仓库
- 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟 |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 0 |
| Development | 开发 | 880 | 2000 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 420 |
| · Design Spec | · 生成设计文档 | 10 | 40 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 320 | 720 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1790 | 3570 |
解题思路
- 收线分离出姓名和手机号码,引入python的re模块 (正则表达式),在查找号码是地址后面也可能会有号码,通过查找资料提取只含有手机号码的11为数字
- 地址划分
- 发现不不只是单纯的"省市区镇村号",还需要对"直辖市,自治区, 岛"在进行划分
- 附加题.........
资料
实现流程图

代码说明.展示出项目关键代码,并解释思路与注释说明。
import re
import json
#李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
dic1 = {}
res = []
#切姓名和电话号码
str1 = input()
name = re.search('(.*?,)', str1)
phone_number = re.search('\d+', str1)
#print(name , phone_number)
#name.group()
name = re.sub(',', '', name.group())
dic1['姓名'] = name
dic1['手机'] = phone_number.group()
#名字电话号码用‘’替换
str2 = re.sub('\.', '', str1)
str2 = re.sub('(\d{5}\d+)', '', str2)
str2 = re.sub('(.*,)', '', str2) 性能分析
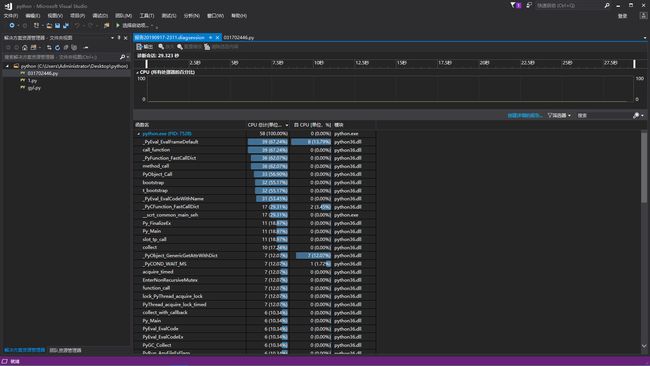
计算模块部分单元测试展示
李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
张三,福建福州闽13599622362侯县上街镇福州大学10#111.
王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
小陈,广东省东莞市凤岗13965231525镇凤平路13号.{"姓名": "李四", "手机": "13756899511", "地址": ["福建省", "福州市", "鼓楼区", "鼓西街道", "湖滨路", "110号", "湖滨大厦一层"]}
{"姓名": "张三", "手机": "13599622362", "地址": ["福建省", "福州市", "闽侯县", "上街镇", "", "", "福州大学10#111"]}
{"姓名": "王五", "手机": "18960221533", "地址": ["福建省", "福州市", "鼓楼区", "", "五一北路", "123号", "福州鼓楼医院"]}
{"姓名": "小陈", "手机": "13965231525", "地址": ["广东省", "东莞市", "", "凤岗镇", "凤平路", "13号", ""]} 总结
刚拿到题目一脸懵逼,学渣的我什么都不懂,查了很多资料 看了别人的博客才知道要用正则表达式来做 ,才开始入门python 才学到一点点皮毛 类,函数都不懂....
但是也感觉时间充实了很多不像以前一样 学习了很多 希望越来越好吧