文法和内容
编译原理笔记第二部分,内容参考:北航软院教师邵兵课堂课件及内容、张莉著《编译原理及编译程序构造》、国防工业出版社的《编译原理——学习指导与典型题解析》、AlvinZH的学习笔记以及个人理解
目前是包含了全部内容的版本,后续会推出精简版和复习知识点版
如有建议或错误错误欢迎在评论中指出或联系我:QQ:847590417
阅读目录
本章内容
2.1 形式语言基础
2.2 文法的非形式讨论
2.3 文法和语言的形式定义
2.4 语法树和二义性文法
2.5 句子的分析
2.6 有关文法的实用限制
2.7 文法的其他表示法
2.8 文法和语言分类
习题内知识
本章内容
重点:符号串、符号串集合的计算、文法、语言、递归、短语、句柄、语法树、文法的二义性、文法的使用限制、BNF表示文法、语法图、文法的分类。
2.1 形式语言基础
一、字母表和符号串
字母表:符号的非空有限集
符号:字母表中的元素
符号串:由符号拼接成的有穷序列
空符号串:没有任何符号的符号串
符号串的形式定义:
假设有一个字母表P:1.空符号串是P上的符号串;2.若x是P上的符号串,且a是字母表里的一个元素,则ax或xa(可以左,可以右,但只能一个不能同时加)是P上的符号串(一个符号也是符号串,a拼接ε);3.y是P上的符号串,当且仅当(iff)y是符合1.和2.的符号串。
二、符号串和符号串集合的运算
1.符号串相等:若x、y是集合上的两个符号串,则x=yiff组成x的每一个符号和组成y的每一个符号依次相等。
2.符号串的长度:x是符号串,x的长度|x|等于组成器的符号个数。(空符号串长度为0)
3.符号串的联接:若x、y是定义在P上的符号串,则x和y的联接xy也是P上的符号串,符号串xy不等于yx,而空字符串无论在左还是右联接到一个符号串上都是一样的。εx=xε
4.符号串的幂运算:假设x是符号串,那么其幂运算就是自身的拼接,0次幂等于一个空符号串,n次幂既是自身重复n次
5.符号串集合的乘积运算:假设A、B是符号串集合,则AB就等于一个A集合中的符号在前联接B集合中的符号在后:![]()
![]()
6.符号串集合的幂运算:假设有一个符号串集合A,则A的零次幂是一个仅包含空符号串的集合,n次幂则是n个A拼接得到的结果。计算A的n次幂时可以用A拼接A的n-1次幂来计算。
7.符号串集合的闭包运算:设A是符号串集合,则有:
A的正闭包:![]()
A的闭包:![]()
闭包只是比正闭包多了一个空符号串。
如何用符号得到一个程序:
A是某语言的基本字符串:
![]()
B是该语言的单词集:
![]()
则有B属于A的闭包,因为是从A的所有结果中提取出来的
而该语言的一个句子,即一条语句,也是一个在B上的符号串
令C是该语言的句子集合,则C也属于B的闭包,一个程序也属于C
2.2 文法的非形式讨论
文法:对语言结构的定义与描述,从形式上用于描述和规定语言结构,也称为语法。
语法规则:通过建立一组规则,来描述句子的语法结构,一般规定用“::=”的符号代替“由...组成”,一些基本的语法结构如下:

利用规则推导句子:有了规则后便可按照一定的方式用他们来推导或产生句子,方法如下:从一个要识别的符号开始推导,即用相应规则的右部来替代规则的左部,从左向右推导,每次使用一条规则进行推导。
例子:

推导直到所有的非终结符号被终结符号代替为止。
这种推导称为最左推导,除了这种还有最右推导

观感上就没有最左推导好了。
从一个<句子>推导出一个完整的句子的推导可以写成:
![]()
根据上述的介绍可知,文法只是在形式上对句子结构的定义与描述,而未涉及语义问题,因此可能出现一些大花生吃花生这种神奇的句子。
语法树:用树形描述一个句子的语法结构:
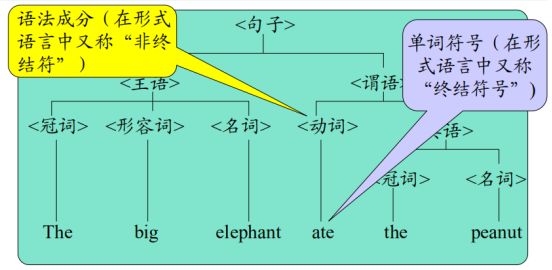
2.3 文法和语言的形式定义
2.3.1 文法的定义
定义:文法G=(Vn,Vt,P,Z)(grammar)
Vn:非终结符号集(nonterminal vocabulary)
Vt:终结符号集(V=Vn∪Vt,称为文法的字汇表)(terminal)
P:产生式或规则的集合(principle)
Z开始符号(识别符号)Z∈Vn
规则:一个有序对(U,x),通常写为U::=x或U→x(::=就等于→),其中U的长度为1,x的长度大于等于0。U∈Vn,x属于V的闭包。
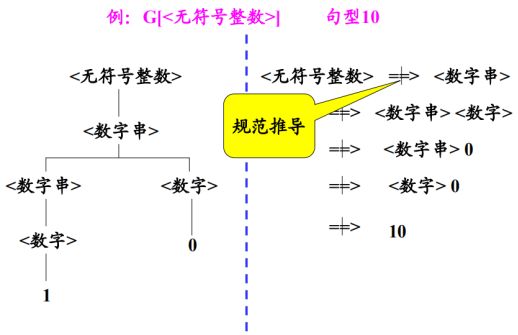
例如一个无符号整数的文法:
G[<无符号整数>]=(Vn,Vt,P,Z)
Vn={<无符号整数>,<数字串>,<数字>}(规则左侧出现的,可以继续拆分的符号集)
Vt={0,1,2,3,...9}(剩余的,不能再继续拆分的符号集)
P={<无符号整数>→<数字串>
<数字串>→<数字串><数字>
<数字串>→<数字>
<数字>→0
...
<数字>→9}(可拆分的符号集的变化规则)
Z=<无符号整数>(开始进行拆分的符号)
通常用尖括号把非终结符号括起来,以便和终结符号进行区分,其实非终结符号也不必有尖括号。
产生式(P内的元素)左边的符号会构成集合Vn,且Z∈Vn
当产生式有相同的左部时可以合在一起,用或符号|划分开

如上既是文法的BNF表示(巴克斯范式)
给定一个文法,实际只需给出一个产生式的集合,并指定最开始的识别符号即可(一般约定为第一条规则的左侧符号)
文法:

::=、|、<和>称为元符号(未扩展的元符号,在2.7节中会介绍扩展的元符号),由元符号构成的语言称为元语言,即可以用于描述其他语言的语言。
2.3.2 推导的形式定义
定义:直接推导:文法G:v=xUy,w=xuy(零步推导)
其中x、y∈V*(x、y是非终结符或者终结符或者空),U属于Vn(非终结符),u属于V*
若(U::=u)∈P,则v可根据文法G推导出w,v可推导出w,w直接归约到v(::=等于→)
若x=y=空符号串,有U::=u,则U可根据文法G推导出u或者简写为U可推导出u(G可以省略)
例:

定义:间接推导1:存在文法G,有U0,U1,...,Un属于V的正闭包
如果v=U0可以根据文法G中的两次或以上次推导出U1,然后根据G依次推导出到Un=w。(加号一定要有,是间接推导的象征)
则表示v可以根据文法G正推导出w: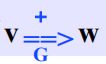 这个序列称为n次推导
这个序列称为n次推导
例:

定义:间接推导2:存在文法G,有v,w属于V的正闭包
如果v可以根据文法G正推导出w,或者v::=w,即在v可以根据G正推导出w时或v由w组成时: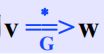 (直接推导加上n次推导)
(直接推导加上n次推导)
定义:规范推导:有xUy可推导出xuy,如果y属于Vt的闭包,则此推导是规范的,记为:![]() (最右侧需要有不变的,且不变的符号串要么只包含终结符号,要么为空)。
(最右侧需要有不变的,且不变的符号串要么只包含终结符号,要么为空)。
每个句子都有一个规范推导,并非每个句型都有规范推导,可由规范推导导出的句型称为规范句型。
结合多种推导符号:
![]()
最右推导:若符号串中有两个以上的非终结符时先推导右边的(规范推导);最左即是先推导左边的。
2.3.3 语言的形式定义
定义:文法G[Z]
(1)句型:x是句型<=>Z可以闭包推导出x,且x属于V*(可以有非终结符,可以有终结符)
(2)句子:x是句子<=>Z可正闭包推导出x,且x属于Vt*(式语言的最小单位,是由终结符号所组成的符号串)
(3)语言:L(G[Z])={x|x∈Vt*,Z多步推导出x},语言由所有的句子组成。
已知文法可以通过推导求出语言
已知语言构造文法时没有形式化的方法,文法和语言是多对一
例:

定义:这种两种不同文法对应的语言相同的文法,他们是等价文法
编译时关心的其实就是根据符号串和文法,判断符号串是否符合文法对应语言的规定。
2.3.4 递归文法
无穷种可能
1.递归规则:规则右部有与左部相同的符号
对U::=xUy,如果x是空符号串,即U::=Uy,既是左递归,左部未变;y是空符号串时U::=xU,右递归;当xy都不空,U::=xUy称为自嵌入。
若文法中至少包含有一条递归规则,则称该文法是直接递归的。
间接递归:有如下规则时:U::=Vx,V::=Uy|x,U也会得到自己。
2.递归文法:文法G,存在U∈Vn
如果U可正推导出...U...,则G是递归文法(自嵌入递归),如果可以正推导出U...,则G是左递归文法,如果...U,是右递归文法。
左的缺点:不能用自顶向下的方法进行语法分析,会造成死循环;
递归文法的优点:可用有穷条规则,定义无穷语言。(无符号整数的文法就是右递归文法,用13条规则便可定义所有的无符号整数)
2.3.5 句型的短语、简单短语和句柄
定义:短语和简单短语
一个文法G[Z],w是该文法的句型:w=xuy(xy可为空,u不可为空)
如果文法可推导出xUy,(U是一个非终结符),U可多步推导出u,则u是句型w相对于U的短语(句型中能被其所在位置的非终结符推出的符号串)
(u属于V的正闭包,可以非终结符,可以终结符,不可以空,即使一个符号也可以是短语)
若U可直接推导出u,则u是句型w相对于U的简单短语(又称直接短语)。
定义:任一句型的最左简单短语称为该句型的句柄,句柄在自底向上的语法分析中很重要。
再次解释:
短语:将某句型转化为抽象语法树后,每一个有后继结点的结点的叶子结点组成的符号串,有意义的最小单位(可由识别符号推出的非终结符号推出);
简单短语:转化为抽象树后,子结点中不能再推出其他式子的结点的叶节点组成的符号串;
句柄:最左的简单短语。
短语、简单短语都是相对于句型而言的,一个矩形可能有多个短语、简单短语,但句柄只能有一个。
2.4 语法树和二义性文法
树:除了根节点以外,每个叶节点只能有一个直接前驱;n个直接后继
语法树:句子结构的图示表示法,是一种有向图,由结点和有向边组成。
一个结点就是一个符号,根节点是识别符号(最开始的),中间结点是非终结符,叶节点可以是终结符或非终结符,有向边便是这结点间的派生关系,一般有向边默认从根节点指向子节点。
子树:以语法树中的某个结点为根节点到底生成的子语法树。
子树和短语:某子树的末端结点按自左向右顺序为句型中的符号串,则该符号串为该句型的相对于该子树根的短语(因为是由这子树根推出的)。
句型的推导和语法树的生成
给定一个G[Z],句型w。可建立推导序列:Z可根据语法G推导出w时,便可建立语法树:以Z为树根结点,每步推导生成语法树的一枝。
注:文法能产生的句子,可以用不同的推导原则推导。语法树的生成规律不同,但最终生成的语法树形状相同,不是所有文法都有此性质。
语法树的推导有三种,一般推导:按深度进行推导;最左推导:首先推导最左侧的结点到终结符号;最右推导:先最右。
1.由推导构造语法树:
从识别符号开始,自右向左建立推导序列→由根结点开始,自上而下建立语法树。
2.由语法树构造推导
首先自下而上的修剪子树的末端节点,直到把整棵树剪掉,每剪一次对应一次规约:从句型开始,自左向右的逐步进行规约,便可建立推导序列,每一步都是归约当前句型的句柄。
定义:对句型中的句柄进行的规约称为规范规约(最左归约)。
定义:通过规范推导或规范规约所得到的句型称为规范句型
2.4.2 文法的二义性
定义:若对于一个文法的某一句子存在两颗不同的语法树,则该文法是二义性文法,否则是无二义性文法。
例:
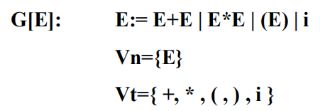
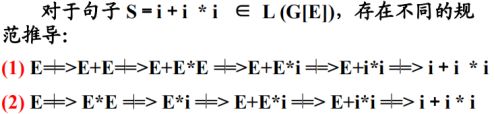
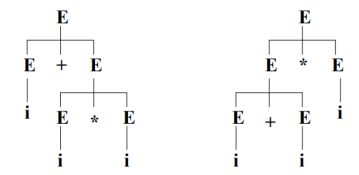
他们的语法树也不同:
定义:若一个文法的某句子存在两个不同的规范推导,则该文法是二义性的。
除了以上的自顶向下判断文法二义性,还可以自底向上来看。例如在上例中:E+E*i是i+i*i通过两步规范规约得到的,但对于同一个句型E+E*i,他有两个不同的句柄(对应两棵不同的语法树:i和E+E)。因此语法的二义性意味着句型的句柄不唯一。
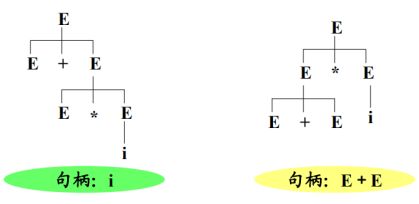
定义:若一个文法的某规范句型的句柄不唯一(有两个不用的规范归约),则该文法是二义性的。
编译时二义性会产生不确定性,而文法的二义性是不可判定的,所以无法在一个规定步数内判断一个文法是否有二义性。解决方法是提出限制条件,称为无二义性的充分条件,满足时便可判断某文法是无二义性的。
根据这个原则便可用两种方法解决:
1.根据条件修改编译算法:例如规定运算符的优先级来避免文法的二义性,不同优先级先看高的,同样优先级规定方向,这样在推导时就统一了。
2.根据条件直接修改文法:修改文法的规则后,直接限制归约的顺序。
2.5 句子的分析
当给定一个符号串S属于Vt的闭包,所要做的分析就是判断符号串S是否属于语法对应的语言。
2.6 有关文法的实用限制
在一个文法中,不能出现一些不应有的规则。
有害规则:例如有害规则:U::=U,这会引起二义性。
多余规则:
(1)推导文法的句子中,用不到的规则(该规则的左部非终结符不会出现在任何句型中)
(2)在推导句子的过程中,一旦使用了该规则,将推不出任何终结符号串的规则(该规则中含有推不出任何终结符号串的非终结符)。例如:当关于U的规则有且仅有U::=xUy,那就是多余的,因为无法推出终结符号串。
压缩文法:文法中没有有害规则或多余规则。
检查是否存在多余规则:需要检查文法中每一条规则左部的每个非终结符号U是否满足下述两个条件:
1.对所有的识别符号之外的非终结符号,这个非终结符号必须出现在某个句型中(右侧)
2.对所有的非终结符号,他必须能推导出终结符号串(终结符号组成的)
2.7 文法的其他表示法
1.扩充的BNF表示(Backus Normal Form)
BNF的元符号:<,>,::=,|
扩充的:<,>,::=,|,{,},[,],(,)
{}:右侧上m,下n,其中包含一个t,表示这个符号串t可以重复n到m次,mn都可省略,都省略后表示重复0到任意多次。内部也可以用|表示或
[]:表示内部的符号串可有可无,等于花括号包裹着符号串m是1,n是0
():提取因子的符号,例如xy|xm|xn,可以写成x(y|m|n)
2.语法图(图形化)
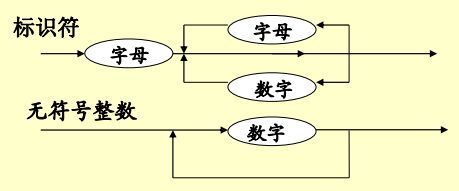
2.8 文法和语言分类
形式语言:用文法和自动机所描述的没有语义的语言
语言定义:![]()
文法定义:所有文法都可定义为一个四元组,即Vn,Vt,P,Z。
文法和语言分类:0型、1型、2型、3型,他们的去呗在于对产生式施加不同的限制。
0型:
规则P:u::=v,u属于V+需要有非终结符,v属于V*
L0,被称为短语结构文法,左部和右部都是符号串,左侧是至少包含一个Vn的符号串,右部为符号串(可为空),可以用图灵机接受。
1型:
规则P:xUy::=xuy,其中U属于Vn,x、y、u都属于V*
L1,这种语法规则被称为上下文敏感或上下文有关,也即只有在x、y这样的上下文中才能把U改写为u,可由一种线性界限的图灵自动机接受。
2型:
规则P:U::=u,其中U属于Vn,u属于V*
L2,称为上下文无关文法,即把U改写为u时不必考虑上下文,和BNF表示等价,可以由下推自动机接受。
3型:
规则P:U::=T或wT;U、w属于Vn,T是Vt。
L3,称为正则文法、正则语言、正则集合,注意左右线性不能同时出现,可以由有穷自动机接受。
根据描述:L3属于L2属于L1属于L0,范围更大的文法可以产生子文法,;例如2型文法可以产生L2型文法,L3型文法,不能产生L1型文法。
四种文法类型的关系及判断方法:
主要区别在于规定产生式的左边和右边的字符的组成规则不同。明确四种文法从0型到3型,其规则和约定越来越多,限制条件也越来越多,所以判断时应该先从最复杂的3型开始。
3型:(多的限制:右边最多两个字符,且只能有一种线性)
左边只有一个非终结符
右边最多有两个字符,两个时左非终结右终结,一个时必须终结(左非终结右终结是左线性的,左终结右非终结是右线性)
左右线性不能同时出现。
2型:(多的限制:左边需要只有一个非终结符)
左边只有一个非终结符
右边有若干个终结符和非终结符
1型:(多的限制:左边需要有非终结符)
左边至少需要含有一个非终结符
右边有若干个终结符和非终结符
左边推导右边时变化的部分左右两边内容不能变,变化后不能为空
0型:
左侧的符号串至少有一个非终结符
右侧随意
即只要能描述出来,就属于0型文法
习题内知识
语言的语法是用来形成一个合法程序的一组规则,这些规则的一部分是词法规则,另一部分是语法规则(又称产生规则)。
名字和标识符:名字都是由标识符组成的,标识符在不同语言中的规范不一样。他们在形式上难以区分,标识符是一个没有意义的字符串,名字则是有明确的意义和属性,且名字可看成是代表一个抽象的存储单元。
一个语言可由多个文法推导出
而一个文法仅可推导出一个语言。语言对文法:一对多
对于不同类型的文法,他们的规则是对所有的产生式起作用的,所以只需要找出一个不符合规则的,那么他就不属于这个类型的文法
当问一个文法的语言是什么时,如果是人类可以理解的,例如无符号整数,一个0-5数字组成的字符串。如果无法如此表述,则需要用一个集合来表示,集合的元素就是根据文法的规则得出的所有句子。
非终结符号的<>只是为了区分所用,不是必要加的,可以用其他形式来区分,例如非终结符用大写字母,终结符号用小写。
一些比较容易出现的题型有:根据语言得出对应的文法,根据文法描述出语言,判断文法类型,后续更新后会给出一些技巧的展示