前言
程序性能分析我相信是每个程序员都会遇到的问题,比如说一个程序的CPU为什么占用这么高?有没有优化的空间?又比如程序出现了内存泄漏如何排查等等。如果是C++程序会借助于Google pprof c++ profile,java程序会依赖于jstack等工具,幸运的是Golang语言本身就集成了性能分析工具pprof包,可以有效的分析程序CPU,MEM,Metux等指标。其中还可以通过第三方图形应用来更加直观的显示每个调用关系和指标占用情况。
演示环境
$ uname -a Darwin 18.6.0 Darwin Kernel Version 18.6.0: Thu Apr 25 23:16:27 PDT 2019; root:xnu-4903.261.4~2/RELEASE_X86_64 x86_64 $ go version go version go1.12.4 darwin/amd64
下面我直接用Golang pprof官方提供的示例来演示下CPU和MEM的分析方法,以及集成出图工具后的各种效果。
CPU
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file") func main() { flag.Parse() if *cpuprofile != "" { f, err := os.Create(*cpuprofile) if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() } ...
程序定义了一个cpuprofile的文件,用于保存程序的cpu prof信息。StartCPUProfile方法会将信息输出到cpuprofile文件中,程序退出前会调用StopCPUProfile方法,将缓存的信息一并(flush)刷到cpuprofile中。
$ go build havlak1.go $ ./havlak1 -cpuprofile havlak1.prof # of loops: 76000 (including 1 artificial root node) $ go tool pprof havlak1 havlak1.prof File: havlak1 Type: cpu Time: Jun 18, 2019 at 3:52pm (CST) Duration: 14.81s, Total samples = 19.20s (129.67%) Entering interactive mode (type "help" for commands, "o" for options) (pprof) top 10 Showing nodes accounting for 11090ms, 57.76% of 19200ms total Dropped 105 nodes (cum <= 96ms) Showing top 10 nodes out of 99 flat flat% sum% cum cum% 2250ms 11.72% 11.72% 2550ms 13.28% runtime.mapaccess1_fast64 1830ms 9.53% 21.25% 4760ms 24.79% runtime.scanobject 1470ms 7.66% 28.91% 9250ms 48.18% main.FindLoops 1040ms 5.42% 34.32% 1040ms 5.42% runtime.memmove 880ms 4.58% 38.91% 3420ms 17.81% runtime.mallocgc 840ms 4.38% 43.28% 2660ms 13.85% main.DFS 800ms 4.17% 47.45% 1990ms 10.36% runtime.mapassign_fast64ptr 790ms 4.11% 51.56% 1020ms 5.31% runtime.findObject 600ms 3.12% 54.69% 760ms 3.96% runtime.heapBitsSetType 590ms 3.07% 57.76% 600ms 3.12% runtime.pageIndexOf
输出top 10 表示的是显示最消耗cpu的10个函数调用。上述每列指标的含义为:
- flat 采样时,该函数正在运行的次数*采样频率(10ms),记得到估算的函数“运行时间”。不包含等待子函数返回的时间。
- flat% flat/总采样时间值,例如第一行的数据 2250ms/(19.2*1000)Total samples =11.72%。
- sum% 前面所有flat%的累加,所以第一行的sum%永远都是等于flat%,第二行21.25%=11.72%+9.53%。
- cum 采样时,该函数出现在调用堆栈的采样时间。包含等待子函数返回的时间。
- cum% cum/总采样时间值,例如第一行的数据 2550ms/(19.2*1000)Total samples =13.28%。
上述的文字比例显示说实话没有看出具体的调用关系,有没有更好的图形界面呢,答案是用web命令,前提是已经安装了图像处理软件graphviz,否则会报错:
(pprof) web Failed to execute dot. Is Graphviz installed? Error: exec: "dot": executable file not found in $PATH $ brew install graphviz (pprof) web
输入web命令后会自动唤起浏览器显示调用关系的图片:
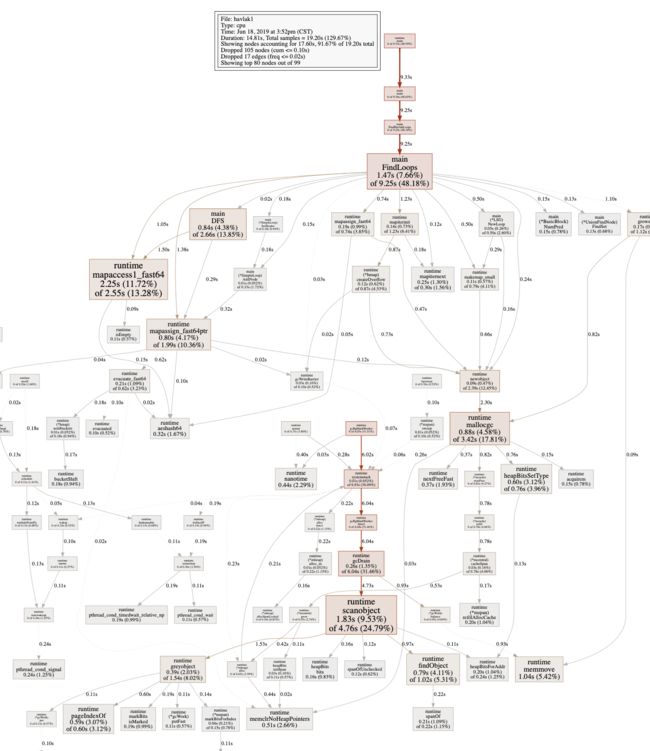
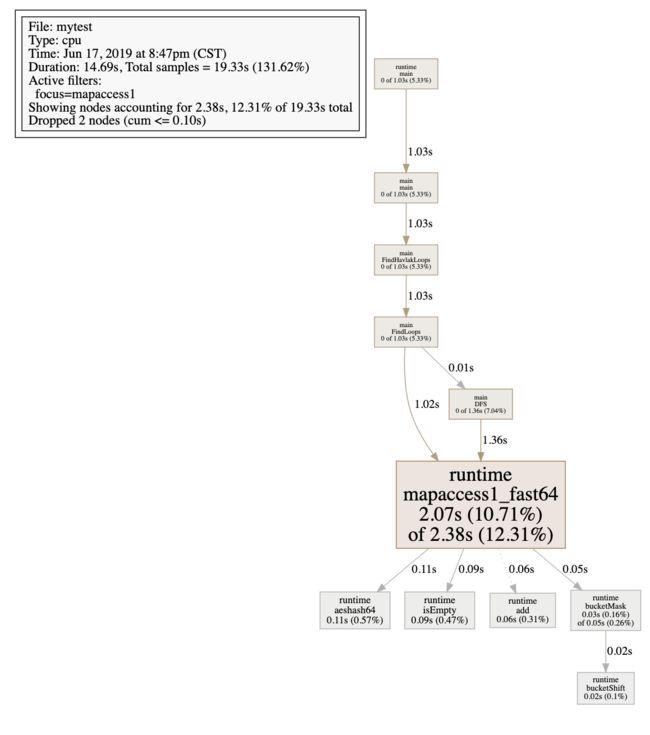
但是这样全盘的调用关系老实将也是有点乱,可以通过--nodefraction=0.1把占用低于10%的关系不显示,也可以可以通过web mapaccess1 来查看runtime mapaccess1_fast64的单条调用关系链,会更加的聚焦和清晰。
其实上面的图形还是不够直观,最直观的调用关系和占比图是火焰图,但是火焰图需要依赖第三方火焰图生成工具,不是golang pprof自带的,步骤下:
- 安装火焰图生成工具 go-torch go get github.com/uber/go-torch
- 安装火焰图生成脚本 FlameGraph 进入到go-torch的bin路径执行
git clone https://github.com/brendangregg/FlameGraph.git,cd FlameGraph && mv * ../
u$ go-torch havlak1 havlak1.prof INFO[17:38:11] Run pprof command: go tool pprof -raw -seconds 30 havlak1 havlak1.prof INFO[17:38:11] Writing svg to torch.svg
在执行命令的当前目录下会生成一个torch.svg的文件,用浏览器打开如下:
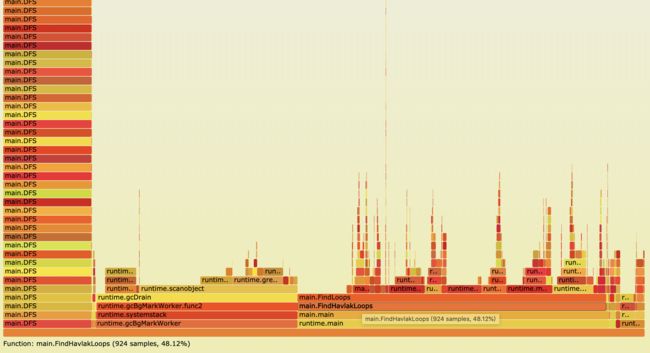
从底往上是一层层调用关系,长方格的长度表示占比。所以说调用关系和占比一目了然。
程序优化了DFS函数后的占用情况:
(pprof) top 5 Showing nodes accounting for 4410ms, 38.82% of 11360ms total Dropped 83 nodes (cum <= 56.80ms) Showing top 5 nodes out of 106 flat flat% sum% cum cum% 1230ms 10.83% 10.83% 3650ms 32.13% runtime.scanobject 950ms 8.36% 19.19% 5430ms 47.80% main.FindLoops 840ms 7.39% 26.58% 840ms 7.39% runtime.memmove 730ms 6.43% 33.01% 2680ms 23.59% runtime.mallocgc 660ms 5.81% 38.82% 810ms 7.13% runtime.findObject (pprof)
可以看出现在函数的主要消耗在内存的申请和回收上面(runtime.mallocgc)。为了找出为什么gc回收这么频繁,我们必须先找出究竟是哪里在频繁的申请内存。所以引入了下面的MEM章节。
MEM
var memprofile = flag.String("memprofile", "", "write memory profile to this file") ... FindHavlakLoops(cfgraph, lsgraph) if *memprofile != "" { f, err := os.Create(*memprofile) if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(f) f.Close() return }
分析运行的结果:
$ go tool pprof havlak3 havlak3.prof File: havlak3 Type: inuse_space Time: Jun 18, 2019 at 5:05pm (CST) Entering interactive mode (type "help" for commands, "o" for options) (pprof) top5 Showing nodes accounting for 34.51MB, 100% of 34.51MB total Showing top 5 nodes out of 13 flat flat% sum% cum cum% 18MB 52.17% 52.17% 18MB 52.17% main.NewBasicBlock 9.72MB 28.16% 80.32% 9.72MB 28.16% main.FindLoops 3MB 8.69% 89.02% 3MB 8.69% main.(*BasicBlock).AddOutEdge 2.29MB 6.64% 95.65% 20.29MB 58.80% main.(*CFG).CreateNode 1.50MB 4.35% 100% 1.50MB 4.35% main.(*BasicBlock).AddInEdge (pprof)
显示具体的函数内部内存占用情况:
(pprof) list CreateNode Total: 34.51MB ROUTINE ======================== main.(*CFG).CreateNode in /Users/haiweilu/saas/src/awesomeProject/test/havlak3.go 2.29MB 20.29MB (flat, cum) 58.80% of Total . . 94: } . . 95: if node != len(cfg.Blocks) { . . 96: println("oops", node, len(cfg.Blocks)) . . 97: panic("wtf") . . 98: } . 18MB 99: bblock := NewBasicBlock(node) 2.29MB 2.29MB 100: cfg.Blocks = append(cfg.Blocks, bblock) . . 101: . . 102: if len(cfg.Blocks) == 1 { . . 103: cfg.Start = bblock . . 104: } . . 105: (pprof) list FindLoops Total: 34.51MB ROUTINE ======================== main.FindLoops in /Users/haiweilu/saas/src/awesomeProject/test/havlak3.go 9.72MB 9.72MB (flat, cum) 28.16% of Total . . 263: return . . 264: } . . 265: . . 266: size := cfgraph.NumNodes() . . 267: 1.97MB 1.97MB 268: nonBackPreds := make([]map[int]bool, size) 5.77MB 5.77MB 269: backPreds := make([][]int, size) . . 270: 1.97MB 1.97MB 271: number := make([]int, size) . . 272: header := make([]int, size, size) . . 273: types := make([]int, size, size) . . 274: last := make([]int, size, size) . . 275: nodes := make([]*UnionFindNode, size, size) . . 276: (pprof)
可以看到程序又大量的临时变量的创建和销毁,导致了golang的gc机制频繁触发,从而导致CPU飙高。有gc机制的编程语言并不意味着可以忽略内存分配问题,这个问题的简单解决是保存一个全局的成员变量,避免内存的频繁申请和释放。
在线debug
package main import ( "net/http" _ "net/http/pprof" ) func main() { http.ListenAndServe("localhost:6060", nil) }
通过浏览器debug:
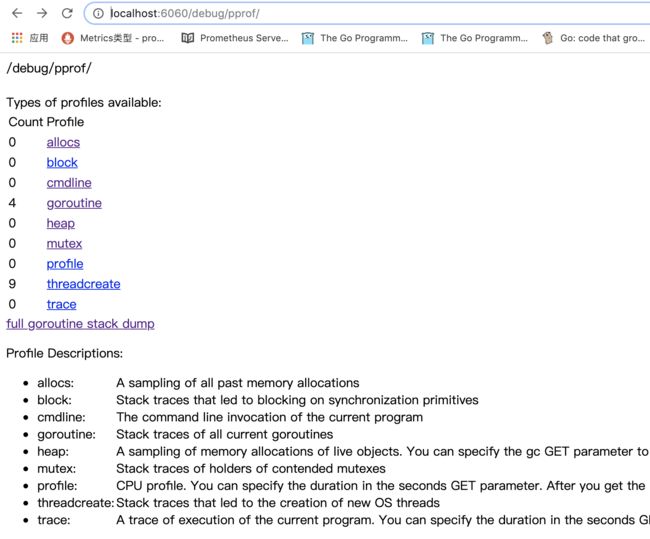
通过go tool debug:
go tool pprof http://localhost:6060/debug/pprof/profile # 30-second CPU profile go tool pprof http://localhost:6060/debug/pprof/heap # heap profile go tool pprof http://localhost:6060/debug/pprof/block # goroutine blocking profile
总结
本文讲解了go pprof包分析golang 程序 CPU和MEM的用法,其中包含文字界面,简单的web图形界面和火焰图,其实pprof还可以分析程序的其他指标,更多的技能解锁等待大家自行发现。
参考
https://blog.golang.org/profiling-go-programs