上篇文章 spark 源码分析之十六 -- Spark内存存储剖析 主要剖析了Spark 的内存存储。本篇文章主要剖析磁盘存储。
总述
磁盘存储相对比较简单,相关的类关系图如下:

我们先从依赖类 DiskBlockManager 剖析。
DiskBlockManager
文档说明如下:
Creates and maintains the logical mapping between logical blocks and physical on-disk locations.
One block is mapped to one file with a name given by its BlockId.
Block files are hashed among the directories listed in spark.local.dir (or in SPARK_LOCAL_DIRS, if it's set).
创建并维护逻辑block和block落地的物理文件的映射关系。一个逻辑block通过它的BlockId的name属性映射到具体的文件。
类结构
其类结构如下:

可以看出,这个类主要用于创建并维护逻辑block和block落地文件的映射关系。保存映射关系,有两个解决方案:一者是使用Map存储每一条具体的映射键值对,二者是指定映射函数像分区函数等等,给定的key通过映射函数映射到具体的value。
成员变量
成员变量如下:
subDirsPerLocalDir:这个变量表示本地文件下有几个文件,默认为64,根据参数 spark.diskStore.subDirectories 来调节。
subDirs:是一个二维数组表示本地目录和子目录名称的组合关系,即 ${本地目录1 ... 本地目录n}/${子目录1 ... 子目录64}
localDirs:表示block落地本地文件根目录,通过 createLocalDirs 方法获取,方法如下:

思路:它先调用调用Utils的 getConfiguredLocalDirs 方法,获取到配置的目录集合,然后map每一个父目录,调用Utils的createDirectory方法,在每一个子目录下创建一个 以blockmgr 为前缀的目录。其依赖方法 createDirectory 如下:
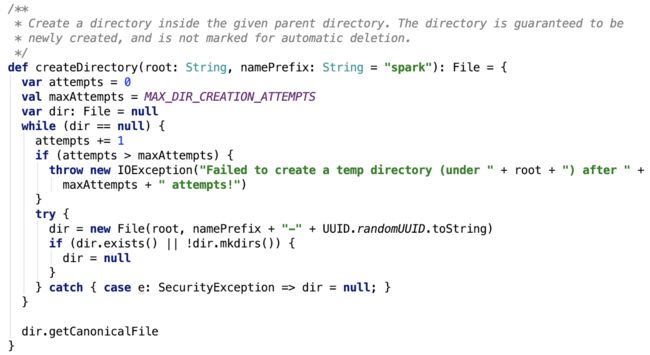
这个方法允许重试次数为10,目的是为了防止创建的目录跟已存在的目录重名。
getConfiguredLocalDirs 方法如下:

大多数生产情况下,都是使用yarn,我们直接看一下spark on yarn 环境下,目录到底在哪里。直接来看getYarnLocalDirs方法:

LOCAL_DIRS的定义是什么?
任务是跑在yarn 上的,下面就去定位一下hadoop yarn container的相关源码。
定位LOCAL_DIRS环境变量
在ContainerLaunch类的 sanitizeEnv 方法中,找到了如下语句:

addToMap 方法如下:

即,数据被添加到了envirment map变量和 nmVars set集合中了。
在ContainerLaunch 的 call 方法中调用了 sanitizeEnv 方法:
appDirs变量定义如下:

即每一个 appDir格式如下:${localDir}/usercache/${user}/appcache/${application-id}/
localDirs 定义如下:
![]()
dirHandler是一个 LocalDirsHandlerService 类型变量,这是一个服务,在其serviceInit方法中,实例化了 MonitoringTimerTask对象:
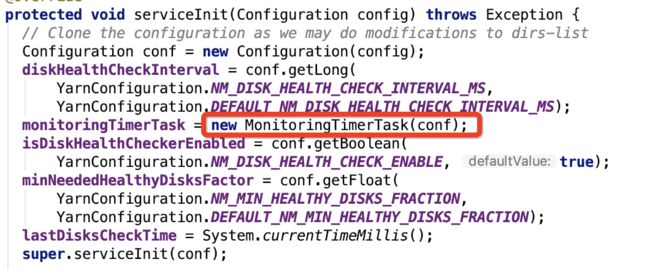
在 MonitoringTimerTask 构造方法中,发现了:

NM_LOCAL_DIRS 常量定义如下:
![]()
即:yarn.nodemanager.local-dirs 参数,该参数定义在yarn-default.xml下。
即localDir如下:
${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/${application-id}/
再结合createDirectory方法,磁盘存储的本地目录是:
${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/${application-id}/blockmgr-随机的uuid/
核心方法
根据文件内容创建File对象,如下:
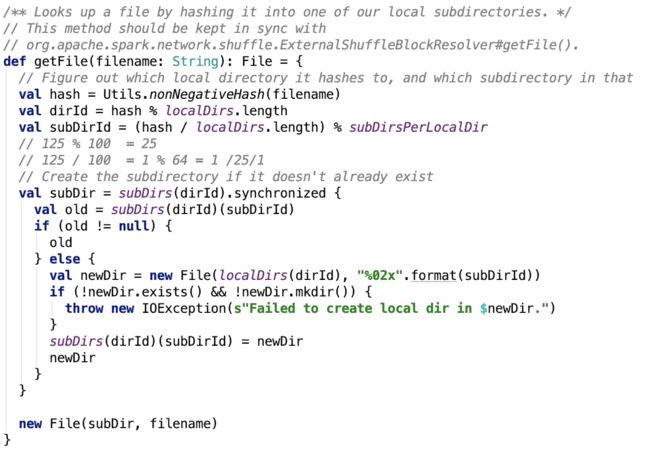
思路:先根据filename即blockId的name字段生成正的hashcode(abs(hashcode))
dirId 是指的第几个父目录(从0开始数),subDirId是指的父目录下的第几个子目录(从0开始数)。最后拼接父子目录为一个新的父目录subDir。
然后以subDir为父目录,创建File对象,并返回之。
跟getFile 方法相关的方法如下:
比较简单,不做过多说明。
创建一个临时Block,包括临时本地block 或 shuffle block,如下:

还有一个方法,是停止 DiskBlockManager之后的回调方法:

若deleteFilesOnStop 为 true,即DiskBlockManager停止时,是否需要清除本地存储的block文件。
在 BlockManager 中初始化DiskBlockManager时,deleteFilesOnStop 通过构造方法传入

总结:DiskBlockManager 是用来创建并维护逻辑block和落地后的block文件的映射关系的,它还负责创建用于shuffle或本地的临时文件。
下面看一下在DiskStore中可能会用到的类以及其相关类的说明。
CountingWritableChannel
它主要对sink做了包装,在写入sink的同时,还记录向sink写的数据的总量。源码如下:
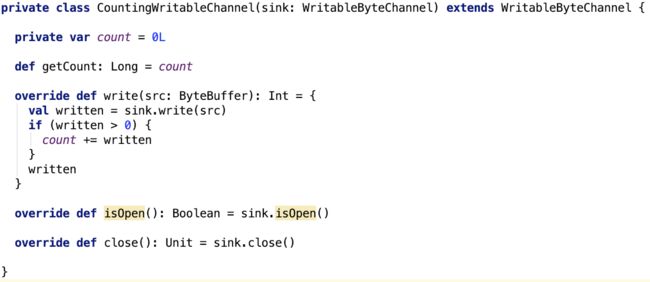
代码比较简单,不做过多说明。
ManagedBuffer
类说明如下:
This interface provides an immutable view for data in the form of bytes.
The implementation should specify how the data is provided:
- FileSegmentManagedBuffer: data backed by part of a file
- NioManagedBuffer: data backed by a NIO ByteBuffer
- NettyManagedBuffer: data backed by a Netty ByteBuf
The concrete buffer implementation might be managed outside the JVM garbage collector.
For example, in the case of NettyManagedBuffer, the buffers are reference counted.
In that case, if the buffer is going to be passed around to a different thread, retain/release should be called.
类结构如下:

EncryptedManagedBuffer
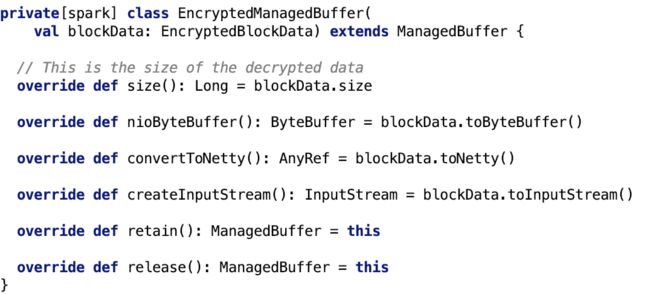
它是一个适配器,它将几乎所以转换的请求委托给了 blockData,下面来看一下这个类相关的剖析。
首先先看一下它的父类 -- BlockData
BlockData
接口说明如下:
它是一个接口,它定义了存储方式以及如何提供不同的方式来读去底层的block 数据。
定义方法如下:

方法说明如下:
toInputStream用于返回用于读取该文件的输入流。
toNetty用于返回netty对block数据的包装类,方便netty包来读取数据。
toChunkedByteBuffer用于将block包装成ChunkedByteBuffer。
toByteBuffer 用于将block数据转换为内存中直接读取的 ByteBuffer 对象。
当对该block的操作执行完毕后,需要调用dispose来做后续的收尾工作。
size表示block文件的大小。
它有三个子类:DiskBlockData、EncryptedBlockData和ByteBufferBlockData。
即block的三种存在形式:磁盘、加密后的block和内存中的ByteBuffer
分别介绍如下:
DiskBlockData
该类主要用于将磁盘中的block文件转换为指定的流或对象。
先来看其简单的方法实现:
构造方法:

相关字段说明如下:
minMemoryMapBytes表示 磁盘block映射到内存块中最小大小,默认为2MB,可以通过 spark.storage.memoryMapThreshold 进行调整。
maxMemoryMapBytes表示 磁盘block映射到内存块中最大大小,默认为(Integer.MAX_VALUE - 15)B,可以通过 spark.storage.memoryMapLimitForTests 进行调整。
对应源码如下:
![]()
比较简单的方法如下:

size方法直接返回block文件的大小。
dispose空实现。
open是一个私有方法,主要用于获取读取该block文件的FileChannel对象。
toByteBuffer方法实现如下:

Utils的tryWithResource方法如下,它先执行createResource方法,然后执行Function对象的apply方法,最终释放资源,思路就是 创建资源 --使用资源-- 释放资源三步曲:

即先获取读取block文件的FileChannel对象,若blockSize 小于 最小的内存映射字节大小,则将channel的数据读取到buffer中,返回的是HeapByteBuffer对象,即数据被写入到了堆里,即它是non-direct buffer,相当于数据被读取到中间临时内存中,否则使用FileChannelImpl的map方法返回 MappedByteBuffer 对象。
MappedByteBuffer文档说明如下:
A direct byte buffer whose content is a memory-mapped region of a file.
Mapped byte buffers are created via the FileChannel.map method. This class extends the ByteBuffer class with operations that are specific to memory-mapped file regions.
A mapped byte buffer and the file mapping that it represents remain valid until the buffer itself is garbage-collected.
The content of a mapped byte buffer can change at any time, for example if the content of the corresponding region of the mapped file is changed by this program or another. Whether or not such changes occur, and when they occur, is operating-system dependent and therefore unspecified.
All or part of a mapped byte buffer may become inaccessible at any time, for example if the mapped file is truncated. An attempt to access an inaccessible region of a mapped byte buffer will not change the buffer's content and will cause an unspecified exception to be thrown either at the time of the access or at some later time. It is therefore strongly recommended that appropriate precautions be taken to avoid the manipulation of a mapped file by this program, or by a concurrently running program, except to read or write the file's content.
Mapped byte buffers otherwise behave no differently than ordinary direct byte buffers.
它是direct buffer,即直接从磁盘读数据,不经过中间临时内存,可以参照ByteBuffer的文档对Direct vs. non-direct buffers 的说明如下:
Direct vs. non-direct buffers
A byte buffer is either direct or non-direct. Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer's content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system's native I/O operations.
A direct byte buffer may be created by invoking the allocateDirect factory method of this class. The buffers returned by this method typically have somewhat higher allocation and deallocation costs than non-direct buffers. The contents of direct buffers may reside outside of the normal garbage-collected heap, and so their impact upon the memory footprint of an application might not be obvious. It is therefore recommended that direct buffers be allocated primarily for large, long-lived buffers that are subject to the underlying system's native I/O operations. In general it is best to allocate direct buffers only when they yield a measureable gain in program performance.
A direct byte buffer may also be created by mapping a region of a file directly into memory. An implementation of the Java platform may optionally support the creation of direct byte buffers from native code via JNI. If an instance of one of these kinds of buffers refers to an inaccessible region of memory then an attempt to access that region will not change the buffer's content and will cause an unspecified exception to be thrown either at the time of the access or at some later time.
Whether a byte buffer is direct or non-direct may be determined by invoking its isDirect method. This method is provided so that explicit buffer management can be done in performance-critical code.
toChunkedByteBuffer 方法如下:
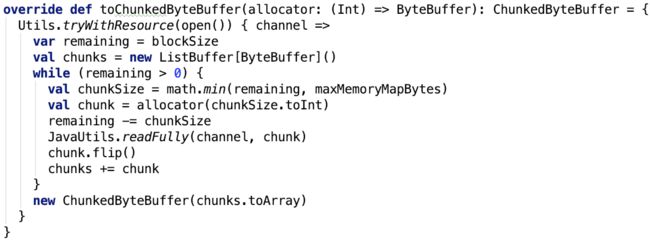
首先,ChunkedByteBuffer对象里包含的是数据分成多个小的chunk,而不是连续的数组。
先把文件读到内存中的 HeapByteBuffer 对象中即单个chunk,然后放入存放chunk的ListBuffer中,最终转换为Array存入到ChunkedByteBuffer 对象中。
toNetty实现如下:
![]()
DefaultFileRegion说明请继续向下看,先不做过多说明。
EncryptedBlockData
这个类主要是用于加密的block磁盘文件转换为特定的流或对象。
构造方法如下:
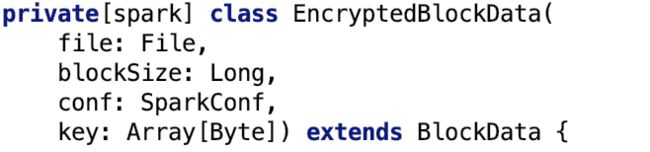
file指block文件,blockSize指block文件大小,key是用于加密的密钥。
先来看三个比较简单的方法:

open方法不再直接根据FileInputStream获取其 FileChannelImpl 对象了,而是获取 FileChannelImpl 之后,再调用了 CryptoStreamUtils 的 createReadableChannel 方法,如下:
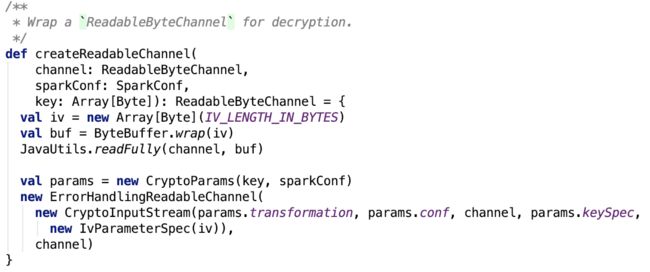
进一步将channel 对象封装为 CryptoInputStream 对象,对ErrorHandlingReadableChannel的读操作,实际上是读的 CryptoInputStream,这个流内部有一个根据key来初始化的加密器,这个加密器负责对数据的解密操作。
toByteBuffer方法如下:

思路:如果block数据大小在整数范围内,则直接将加密的block解密之后存放在内存中。
toChunkedByteBuffer方法除了解密操作外,跟DiskBlockData 中toChunkedByteBuffer方法无异,不做过多说明,代码如下:

toNetty 方法,源码如下:
![]()
ReadableChannelFileRegion类在下文介绍,先不做过多说明。
toInputStream方法,源码如下:
![]()
思路:这个就不能直接open方法返回的获取inputStream,因为 CryptoInputStream 是没有获取inputStream的接口的,Channels.newInputStream返回的是ChannelInputStream,ChannelInputStream对channel做了装饰。
ByteBufferBlockData
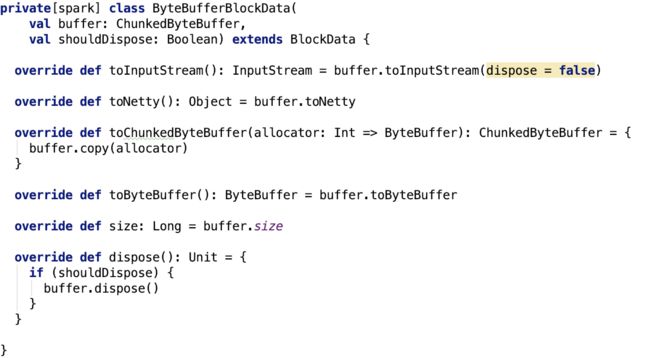
整体比较简单,主要来看一下dispose方法,ChunkedByteBuffer 方法的 dispose 如下:

即使用StorageUtils的dispose 方法去清理每一个chunk,StorageUtils的dispose 方法如下:

即获取它的cleaner,然后调用cleaner的clean方法。我们以 DirectByteBufferR 为例,做进一步说明:
在其构造方法中初始化Cleaner,如下:

base是调用unsafe类的静态方法allocateMemory分配指定大小内存后返回的内存地址,size是内存大小。
类声明:
![]()
没错它是一个虚引用,随时会被垃圾回收。
Cleaner的构造方法如下:

var1 是待清理的对象,var2 是执行清理任务的Runnable对象。
再看它的成员变量:

没错,它自己本身就是双向链表上的一个节点,也是双向链表。
其create 方法如下:


思路:创建cleanr并把它加入到双向链表中。
Cleaner的 clean方法如下:

它会先调用remove 方法,调用成功则执行内存清理任务,注意这里没有异步任务同步调用Runnable的run方法。
remove 方法如下:

思路:从双向链表中移除指定的cleaner。
Deallocator 类如下:

unsafe的allocateMemory方法使用了off-heap memory,这种方式的内存分配不是在堆里,不受GC的管理,使用Unsafe.freeMemory()来释放它。
先调用 unsafe释放内存,然后调用Bits的 unreserveMemory 方法:

至此,dispose 方法结束。
下面看一下,ReadableChannelFileRegion的继承关系:
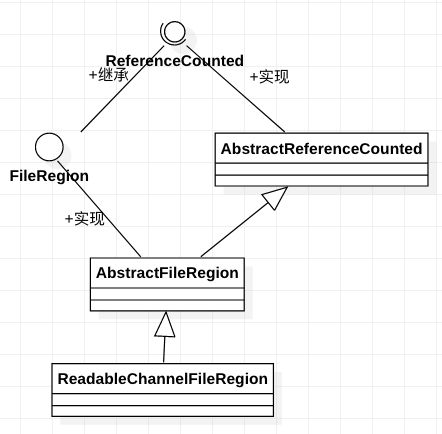
我们按继承关系来看类: ReferenceCounted --> FileRegion --> AbstractReferenceCounted --> AbstractFileRegion --> ReadableChannelFileRegion。
ReferenceCounted
类说明如下:
A reference-counted object that requires explicit deallocation. When a new ReferenceCounted is instantiated, it starts with the reference count of 1.
retain() increases the reference count, and release() decreases the reference count.
If the reference count is decreased to 0, the object will be deallocated explicitly,
and accessing the deallocated object will usually result in an access violation. If an object that implements ReferenceCounted is a container of other objects that implement ReferenceCounted,
the contained objects will also be released via release() when the container's reference count becomes 0.
这是netty包下的一个接口。
它是一个引用计数对象,需要显示调用deallocation。
ReferenceCounted对象实例化时,引用计数设为1,调用retain方法增加引用计数,release方法则释放引用计数。
如果引用计数减少至0,对象会被显示deallocation,访问已经deallocation的对象会造成访问问题。
如果一个对象实现了ReferenceCounted接口的容器包含了其他实现了ReferenceCounted接口的对象,当容器的引用减少为0时,被包含的对象也需要通过 release 方法释放之,即引用减1。

主要有三类核心方法:
retain:Increases the reference count by 1 or the specified increment.
touch:Records the current access location of this object for debugging purposes. If this object is determined to be leaked, the information recorded by this operation will be provided to you via ResourceLeakDetector. This method is a shortcut to touch(null).
release:Decreases the reference count by 1 and deallocates this object if the reference count reaches at 0. Returns true if and only if the reference count became 0 and this object has been deallocated
refCnt:Returns the reference count of this object. If 0, it means this object has been deallocated.
FileRegion
它也是netty下的一个包,FileRegion数据通过支持零拷贝的channel将数据传输到目标channel。
A region of a file that is sent via a Channel which supports zero-copy file transfer .
注意:文件零拷贝传输对JDK版本和操作系统是有要求的:
FileChannel.transferTo(long, long, WritableByteChannel) has at least four known bugs in the old versions of Sun JDK and perhaps its derived ones. Please upgrade your JDK to 1.6.0_18 or later version if you are going to use zero-copy file transfer.
If your operating system (or JDK / JRE) does not support zero-copy file transfer, sending a file with FileRegion might fail or yield worse performance. For example, sending a large file doesn't work well in Windows.
Not all transports support it
接口结构如下:
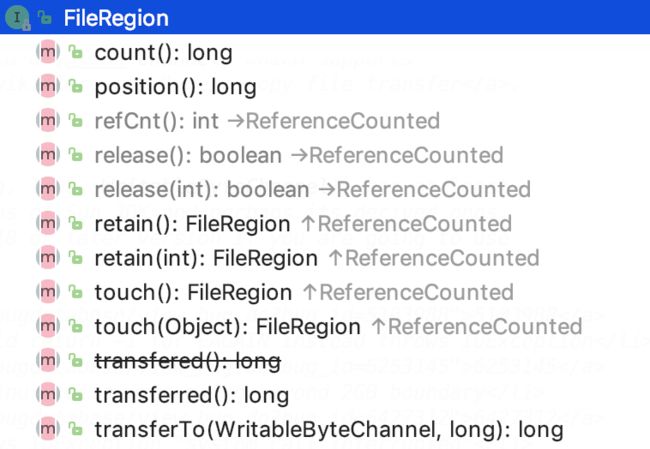
下面对新增方法的解释:
count:Returns the number of bytes to transfer.
position:Returns the offset in the file where the transfer began.
transferred:Returns the bytes which was transfered already.
transferTo:Transfers the content of this file region to the specified channel.
AbstractReferenceCounted
这个类是通过一个变量来记录引用的增加或减少情况。
类结构如下:

先来看成员变量:

refCnt就是内部记录引用数的一个volatile类型的变量,refCntUpdater是一个 AtomicIntegerFieldUpdater 类型常量,AtomicIntegerFieldUpdater 基于反射原子性更新某个类的 volatile 类型成员变量。
A reflection-based utility that enables atomic updates to designated volatile int fields of designated classes.
This class is designed for use in atomic data structures in which several fields of the same node are independently subject to atomic updates.
Note that the guarantees of the compareAndSet method in this class are weaker than in other atomic classes.
Because this class cannot ensure that all uses of the field are appropriate for purposes of atomic access,
it can guarantee atomicity only with respect to other invocations of compareAndSet and set on the same updater.
方法如下:
1. 设置或获取 refCnt 变量

2. 增加引用:
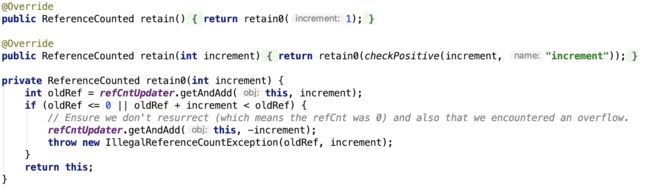
3. 减少引用:

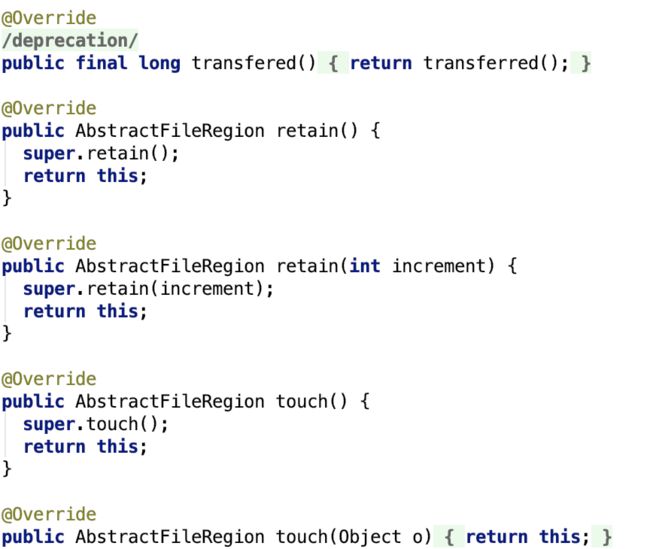
AbstractFileRegion
AbstractFileRegion 继承了AbstractReferenceCounted, 但他还是一个抽象类,只是实现了部分的功能,如下:
DefaultFileRegion
文档说明如下:
Default FileRegion implementation which transfer data from a FileChannel or File.
Be aware that the FileChannel will be automatically closed once refCnt() returns 0.
先来看一下它主要的成员变量:

f:是指要传输的源文件。
file:是指要传输的源FileChannel
position:传输开始的字节位置
count:总共需要传输的字节数量
transferred:指已经传输的字节数量
关键方法 transferTo 的源码如下:

思路:先计算出剩余需要传输的字节的总大小。然后从 position 的相对位置开始传输到指定的target sink。
注意:position是指相对于position最初开始位置的大小,绝对位置为 this.position + position。
其中,open 方法如下,它返回一个随机读取文件的 FileChannel 对象。

其deallocate 方法如下:

思路:直接关闭,取消成员变量对于FileChannel的引用,便于垃圾回收时可以回收FileChannel,然后关闭FileChannel即可。
总结:它通过 RandomeAccessFile 获取 可以支持随机访问 FileChannelImpl 的FileChannel,然后根据相对位置计算出绝对位置以及需要传输的字节总大小,最后将数据传输到target。
其引用计数的处理调用其父类 AbstractReferenceCounted的对应方法。
ReadableChannelFileRegion
其源码如下:

其内部的buffer 的大小时 64KB,_traferred 变量记录了已经传输的字节数量。ReadableByteChannel 是按顺序读的,所以pos参数没有用。
下面,重点对DiskStore做一下剖析。
DiskStore
它就是用来保存block 到磁盘的。
构造方法如下:

它有三个成员变量:
![]()
blockSizes 记录了每一个block 的blockId 和其大小的关系。可以通过get 方法获取指定blockId 的block大小。如下:
![]()
putBytes方法如下:

putBytes将数据写入到磁盘中;getBytes获取的是BlockData数据,注意现在只是返回文件的引用,文件的内容并没有返回,使得上文所讲的多种多样的BlockData转换操作直接对接FileChannel,即本地文件,可以充分发挥零拷贝等特性,数据传输效率会更高。
其中put 方法如下:

思路很简单,先根据diskManager获取到block在磁盘中的文件的抽象 -- File对象,然后获取到filechannel,调用回调函数将数据写入到本地block文件中,最后记录block和其block大小,最后关闭out channel。如果中途抛出异常,则格式化已写入的数据,确保数据的写入是原子化操作(要么全成功,要么全失败)。
put方法依赖的方法如下:
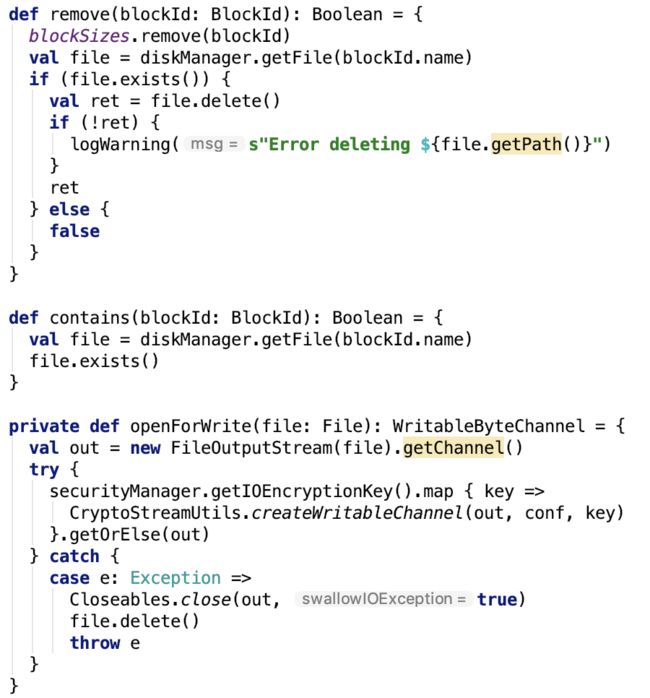
openForWrite方法,先获取filechannel,然后如果数据有加密,在创建加密的channel用来处理加密的数据
总结:本篇文章介绍了维护blockId和block物理文件的映射关系的DiskBlockManager;Hadoop yarn定位LOCAL_DIRS环境变量是如何定义的;定义了block的存储方式以及转换成流或channel或其他对象的BlockData接口以及它的三个具体的实现,顺便介绍了directByteBuffer内存清理机制--Cleaner以及相关类的解释;用作数据传输的DefaultFileRegion和ReadableChannelFileRegion类以及其相关类;最后介绍了磁盘存储里的重头戏--DiskStore,并重点介绍了其用于存储数据和删除数据的方法。
不足之处:本篇文章对磁盘IO中的nio以及netty中的相关类介绍的不是很详细,可以阅读相关文档做进一步理解。毕竟如何高效地和磁盘打交道也是比较重要的技能。后面有机会可能会对java的集合io多线程jdk部分的源码做一次彻底剖析,但那是后话了。目前打算先把spark中认为自己比较重要的梳理一遍。