetNextHandler(nextHandler: ActorRef)
对这类事件的响应,就是把可变成员变量nextHandler设置为事件要求的值:
case SetNextHandler(nextHandler) => this.nextHandler = nextHandler
温馨提示:可以这样理解模式匹配,即把每个case语句都当成一个方法(实际不是),会容易理解得多。比如上面的代码,可以想象为:方法名为SetNextHandler,参数为nextHandler(类型为ActorRef,可从case类SetNextHandler中推断出来),方法体为this.nextHandler = nextHandler,返回值可从方法体推断(面向表达式编程,把方法体当成表达式)。对比一下,一般面向对象的思路会定义方法:
def setNextHandler(nextHandler: ActorRef) = this.nextHandler = nextHandler
对比一下,是不是很相似呢?这样对比,可以让模式匹配非常容易理解。复杂一点,你可以试试用这种办法理解后面的case Handle(request) => { … }
(2) 第二种事件:Handle,顾名思义,它请求HandlerActor去处理输入,事件中附带着输入请求request。Handle事件可下面的case类来定义:
case class Handle(request: Input)
对该类事件的响应,就是先判断能否处理输入请求,可以的话,就处理该请求,并将处理结果加个信封,作为表示结果(Result)的消息事件,作为回复,告知(tell)原信息的发送者(sender)。
if (canHandle(request)) sender tell Result(Some(handle(request)))
上面的结果Result,对处理结果进行包装,它有下面的case类定义:
case class Result(value: Option[Output])
方法tell是actor中一个非常常用的方法(我估计其常用度排名第一),它告诉其他actor一个消息(也可以告诉自己,那样可以实现状态模式),也就是向其他actor发送消息。可能是它太常用了,Akka Actor专门为它定义操作符方法:!,读作tell,表示发送消息。上面的代码,更多时候是这样写的:
if (canHandle(request)) sender ! Result(Some(handle(request)))
如果该结点不能处理,则判断下一结点是否存在,若不存在,就向原消息的发送者回复告知没人能处理该请求。
else if (nextHandler == null) sender ! Result(None)
否则,把请求处理的消息事件forward给下一处理者:
else nextHandler forward handleEvent
5.2.4 创建actor对象
在创建具体Actor对象之前,需要先创建Actor系统(当再也不用的时候要关闭它,否则程序不会结束,也不能放在Shutdown hook中关闭),它为我们提供Actor模型所需的上下文。
val system = ActorSystem("ActorSystem")
接下来,我们可以为每个处理者创建actor对象:
val customService = system actorOf (Props(new HandlerActor(canHandleByCustomService, handleByCustomService)), "customService") val manager = system actorOf (Props(new HandlerActor(canHandleByManager, handleByManager)), "manager") val engineer = system actorOf (Props(new HandlerActor(canHandleByEngineer, handleByEngineer)), "engineer")
注意这里customService,manager,engineer的类型不是HandlerActor,而是ActorRef,代表对actor的引用。在Actor编程中,我们不提倡直接引用Actor类的对象,因为这样很容易直接调用Actor类的方法,而响应式思维是通过发消息来通知Actor使其做出响应。ActorRef是Akka Actor为我们提供的抽象,它所引用的actor可以是本地的,也可以是远程的,通过ActorRef的抽象让我们不必关注这些底层通信细节,我们只要专注于所要处理的业务就行。
虽然这里代码中把customService,manager,engineer这三个actor都在同一个进程里创建了,实际上,它们也可以在不同的进程、不同的机器上创建,在代码中我们可以通过其逻辑路径找到其他机器上(网络上)的actor,持有它的引用(ActorRef),使用起来的代码更本地创建的代码是没有区别的。
5.2.5 连环计,创建基于actor的责任链
接着是把这3个处理者链接起来,构造责任链。不同于OOP,我们不能直接调用HandlerActor的setNextHandler方法(当然我们也没有提供这个方法,即使有也不推荐直接调用),而应该向这些结点发消息,比如向customService发送消息,告诉他如果搞不定可以找manager帮忙:
customService ! SetNextHandler(manager)
同样的,向manager发送消息,告诉他如果连他也搞不定的话可以找engineer帮忙:
manager ! SetNextHandler(engineer)
这样,责任链就形成了。
温馨提示:要更好地理解发送消息的符号“!”以及actor间基于消息传递的交互方式,可以与面向对象中直接方法调用的“.”符号做对比,即把“!”想象成“.”。比如上面的代码,若是直接方法调用,则为:
manager.setNextHandler(engineer)
表示直接调用bHandler的setNextHandler方法,传递参数cHandler。而
manager ! SetNextHandler(engineer)
表示向manager发送消息事件SetNextHandler,附带参数engineer。
其实目的都是一样的,非常相似吧,只是把符号”.”换成符号”!”,把普通对象换成actor对象,把方法名换成事件名,其他都一样,就把方法直接调用变成异步的消息事件发送的了。
5.2.6 如何礼貌地向别人提问题
由于消息处理是异步的,我们定义的处理函数应该返回一个代表未来值的Future,而不能等待结果处理完才返回。
def handle(request: Input): Future[Option[Output]] = {
现在用户询问客服,希望客服在5秒之内进行回复:
val future = customService ask (Handle(request), Timeout(5 seconds))
这里ask与前面的tell都是发消息,不同之处在于tell是说完就忘,不期待别人回复,而ask是期待别人回复的。但是别人可能不会立刻就回复你,也可能永远都不给你回复,而你也不会一直傻傻地等着他回复,谁都不能阻塞你,不过你心理有一个超时时间,超过这个时间你就认为他不再回复了。
我们已经知道,操作符!与tell是通过意思,使用起来就好像函数直接调用。类似的,ask也有一个同义的操作符,你猜猜看是哪个?相信你可以猜到,就是问号操作符“?”。
另外,如果每次向人家问问题时总是加上这么一句:“给你5秒钟回答我的问题”,显得很不礼貌,是不是?因此我们把这个超时时间记在心理就行,干嘛非得说出来呢?我们可以定义把它成隐式变量:
implicit val timeout = Timeout(5 seconds)
接着,问问题就礼貌很多吧:
val future = customService ? Handle(request)
当调用问号方法操作符,它会在上下文查下有没有隐式的Timeout。没有的话,休想编译过!
这里返回值future是Future[Any]类型,代表未来值,这样不至于人家不回答你而让你白白等上一段时间,这样你才不会被阻塞。
可惜返回值future的泛型是Any,而不是我们期望的输出结果类型Option[Output]。Any类型可以类比地理解为Java里面的Object(其实Any更强,因为它还包括基本类型,而Java的Object是不行的,所以Scala是一门完全面向对象的语言,而Java不是)。那么我们需要把future转化为我们希望的类型:Future[Option[Output]]。根据前面代码中HandleActor类中对Handle事件的处理,我们知道HandleActor会把处理结果Option[Output]封装在信封(Result类)里,因此这里的Any实际上就是Result,转成Result就可以拿到它的value,也就是我们期望的输出结果了。
future.mapTo[Result] map (_.value)
现在就可以得到充满期待的未来值Future[Option[Output]]了。
5.2.7 对未来值的聪明响应:“我不理你,但当你有结果的时候一定要告诉我!”
测试下, 假如连续收到一连串投诉码”cafebabe wenzhe”,对于每个投诉,打印处理结果,如果没人处理的业务则不打印:
val cafebabe = "cafebabe wenzhe" println("----- 6. Rp1: akka actor Reactive Programming -----") val futures = cafebabe map (Rp1 handle Input(_))
问了一连串的问题,会得到一连串的答复。不同于前面5种实现方式,现在的情况是说有的消息处理都是并发的、异步的,handle方法只给你返回不是最终结果,而是代表结果的未来值,就好像有人告诉你“以后你能赚到一个亿”一样,是不是有点忽悠人?那么什么时候能拿到结果?拿到怎样的结果呢?真的“赚到一个亿”?
这里的futures是一个可索引的序列,类型是:IndexedSeq[Future[Option[Output]]],其中每个元素是代表每个输入请求处理结果的未来值。
有两种方式拿到结果:一种是傻傻地等待;另一种是聪明的响应式思维:“我不理你,但当你有结果的时候一定要告诉我!”。
具体的,用聪明的响应式思维,就是对于每个未来值,当它的任务完成的时候,如果成功,就打印处理结果,如果没人处理的业务则不打印;如果一直等不到回复,超时了,或者其他原因的问题,就会收到失败的信息,并附带异常(超时的异常为AskTimeoutException),那么我们就打印异常堆栈信息。
futures foreach (_.onComplete { case Success(output) => output map (_.value) foreach println case Failure(exception) => exception printStackTrace })
运行结果如下:(每次运行顺序都不一样)
Customer Service handles w Customer Service handles a Manager handles b Customer Service handles a Engineer handles c Manager handles b Manager handles z
处理结果不是顺序的了,而且每次运行都不一样,表明事件响应的过程是并发执行的。
5.2.8 并发世界也有秩序
如果我们想让运行结果有序,怎么办?这有何难,把序列futures通过Future类的sequence方法合并成一个未来值:
val mergedFuture = Future sequence futures
这个合并的未来值mergedFuture,类型是Future[IndexedSeq[Option[Output]]],即它只是一个Future,未来值的结果是一个可索引的序列。这个未来值mergedFuture,只有当所有的输入请求全部处理完并拿到所有输出结果时,把结果按照输入请求的顺序,可索引序列作为结果输出。我们只要拿到这个结果就是有序的了。
前面第5.2.7节已经介绍过聪明的办法,这里不重复了,偏偏就用很傻很天真的办法,傻傻地等待,阻塞当前线程,直到别人把所有结果都告诉你为止。(当然也不会傻到等上一整天,其实等上5秒就足够傻了,^_^)
val outputs = Await result (mergedFuture, 5 seconds)
output是我们想要的有序结果,类型是IndexedSeq[Option[Output]],现在对于每个投诉,有序地打印处理结果,如果没人处理的业务则不打印:
outputs.flatten map (_.value) foreach println
输出与输入同样顺序的结果:
Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
5.3 解法七:用RX(Reactive eXtension,响应式扩展)实现责任链模式
RX是基于事件流处理的响应式编程开源库,目前已经有多种语言的实现,比如RxJava,RxScala(RxScala其实是在RxJava基础上增加了一层adapter,使API更友好)。关于RxJava可以参考我另外几篇文章:
(1)实验驱动开发与响应式编程 —- File Watcher的技术实现
(2)性能优化:RxJava异步响应式编程提升响应速度
(3)基于RxJava实现事件总线
本文使用RxScala,需要在build.sbt增加依赖(类似Maven,SBT编译时会从Maven中心仓库递归下载依赖):
libraryDependencies += "io.reactivex" %% "rxscala" % "0.26.5"
对RX进行响应式编程,主要是对事件流(Observable)进行一连串响应,包括过滤,转换,处理,等等操作,使其流向期望的目的地。我们可以把事件流(Observable)比作FP中的高阶函数(见4.2节)。
类似FP,对于客服,经理,工程师,他们响应输入请求的过程是:为输入请求request构造事件流,然后过滤使得只有能够处理(canHandle)的事件通过,然后处理(handle)请求并返回带有结果的事件。这个过程需要外部提供以下3个参数:输入请求request,判断是否能够处理的函数(canHandle),具体处理的函数(handle)。于是我们可以定义下面的三阶函数(3个参数列表)来表示每个结点的响应输入请求的处理过程:
def handler(canHandle: Input => Boolean)(handle: Input => Output)(request: Input) = {
Observable just request filter canHandle map handle
}
handler函数是这样一个3阶函数,它接受输入request,构造出以Input为消息的事件流Observable,事件流经过filter过滤,只让那些canHandle事件往后流,接着事件流到map,通过handle把输入消息Input转化为Output,然后把事件流作为返回值流向函数的调用者,以便后续控制事件流的流向。
因此我们可以构造出每个结点:客服,经理,工程师,他们的不同方式在于判断是否能够处理的函数(canHandle),具体处理的函数(handle),我们把这些不同的地方传入上面的3阶函数handler,得到代表每个处理结点的偏应用函数(见4.2节):
val customService = handler(canHandleByCustomService)(handleByCustomService) _ val manager = handler(canHandleByManager)(handleByManager) _ val engineer = handler(canHandleByEngineer)(handleByEngineer) _
上面customService,manager,engineer,已降为一阶的普通函数了,类型是:Input => Observable[Output],即输入参数是输入请求Input,输出是带有输出信息Output的事件流。
将结点链起来,就可以处理用户投诉事件了。当客服不能处理request事件,就switch给经理,经理不能处理就switch给工程师。
def handle(request: Input): Observable[Output] = {
customService(request) switchIfEmpty manager(request) switchIfEmpty engineer(request)
}
输入一连串业务,比如cafebabe = “cafebabe wenzhe”,处理逻辑可以用下面一条事件流描述,事件流最后流到print,把输出值打印出来。
println("----- Rp2: RX Reactive Programming (single thread)-----")
Observable from cafebabe map (Input(_)) flatMap (Rp2 handle _) map (_.value) foreach println
我们没有对事件流进行异步处理,因此上面的处理过程是单线程的,输出有序的结果:
----- Rp2: RX Reactive Programming (single thread)----- Engineer handles c Customer Service handles a Manager handles b Customer Service handles a Manager handles b Customer Service handles w Manager handles z
我们很容易把事件流的响应过程异步化,比如让经理处理的串行事件流manager(request)流过subscribeOn操作符,可以转化为异步事件流asyncHandleByManager:
val asyncHandleByManager = manager(request) subscribeOn ComputationScheduler()
subscribeOn方法后面接受线程池调度器,这里用的ComputationScheduler使用的线程池里的线程个数与计算机CPU的核数相同,你也可以把它替换成你想要的。
类似的办法可以创建经理和工程师的异步事件流,再用switchIfEmpty操作符将它们链接起来构成异步的责任链:
def asyncHandle(request: Input): Observable[Output] = { val asyncHandleByCustomService = customService(request) subscribeOn ComputationScheduler() val asyncHandleByManager = manager(request) subscribeOn ComputationScheduler() val asyncHandleByEngineer = engineer(request) subscribeOn ComputationScheduler() asyncHandleByCustomService switchIfEmpty asyncHandleByManager switchIfEmpty asyncHandleByEngineer }
输入同样一连串业务cafebabe = “cafebabe wenzhe”,让事件流流入能并发处理的asyncHandleByABC:
println("----- Rp2: RX Reactive Programming (multiple thread)-----")
Observable from cafebabe map (Input(_)) flatMap (Rp2 asyncHandle _) map (_.value) foreach println
运行结果如下:(每次运行顺序都不一样)
----- Rp2: RX Reactive Programming (multiple thread)----- Customer Service handles a Engineer handles c Manager handles b Manager handles b Customer Service handles w Customer Service handles a Manager handles z
处理结果不再是顺序的了,而且每次运行都不一样,表明事件响应的过程是并发执行的。
5.4 两种响应式编程方式的比较
Actor处理能够在进程内使用,还可以跨进程、跨机器、跨网络,能够适用于分布式计算;RX只能在进程内使用。
如果要串行(单线程)执行,或者单线程多线程切换,RX要比Actor更加方便。
从编程风格看,Actor更像面向对象OOP,需要定义一个Actor类,一个无需考虑线程安全问题的类;而RX更像是函数式编程,使用高阶函数,通过流式处理,代码可读性更好。
6. 回顾与总结
由于Scala语言简洁易懂,读起来相似自然语言,开发效率和运行效率都很高,而且支持多种编程范式(即是完全面向对象语言,又是函数式编程语言),再加上响应式的Akka Actor、RxScala),因此本文采用Scala作为例子代码show给读作,也顺带介绍了一些Scala语言特性,读者如果熟悉Java 8,会很容易理解,因为Java 8很多特性都借鉴自scala。
本文描述了责任链模式的应用场景,然后给出7中不同风格的实现方式。第一种是传统面向对象的基于继承的实现方式;接着以聚合代替继承,给出了第二种面向对象实现方式;接下来从OOP逐步过渡到FP,第三种实现就是混合了OOP和FP两种范式的实现方式;接下来的第四种和第五种都是纯FP实现,分别使用了偏应用函数和偏函数;从第一种到第五种风格的演化过程中,代码越来短,当可扩展能力和灵活性却越来越好;接着介绍响应式思维,以及两种不同的实现,第六种实现是基于Actor模型,而第七种实现是基于事件流响应的流式处理,最后比较了这两种响应式风格。在介绍这7种实现风格的过程中,考虑到大多数程序员是面向对象出身,本文对函数式编程、响应式编程的概念进行了比较细致的介绍。
原文:https://blog.csdn.net/liuwenzhe2008/article/details/70199520